
python学习笔记——拾壹
RabbitMQ 六种模式 Redis 可存放的五种数据
协程和io多路复用的区别
都继承了相同的类 libevent.so
协程也可以理解是io多路复用
io多路复用更偏向io一点
协程是更上层的一种封装 偏向于函数的切换。
RabbitMQ 消息队列
1.单发送单接收
2.单发送多接收
3.广播、订阅模式
4.有选择的接收消息 Routing (按路线发送接收)
5.更细致的消息过滤 Topics (按topic发送接收)
6.RPC
进程queue :
在父进程与子进程进行交互,或者同属于同一以父进程下的多个子进程交互。
rabbitMq:两个独立的程序程序 或者 在java和python的程序通信,不同机器的 通讯, 这时需要一个中间的代理。RabbitMQ。
为什么生产者已经声明了管道,消费者还要再次声明?
如果生产者首先启动,管道已经创建,不会有问题。
如果消费者首先启动,没有声明管道,会报错
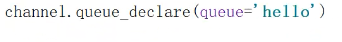
在windows安装了RabbitMQ
生产者
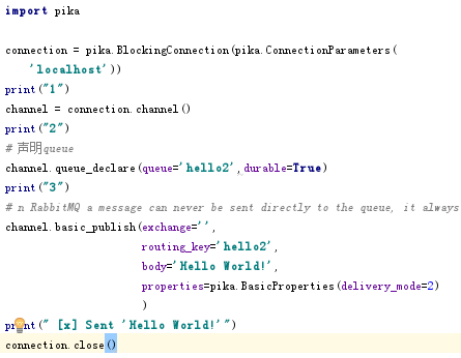
消费者

消费者的 callback函数
ch代表管道的内存对象
methon 队列的信息
body 数据
数据处理在此

rabbitMQ的消费者 消费数据是轮询方式的
如果启动3个消费者a b c
生产者第1次生产数据,a收到
生产者第2次生产数据,b收到
生产者第3次生产数据,c收到
生产者第4次生产数据,a收到
如此循环往复,公平的把消息分给每个消费者,做到了负载均衡
注意下图,有参数no_ack
True代表 无论消费者是否把消息处理完,都不给生产者回应,不关心消息。
False代表 默认是False,消息处理完给生产者回应
RabbitMQ根据消费者的回应而删除消息,如果消息处理到一半,消费者挂掉,那么
消息,不会删除,而是发给其他消费者。

windos 下使用以下命令 查到 当前的队列和其中的消息数

数据持久化
在创建管道时 设置durable=True 持久化队列 在生产者和服务端都需要写

在发送消息时 设置如下图 持久化消息 生产者

完整如下图:
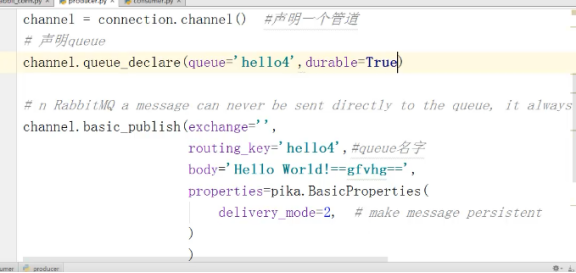
rabbitMQ的负载均衡
在消费者端 设置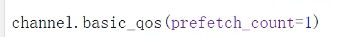
如此设置之后 如果当前的消费者处理的消息超过1条,就会被转发到其他的消费者上。所有的消费者都设置,处理消息快的消费者,处理完一条消息会接着处理,处理慢的就会先把当前的消息处理完,再接收下个消息。这样就做到了负责均衡。

设置广播模式 消息订阅
订阅发布 可以同时给绑定相同转发器的消费这发送消息,但是消息就像广播一样,虽然你不在听了。但是消息还是正常发送,错过了的消息不会再出现。
生产者
exchange=“log”是转发器
type=‘fanout’
不用再声明queue 需要在消费者声明queue

