
tensorFlow的linux基本操作笔记
本文使用的是linux版本的Anaconda环境
#创建名为 tensorflow的环境,设置python版本为3.5
conda create -n tensorflow python=3.5
#进入 tensorflow环境
source activate tensorflow
#安装一些安装包
conda install pandas matplotlib jupyter notebook scipy scikit-learn
conda install -c conda-forge tensorflow
tensorflow中的数据都是以tensor对象的形式存储的
tf.constant() 返回的 tensor 是一个常量 tensor,因为这个 tensor 的值不会变。
# 可以是0维 A = tf.constant(1234) # 可以是1维 B = tf.constant([123,456,789]) # 可以是2维 C = tf.constant([ [123,456,789], [222,333,444] ]) #可以是字符串 hello_constant = tf.constant('Hello World!')
tf.Session 创建了一个 sess 的 session 实例。然后 sess.run() 函数对 tensor 求值,并返回结果。
一个 "TensorFlow Session" 是用来运行图的环境。这个 session 负责分配 GPU(s) 和/或 CPU(s),包括远程计算机的运算。
with tf.Session() as sess:
output = sess.run(hello_constant)
此函数可以理解为形参,用于定义过程,在执行的时候再赋具体的值
tf.placeholder()用这个方法给传个类型
tf.placeholder(dtype, shape=None, name=None)
1 #给参数设置各种类型 2 x = tf.placeholder(tf.string) 3 y = tf.placeholder(tf.int32) 4 z = tf.placeholder(tf.float32)
给tensor对象进行传参数
1 with tf.Session() as sess: 2 output = sess.run(x, feed_dict={x: 'Test String', y: 123, z: 45.67})
注意:如果传入 feed_dict 的数据与 tensor 类型不符,就无法被正确处理,你会得到 “ValueError: invalid literal for...”。
类型转换
tf.cast(tf.constant(2.0), tf.int32) #将浮点数转化为整数 为了让特定运算能运行,有时会对类型进行转换。例如,你尝试下列代码,会报错:
tf.subtract(tf.constant(2.0),tf.constant(1)) # Fails with ValueError: Tensor conversion requested dtype float32 for Tensor with dtype int32:
这是因为常量 1 是整数,但是常量 2.0 是浮点数,subtract 需要它们的类型匹配。
在这种情况下,你可以确保数据都是同一类型,或者强制转换一个值为另一个类型。这里,我们可以把 2.0 转换成整数再相减,这样就能得出正确的结果:
tf.subtract(tf.cast(tf.constant(2.0), tf.int32), tf.constant(1)) # 1
运算函数
1 # 算术操作符:+ - * / % 2 tf.add(x, y, name=None) # 加法(支持 broadcasting) 3 tf.subtract(x, y, name=None) # 减法 4 tf.multiply(x, y, name=None) # 乘法 5 tf.divide(x, y, name=None) # 浮点除法, 返回浮点数(python3 除法) 6 tf.mod(x, y, name=None) # 取余
# 矩阵乘法(tensors of rank >= 2),在矩阵乘法中也可以设置是矩阵是否转置 tf.matmul(a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None) # 转置,可以通过指定 perm=[1, 0] 来进行轴变换 tf.transpose(a, perm=None, name='transpose')
TensorFlow 里的权重和偏差(变量)
训练神经网络的目的是更新权重和偏差来更好地预测目标。为了使用权重和偏差,你需要一个能修改的 Tensor。这就排除了 tf.placeholder() 和 tf.constant(),因为它们的 Tensor 不能改变。这里就需要 tf.Variable 了。
x = tf.Variable(5)tf.Variable 类创建一个 tensor,其初始值可以被改变,就像普通的 Python 变量一样。该 tensor 把它的状态存在 session 里,所以你必须手动初始化它的状态。你将使用 tf.global_variables_initializer() 函数来初始化所有可变 tensor。
tf.global_variables_initializer() 会返回一个操作,它会从 graph 中初始化所有的 TensorFlow 变量。你可以通过 session 来调用这个操作来初始化所有上面的变量。
