基于图像识别的表格数据提取系统
一、前言
1.1 项目需求
由于公司业务需要,须对从特定网站爬取下来的表格图片进行识别,将其中的数据提取出来,随后写入csv文件。表格图片形式统一,如下所示。

img 待识别图片
1.2 思路分析
直接识别整个图片显然是不太可能的。很自然地想到,可以将每个单元格从原图中分割出来后,逐个进行识别。因此整个任务就可以分为图片分割和内容识别两部分。关于图片分割,要想分割出每个单元格,就必须获取表格中每条横线的纵坐标和每条竖线的横坐标(图像学中图片的坐标原点在图片的左上角,向右为x轴正方向,向下为y轴正方向,以每个像素点为单位长度)。至于内容识别,经查阅资料后,决定使用Tesseract-OCR(开源的图像文本识别工具,依赖Java环境)。
1.3 实现环境
python3.6,所需的python第三方库有:pillow,opencv,numpy,csv,pytesseract。由于pytesseract依赖Java环境,因此需要安装JDK。
二、项目流程
2.1 图像预处理
要想将图片分割,就必须从图片中检测出组成表格的每条横线和竖线。通过观察图片可以发现,图片中共有3种颜色:白色的背景和字体,红色的背景和字体,黑色的字体和分割线。表格的分割线是黑色的连贯线条,要想提取出分割线,就必须同时滤除白色和红色内容的干扰。通过查阅RGB颜色表可知,黑色RGB三通道的值均为0,白色RGB三通道的值均为255,图片中深红色R通道值约为220,G、B通道值分别约为23和13。因此可以将原图进行通道分离,取其红色通道进行后续操作。opencv中的split()函数可以实现对图片的通道分离。
img_R = cv2.split(img)[2] #opencv中三通道排列顺序为BGR

img_R 红色通道图
分离出红色通道图之后,就可以将红色近似视为白色,选用合适的阈值对红色通道图进行二值化。为了方便后续寻线,可以将原来白色、红色的背景部分转黑,而黑线转白。opencv中的threshold()函数可以同时实现图像二值化和颜色反转。
ret, img_bin = cv2.threshold(img_R, 100, 255, cv.THRESH_BINARY_INV) #二值化阈值选为100,大于100的置0,小于100的置255

img_bin 红色通道图二值化后反转
使用不同的核对对二值化后的图像进行开运算(先腐蚀后膨胀),分别检测出二值图像中的横线和竖线。opencv中的morphologyEx()函数可以用自定义的核对图像进行开、闭运算。根据应用场景不同,可灵活调整核的形状和大小。
kernel_row = np.ones((1, 9)) # 自定义检测横线的核 img_open_row = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, kernel_row) # 开运算检测横线

img_open_row 检测出的横线
kernel_col = np.ones((9, 1)) # 自定义检测竖线的核 img_open_col = cv2.morphologyEx(img_bin, cv2.MORPH_OPEN, kernel_col) # 开运算检测竖线