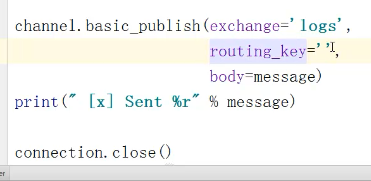
消费者:

sys.argv[] 获取外部的参数
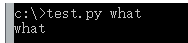
比如保存一个test.py
import sys
a=sys.argv[1]
print(a)
运行 时加一个参数 what 结果如下 得到what
具体解释:E:\python学习\学习网页\Python中 sys.argv[]的用法简明解释
sys.exit()的退出比较优雅,调用后会引发SystemExit异常,可以捕获此异常,执行异常处理中的代码
os._exit()直接将python解释器退出,余下的语句不会执行
exit(0):无错误退出
exit(1):有错误退出
有选择的接受消息
生产者在发送消息需要
test_p.py error helle_word
test_p.py(生产者的文件) error(加上类型) helle_word(内容)
消费者在发送消息需要
test_c.py error info
test_c.py(消费者的文件) error info(加上类型,可以多写几个)
当然 把error换成 sb都可以,只是生产者和消费者的类型如果对不上就收不到消息
生产者
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 host='localhost')) 6 channel = connection.channel() 7 #type改成 direct 8 channel.exchange_declare(exchange='direct_logs', 9 type='direct') 10 #如果len(sys.argv) > 1 执行 sys.argv[1] 否则 'info' 11 #severity 参数输入的是级别 12 severity = sys.argv[1] if len(sys.argv) > 1 else 'info' 13 #join把字符串按照“ ”隔开 14 message = ' '.join(sys.argv[2:]) or 'Hello World!' 15 channel.basic_publish(exchange='direct_logs', 16 routing_key=severity, 17 body=message) 18 print(" [x] Sent %r:%r" % (severity, message)) 19 connection.close()
消费者
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 host='localhost')) 6 channel = connection.channel() 7 8 channel.exchange_declare(exchange='direct_logs', 9 type='direct') 10 11 result = channel.queue_declare(exclusive=True) 12 queue_name = result.method.queue 13 14 severities = sys.argv[1:] 15 #如果 severities是空的 16 #sys.argv[0]是运行程序本身的名字 17 if not severities: 18 sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) 19 sys.exit(1) 20 #在cmd执行的时候加上 error info 这些类型 21 #循环遍历这些类型,并把他们绑定到转发器上, 22 # 当然生产者在发消息的时候需要给消息加上类型 例:test.py error hell_word 23 for severity in severities: 24 channel.queue_bind(exchange='direct_logs', 25 queue=queue_name, 26 routing_key=severity) 27 28 print(' [*] Waiting for logs. To exit press CTRL+C') 29 30 31 def callback(ch, method, properties, body): 32 print(" [x] %r:%r" % (method.routing_key, body)) 33 34 35 channel.basic_consume(callback, 36 queue=queue_name, 37 no_ack=True) 38 39 channel.start_consuming()
更细致的消息过滤
类型改为type='topic'
生产者在发送消息需要
test_p.py sdfdsf.info
test_p.py (生产者代码文件) sdfdsf.info(发送的消息)
消费者在接收消息时
test_c.py *.info NB.*
test_c.py (消费者代码文件) *.info(收。info结尾的) NB.*(收NB开头的)
test_c.py #(#代表收所有”)
更细致的消息过滤——生产者
import pika import sys connection = pika.BlockingConnection (pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') # 如果什么都不写 默认发个 'anonymous.info' routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
更细致的消息过滤——消费者
1 import pika 2 import sys 3 4 connection = pika.BlockingConnection(pika.ConnectionParameters( 5 host='localhost')) 6 channel = connection.channel() 7 8 channel.exchange_declare(exchange='topic_logs', 9 type='topic') 10 11 result = channel.queue_declare(exclusive=True) 12 queue_name = result.method.queue 13 14 binding_keys = sys.argv[1:] 15 if not binding_keys: 16 sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) 17 sys.exit(1) 18 19 for binding_key in binding_keys: 20 channel.queue_bind(exchange='topic_logs', 21 queue=queue_name, 22 routing_key=binding_key) 23 24 print(' [*] Waiting for logs. To exit press CTRL+C') 25 26 def callback(ch, method, properties, body): 27 print(" [x] %r:%r" % (method.routing_key, body)) 28 29 channel.basic_consume(callback, 30 queue=queue_name, 31 no_ack=True) 32 33 channel.start_consuming()
