pandas 对数据帧DataFrame中数据的增删、补全及转换操作
1、创建数据帧
import pandas as pd df = pd.DataFrame([[1, 'A', '3%' ], [2, 'B'], [3, 'C', '5%']], index=['row_0', 'row_1', 'row_2'], columns=['col_0', 'col_1', 'col_2'])
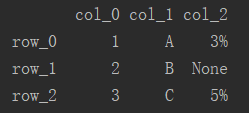
2、增加行、列
数据帧DataFrame的每一行都可看作是一个对象,每一列都是该对象的不同属性。每行都具有多维度的属性,因此每行都可以看作是一个小的DataFrame;而每列的数据类型都相同,因此每列都可以看作是一个Series。
2.1 增加行
创建新的DataFrame追加至原有数据帧的尾部,即可实现行的增加。通过df.append()实现行的追加。
# 创建新的数据帧 df_row3 = pd.DataFrame([[4, 'D', '9%']], index=['row_3'], columns=['col_0', 'col_1', 'col_2']) # 追加至原有数据帧尾部 df = df.append(df_row3)
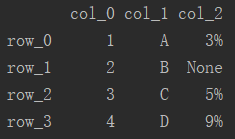
2.2 增加列
创建新的Series追加至原有数据帧的尾部,即可实现列的增加。
# 创建新系列作为新追加的列 df['col_4'] = pd.Series(['!', '@', '$', '&'], index=['row_0', 'row_1', 'row_2', 'row_3'])
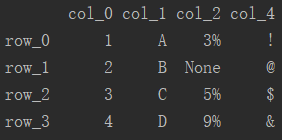
3、删除行、列
3.1 删除行
通过向df.drop()中传入行索引实现对行的删除。
# 删除最后一行 df = df.drop('row_3')
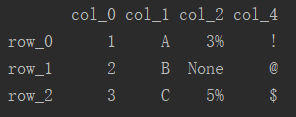
3.2 删除列
通过del 或df.pop() 删除索引值对应的列。
# del df['col_4'],删除最后一列,与下句代码等价 df.pop('col_4')
注意:df.pop()实现了对df的删除操作,其返回值是被删除的列,而不是新的df。

4、数据补全
可以看出,row_1行,col_2列对应位置的元素为空,在实际计算过程中,需对空数据进行补全。可通过df.fillna()对df的空数据进行补全,这里以补0为例。
# df.fillna(0, inplace=True),就地补0,与下句代码等价 df = df.fillna(0)
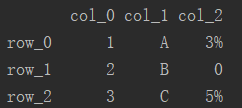
5、元素转换
可以看出,在col_2列中的‘3%’及‘5%’均为有效的数值数据,但其类型均为‘str’,不能直接参与数学运算。需遍历df,找出其在df中的位置,将其替换为float型数据。
for i in range(len(df.index)): for j in range(len(df.columns)): # df中元素各种类型都有,为了方便检测其中是否含有‘%’,将其统一转换为‘str’型 if '%' in str(df.iat[i, j]): df.iat[i, j] = float(df.iat[i, j].replace('%', '')) / 100

原创:秋沐霖
博客主页:https://www.cnblogs.com/HL-space/
欢迎转载,转载请注明出处。
出错之处,敬请交流、雅正!
创作不易,您的 " 推荐 " 和 " 关注 " ,是给我最大的鼓励!
博客主页:https://www.cnblogs.com/HL-space/
欢迎转载,转载请注明出处。
出错之处,敬请交流、雅正!
创作不易,您的 " 推荐 " 和 " 关注 " ,是给我最大的鼓励!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号