img_open_col 检测出的竖线
检测出横线和竖线后,可以对两张图片分别使用霍夫寻线,获得每条线两端点的坐标。但在实际操作过程中,发现寻竖线时效果总是不好,经测试后发现由于图片高度较低,竖线普遍很短,不易寻找。因此可以通过resize()将img_open_col的高度拔高后,再进行霍夫寻线,效果显著。
#图片高度较低,为了方便霍夫寻纵线,将图片的高度拉高5倍 img_open_col = cv2.resize(img_open_col, (800, 5 * img_h))
2.2 图片分割
事实上经过开运算后的img_open_col和img_open_row中已经清晰地呈现出来所有组成表格的横线和纵线,但要想进一步分割表格,只找到线是不够的,还必须获取线在图片中的位置。霍夫寻线可以帮助我们完成这一操作,将img_open_col和img_open_row作为参数传递给从cv2.HoughLinesP(),可返回每条线段两端点的坐标(x1, y1, x2, y2)。
lines_col = cv2.HoughLinesP(img_open_col, 1, np.pi / 180, 100, minLineLength=int(0.52 * 5 * img_h), maxLineGap=5)
通过打印输出lines_col的参数信息:
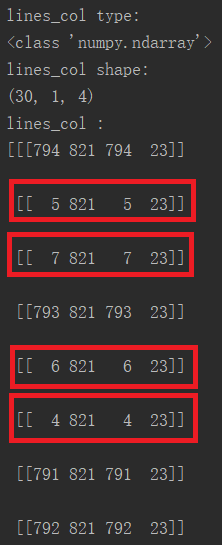
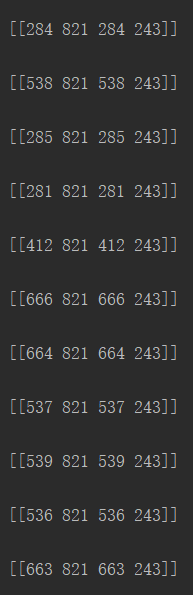
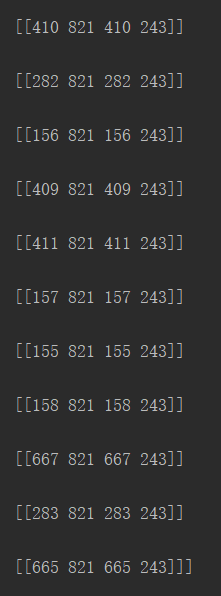
可以看出,lines_col是shape为30X1X4的numpy.adarray。事实上竖线只有7条,但通过霍夫寻线却寻出了30条,这是因为处理后的线条较粗,每条线都被当作了多条。就第一条线而言,就被当作了四条线,即上图中红色框出的部分。它们的纵坐标都相同,横坐标相差极小,可以通过后续处理将其归为一条。在表格分割中,竖线端点坐标信息中,只有横坐标为有效信息,因此后续处理中只针对其横坐标即可。横线亦然,只处理其纵坐标即可。
就lines_col而言,其处理的思路是:取lines_x = lines_col[: ; : ; 0] ,即取出30条线段的横坐标,随后排序并将其转换为list,对整个list进行遍历,将差异较小的几个元素用其中一个元素值代替,如4、5、6、7均替换为4,即4、5、6、7变为4、4、4、4。随后将整个list转换为set,即进行去重,4、4、4、4变为一个4。再排序后即可得到7条竖线的横坐标。
lines_x = np.sort(lines_col[:,:,0], axis=None) list_x = list(lines_x) #合并距离相近的点 for i in range(len(list_x) - 1): if (list_x[i] - list_x[i + 1]) ** 2 <= (img_w/12)**2: list_x[i + 1] = list_x[i] list_x = list(set(list_x))#去重 list_x.sort()#排序

同上操作,可得到5条横线的纵坐标。

有了这12个关键数据,即可定位出每个单元格的位置。图片分割任务到此圆满完成,接下来就是内容识别了。
2.3 内容识别
识别部分采用的是开源的Tesseract-OCR。将需要识别的单元格分离出来后,由于原图的清晰度不够,对识别造成了一定的困难。后来将需识别的单元格图片放大后腐蚀,提高请字体清晰度。处理之后,字体样式发生了一定程度的变形,为了不影响后续识别,将每个分离出来并经处理后的单元格保存下来,制作了一个较小的数据集,对pytesseract进行训练,获得一个新的识别模型,命名为ftnum,并用该模型进行后续的识别工作。
for i in range(2): for j in range(5): #截取对应的区域 area = img_gray[(y_val[i+2]+4) :y_val[i+3], (x_val[j+1]+10) :(x_val[j+2]-10)] #二值化 area_ret, area_bin = cv2.threshold(area, 190, 255, cv2.THRESH_BINARY) #放大三倍 area_bin = cv2.resize(area_bin, (0,0), fx=3, fy=3) #腐蚀两次,加粗字体 area_bin = cv2.erode(area_bin, kernel_small, iterations=2) #送入OCR识别 per_text = pytesseract.image_to_string(Image.fromarray(area_bin), lang="ftnum", config="--psm 7")
分割处理后的单元格样式如下(area_bin):



识别效果:

三、后记
后来在对图像的批处理过程中,发现对某些图片的识别效果并不好,之后在图像刚读出来后就用一个resize(),将所有要处理的图像规范到同一个大小,识别效果显著改善。目前在30张图片上做过测试,识别准确率为100%。
四、源码分享及参考文献
4.1 源码
源码含图片爬虫及写入csv文件过程,其中爬虫是公司里一位小哥哥写的,比心,感谢!