1 init = tf.global_variables_initializer() 2 with tf.Session() as sess: 3 sess.run(init)
正态随机
tf.truncated_normal()
用 tf.Variable 类可以让我们改变权重和偏差,但还是要选择一个初始值
从正态分布中取随机数来初始化权重是个好习惯。随机化权重可以避免模型每次训练时候卡在同一个地方。
类似地,从正态分布中选择权重可以避免任意一个权重与其他权重相比有压倒性的特性。你可以用 tf.truncated_normal() 函数从一个正态分布中生成随机数。
1 n_features = 120 #行数 2 n_labels = 5 #列数 3 weights = tf.Variable(tf.truncated_normal((n_features, n_labels)))
tf.zeros()
tf.zeros() 函数返回一个都是 0 的 tensor
tf.truncated_normal() 返回一个 tensor,它的随机值取自一个正态分布,并且它们的取值会在这个正态分布平均值的两个标准差之内。
因为权重已经被随机化来帮助模型不被卡住,你不需要再把偏差随机化了。让我们简单地把偏差设为 0。
n_labels = 5
bias = tf.Variable(tf.zeros(n_labels))
TensorFlow Softmax
Softmax 函数可以把它的输入,通常被称为 logits 或者 logit scores,处理成 0 到 1 之间,并且能够把输出归一化到和为 1。这意味着 softmax 函数与分类的概率分布等价。它是一个网络预测多分类问题的最佳输出激活函数。

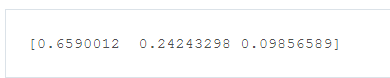
x = tf.nn.softmax([2.0, 1.0, 0.2])
例子:
1 # Solution is available in the other "solution.py" tab 2 import tensorflow as tf 3 4 def run(): 5 output = None 6 logit_data = [2.0, 1.0, 0.1] 7 logits = tf.placeholder(tf.float32) 8 9 # TODO: Calculate the softmax of the logits 10 # softmax = 11 12 with tf.Session() as sess: 13 # TODO: Feed in the logit data 14 # output = sess.run(softmax, ) 15 x = tf.nn.softmax(logit_data) 16 output=sess.run(x) 17 return output
TensorFlow 中的交叉熵(Cross Entropy)
与 softmax 一样,TensorFlow 也有一个函数可以方便地帮我们实现交叉熵。
Cross entropy loss function 交叉熵损失函数
让我们把你从视频当中学到的知识,在 TensorFlow 中来创建一个交叉熵函数。创建一个交叉熵函数,你需要用到这两个新的函数:
Reduce Sum
x = tf.reduce_sum([1, 2, 3, 4, 5]) # 15
tf.reduce_sum() 函数输入一个序列,返回它们的和
Natural Log
x = tf.log(100) # 4.60517
tf.log() 所做跟你所想的一样,它返回所输入值的自然对数。
例子
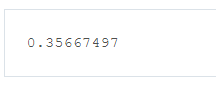
1 # Solution is available in the other "solution.py" tab 2 import tensorflow as tf 3 4 softmax_data = [0.7, 0.2, 0.1] 5 one_hot_data = [1.0, 0.0, 0.0] 6 7 softmax = tf.placeholder(tf.float32) 8 one_hot = tf.placeholder(tf.float32) 9 10 # ToDo: Print cross entropy from session 交叉熵的函数 11 cross_entropy = -tf.reduce_sum(tf.multiply(one_hot, tf.log(softmax))) 12 13 with tf.Session() as sess: #运行并输入参数,输出结果。 14 print(sess.run(cross_entropy, feed_dict={softmax: softmax_data, one_hot: one_hot_data}))
None(占位符)
None 维度在这里是一个占位符。这个设置可以让你把 features 和 labels 给到模型。无论 batch 中包含 128,还是 104 个数据点。
n_input = 784
n_classes = 10
1 features = tf.placeholder(tf.float32, [None, n_input]) 2 labels = tf.placeholder(tf.float32, [None, n_classes])