RPC(远程方法调用)
p机器发送一条指令给c机器,c机器执行完把结果返回
原理:p和c机器既是生产者也是消费者,两个队列。一个发消息,一个收消息。
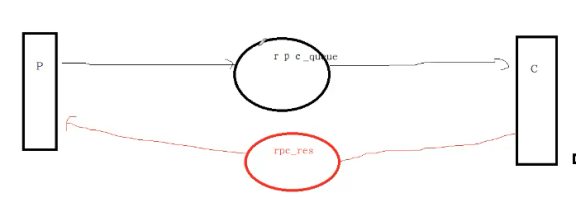
client代码
客户端发送一条消息给服务端,服务端处理后把结果返回给客户端
self.response = None,然后搞一个死循环 while self.response is None: ,如果为空就一直循环下去 ,在方法里又调用了self.connection.process_data_events() (非阻塞版的start_consuming())来接收消息。一旦有消息过来
self.channel.basic_consume(self.on_response,#只要一收到消息就调用 on_response
no_ack=True,
queue=self.callback_queue)
然后把消息 body的值赋给 self.response ,这时就结束了上述的死循环
RPC—客户端
1 import pika 2 import uuid 3 4 5 class FibonacciRpcClient(object): 6 def __init__(self): 7 self.connection = pika.BlockingConnection(pika.ConnectionParameters( 8 host='localhost')) 9 10 self.channel = self.connection.channel() 11 12 result = self.channel.queue_declare(exclusive=True) 13 self.callback_queue = result.method.queue 14 15 self.channel.basic_consume(self.on_response,#只要一收到消息就调用 on_response 16 no_ack=True, 17 queue=self.callback_queue) 18 19 def on_response(self, ch, method, props, body): 20 #客户端把uuid发送给服务端,服务端返回消息时把uuid也带了回来props.correlation_id: 21 #如果两个uuid相同,说明服务端返回的消息是,我们需要的。 22 #然后把 返回值赋给 self.response 23 if self.corr_id == props.correlation_id: 24 self.response = body 25 26 def call(self, n): 27 self.response = None 28 #uuid生成唯一的字符串 29 self.corr_id = str(uuid.uuid4()) 30 self.channel.basic_publish(exchange='', 31 #把消息发送到指定队列,服务端接收 32 routing_key='rpc_queue', 33 properties=pika.BasicProperties( 34 #self.callback_queue,会随机产生一个队列 35 # 用来接收服务端返回的消息 36 reply_to=self.callback_queue, 37 correlation_id=self.corr_id, 38 ), 39 40 body=str(n)) #消息发了个 30 n是接收的参数 41 #如果 self.response是None就一直循环 42 while self.response is None: 43 #非阻塞版的start_consumi 44 self.connection.process_data_events() 45 print("没有消息") 46 return int(self.response) 47 48 49 fibonacci_rpc = FibonacciRpcClient() 50 51 print(" [x] Requesting fib(30)") 52 response = fibonacci_rpc.call(30) 53 print(" [.] Got %r" % response)
RPC——服务端
# _*_coding:utf-8_*_ __author__ = 'Alex Li' import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n - 1) + fib(n - 2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) #response是获取到的结果,这里fib是一个斐波那契数列,测试用的 response = fib(n) ch.basic_publish(exchange='', #获取到客户端传来随机的队列名,用来返回消息 routing_key=props.reply_to, #用于把客户端发来uuid,在返回去。 properties=pika.BasicProperties(correlation_id= \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
redis(列表,字典这种数据都可以通过json序列化后存到redis中,它们在被序列化后都是string类型的)
redis和rabiitMq的区别
rdis创建了一个内存空间,有需要的进程可以共享这个空间的数据。
rabbitMQ消息队列,数据处理完就消失。
用程序连接redis时,报错 受保护模式
DENIED Redis is running in protected mode
修改redis.conf
protected-mode yes 把yes改为no
最简单的操作
1 import redis 2 r= redis.Redis(host='192.168.30.138', port=6379) 3 #设置key velue 4 r.set('foo2', 'Bar_two') 5 #获得指定key 6 print(r.get('foo2')) 7 print("----------") 8 #获得所有key的名称 9 print(r.keys())
输出

ridis支持多种操作
StringHash List set Sort Ser
setbit
setbit n3 6 1
setbit n3(key) 6(需要改变的位置) 1(需要改变的值)
n3对应的值是 alex
把它的第6位改成1 那么ascii码是99 对应字母是c
ord(“a”)把a转成ascii码
97
转成二进制
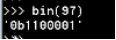