1 # Created by 秋沐霖 on 2019/3/8. 2 from PIL import Image 3 import pytesseract #OCR识别 4 import cv2 as cv 5 import numpy as np 6 import csv 7 import time 8 import os 9 import requests 10 from bs4 import BeautifulSoup 11 from openpyxl.compat import range 12 13 # 获取最新图片 14 def getImage(): 15 # 当天是否发布报告的标值 16 flag = 0 17 headers = { 18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER', 19 } 20 21 # 收益率曲线主页 22 YieldCurveUrl='https://www.chinaratings.com.cn/AbsPrice/YieldCurve/' 23 24 # 请求并解析网页 25 html = requests.get(YieldCurveUrl, headers=headers) 26 html=html.content.decode('UTF-8') 27 soup = BeautifulSoup(html, 'lxml') 28 # 获取今天日期 29 today=time.strftime('%Y-%m-%d', time.localtime(time.time())) 30 31 # 获取当前日期,作为图片的名字保存到本地 32 img_title=soup.select('body > div.main > div > div.ctr > div.recruit > ul > li > span')[0].text.split(':')[-1] 33 34 if img_title==today: 35 flag = 1 36 # print(img_title) 37 38 # 获取最新的曲线所在页面的链接 39 YieldCurveUrl='https://www.chinaratings.com.cn'+soup.select('body > div.main > div > div.ctr > div.recruit > ul > li > a')[0].get('href') 40 41 # 请求该链接,解析出该图片的下载链接img_url 42 html = requests.get(YieldCurveUrl, headers=headers) 43 soup = BeautifulSoup(html.text, 'lxml') 44 img_url ='https://www.chinaratings.com.cn'+ soup.select('body > div.main > div.ctr > div > div.newsmcont > p > img')[1].get('src') 45 46 # print(img_url) 47 rep = requests.get(img_url, headers=headers) 48 49 #将图片写到本地 50 with open(r'./img/'+img_title+'.png','wb')as f: 51 f.write(rep.content) 52 53 return img_title, flag 54 55 56 #图像预处理 57 def picProcess(): 58 img = cv.imread(file) 59 60 #为了方便后续操作,将图像统一大小 61 img = cv.resize(img, (800, 165)) 62 63 img_h = img.shape[0] 64 img_w = img.shape[1] 65 # 转为灰度图 66 img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) 67 68 #分离处红色通道 69 img_R = cv.split(img)[2] 70 # 红色通道图二值化,同时反转,即将原图中红色、白色变黑,黑色变白,便于后续操作 71 thr = 100 72 ret, img_bin = cv.threshold(img_R, thr, 255, cv.THRESH_BINARY_INV) 73 74 # 滤波器的长度设为9,是为了避免较粗线条的干扰 75 kernel_col = np.ones((9, 1)) 76 kernel_row = np.ones((1, 9)) 77 78 #开运算求横线和纵线 79 img_open_col = cv.morphologyEx(img_bin, cv.MORPH_OPEN, kernel_col) 80 img_open_row = cv.morphologyEx(img_bin, cv.MORPH_OPEN, kernel_row) 81 #图片高度较低,为了方便霍夫寻纵线,将图片的高度拉高5倍 82 img_open_col = cv.resize(img_open_col, (800, 5 * img_h)) 83 84 #霍夫寻线 85 lines_col = cv.HoughLinesP(img_open_col, 1, np.pi / 180, 100, minLineLength=int(0.52 * 5 * img_h), 86 maxLineGap=5) 87 lines_row = cv.HoughLinesP(img_open_row, 1, np.pi / 180, 100, minLineLength=int(0.75 * img_w), 88 maxLineGap=5) 89 90 return img_w,img_h, img_gray, lines_col, lines_row 91 92 #求交点坐标 93 def getCoord(lines, flag): 94 #求竖线的横坐标 95 if flag == "col": 96 lines_x = np.sort(lines[:,:,0], axis=None) 97 list_x = list(lines_x) 98 99 #合并距离相近的点 100 for i in range(len(list_x) - 1): 101 if (list_x[i] - list_x[i + 1]) ** 2 <= (img_w/12)**2: 102 list_x[i + 1] = list_x[i] 103 104 list_x = list(set(list_x))#去重 105 list_x.sort()#排序 106 return list_x 107 108 #求横线的纵坐标 109 elif flag == "row": 110 lines_y = np.sort(lines[:,:,1], axis=None) 111 list_y = list(lines_y) 112 113 # 合并距离相近的点 114 for i in range(len(list_y) - 1): 115 if (list_y[i] - list_y[i + 1]) ** 2 <= (img_h/8)**2: 116 list_y[i + 1] = list_y[i] 117 118 list_y = list(set(list_y)) # 去重 119 list_y.sort() # 排序 120 return list_y 121 122 #识别日期及数值 123 def recognize(): 124 kernel_small = np.ones((3, 3)) 125 text = ['关键期限点曲线值'] 126 127 #日期,为报告发布日期 128 per_text = png_name 129 text.append(per_text) 130 131 add_list = ['360','1080','1800','3600','10800','ABS','RMBS'] 132 text = text + add_list 133 134 #数值,放大三倍,腐蚀两次,效果较好 135 for i in range(2): 136 for j in range(5): 137 #截取对应的区域 138 area = img_gray[(y_val[i+2]+4) :y_val[i+3], (x_val[j+1]+10) :(x_val[j+2]-10)] 139 #二值化 140 area_ret, area_bin = cv.threshold(area, 190, 255, cv.THRESH_BINARY) 141 #放大三倍 142 area_bin = cv.resize(area_bin, (0,0), fx=3, fy=3) 143 # 腐蚀两次,加粗字体 144 area_bin = cv.erode(area_bin, kernel_small, iterations=2) 145 146 #送入OCR识别 147 per_text = pytesseract.image_to_string(Image.fromarray(area_bin), lang="ftnum", config="--psm 7") 148 149 #易错修正 150 if ' ' in per_text: 151 per_text = ''.join(per_text.split()) #去多余空格 152 if '..' in per_text: 153 per_text.replace('..', '.') 154 155 text.append(per_text) 156 157 #整理顺序,方便写入表格 158 index = text[8] 159 text[8:13] = text[9:14] 160 text[13] = index 161 162 return text 163 164 #写入csv 165 def writeCsv(path): 166 with open(path,"w", newline='') as file: 167 writer = csv.writer(file, dialect='excel') 168 169 #写表头 170 header = ["CurveName", "RateType", "ReportingDate", "TermBase", "Term", "Rate"] 171 writer.writerows([header]) 172 173 #写ABS数据 174 for i in range(2,7): 175 writer.writerows([["ABS", "SpotRate", text[1], "D", text[i], text[i+6] ]]) 176 #写RMBS数据 177 for j in range(2,7): 178 writer.writerows([["RMBS", "SpotRate", text[1], "D", text[j], text[j+12] ]]) 179 180 181 if __name__ == "__main__": 182 current_dir = os.getcwd() # 返回当前工作目录 183 files_dir = os.listdir(current_dir) # 返回指定的文件夹包含的文件或文件夹的名字的列表, 184 185 png_name, flag = getImage() 186 187 if flag == 1: 188 if "CSV存放文件夹" not in files_dir: 189 os.mkdir(current_dir + "\\CSV存放文件夹") 190 if "img" not in files_dir: 191 os.mkdir(current_dir + "\\img") 192 193 os.chdir(".\\img") # 跳进img文件夹 194 files = os.listdir(".") # 返回该文件夹下所有文件 195 for file in files: 196 if (os.path.splitext(file)[0] == png_name)and(os.path.splitext(file)[1] == ".png"): 197 198 #获取交点坐标 199 img_w, img_h, img_gray, lines_col, lines_row = picProcess() 200 x_val = getCoord(lines_col, flag="col") 201 y_val = getCoord(lines_row, flag="row") 202 203 #分割识别 204 text= recognize() 205 206 #写入csv文件 207 csv_path = current_dir+"\\CSV存放文件夹\\"+os.path.splitext(file)[0]+"_data.csv" 208 writeCsv(csv_path) 209 os.chdir(current_dir) 210 elif flag == 0: 211 print("今天未发布报告")
4.2 参考文献
思路启蒙:https://blog.csdn.net/huangwumanyan/article/details/82526873
霍夫寻线:https://blog.csdn.net/dcrmg/article/details/78880046
Tesseract-OCR的安装、训练及简单使用:https://www.cnblogs.com/cnlian/p/5765871.html
http://www.cnblogs.com/lizm166/p/8343872.html
https://www.cnblogs.com/wzben/p/5930538.html
csv文件操作:https://blog.csdn.net/lwgkzl/article/details/82147474
博客主页:https://www.cnblogs.com/HL-space/
欢迎转载,转载请注明出处。
出错之处,敬请交流、雅正!
创作不易,您的 " 推荐 " 和 " 关注 " ,是给我最大的鼓励!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号