BITCOUNT n4(n4对应的是a) 得到占了多少位
8位=1字节 1024字节=1kb
在上图中看到 a的二进制,共出现3个1,占了3个位置
所以得到的结果是3

假如有一个网站,统计同时在线人数 id分别是1000,55,6000
bitcount 得到3 代表有3个在线
getbit n5 55(id) 得到1 代表在线
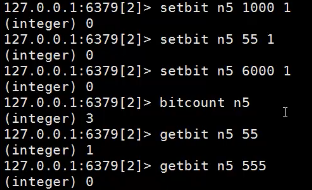
另外一种方法
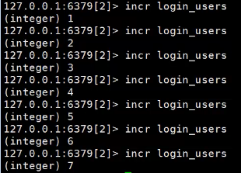
incr 自增 loggin_users(随便写的,之前并不存在)
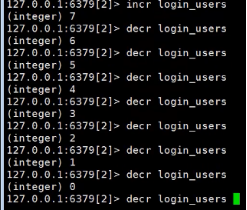
decr 自减
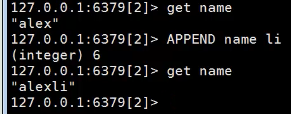
APPEND 追加
APPEND name(key) li(追加的字符)
一些操作方法
set(name, value, ex=None, px=None, nx=False, xx=False)

以上方法也可以用以下代替
setnx(name, value) 设置值,只有name不存在时,执行设置操作(添加)
setex(name, value, time) 给数据设值过期期间,单位秒
psetex(name, time_ms, value) 给数据设值过期期间,单位毫秒
#批量设置值
mset(*args, **kwargs) 例子:mget({'k1': 'v1', 'k2': 'v2'})
getset(name, value) 设置新值并获取原来的值
#从指定位置开始,替换字符串
setrange(name, offset, value) 例:setrange("foo2",2,"dddddddd")
redis hash操作
我们在 string时存数据,都是这样的,取数据的时候就是get name这样
但有一个问题 这个存的只是一个人的信息 当我们想存多个人的信息时该怎么办呢

于是有了hash
存数据
这时就类似于嵌套了 info就是你自定义在最外层的key
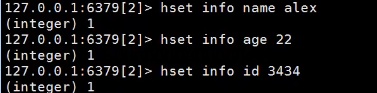
批量存数据

HGETALL info 获得info里所有的数据

获取info的某个key
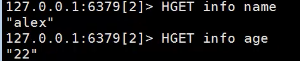
获取多个key

查看info所有的key
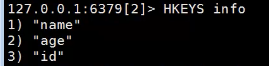
查看info所有的velue
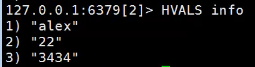
获取key的数量

查看某个hash下 的某个 key是否有数据 有返回1 无返回0
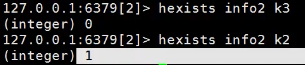
删除某个key

过滤
1.得到n开头的
2.得到包含a的
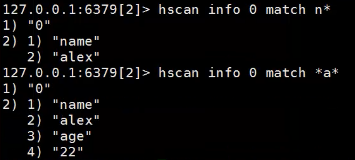
过滤 得到一个迭代器
redis list
存数据
rpush(先入先出,正序,常用)

rpushx lpushx列表存在才存数据
lpush(先入后出,取的时候数据是倒序的 命令) names(集合名)

取数据
根据下标取数据 lindex

分片取数据 一定要加下标
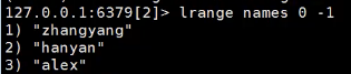
插入数据
在names列表 alex之前插入一个值TEST 关键字 BEFORE

alex之后插入一个值 TEST 关键字 AFTER

在指定位置插入数据 下标3的位置插入ALEX

删除数据
指定删除几个值 删除的值


从左侧获取第一个元素 并删除

原数据如下:
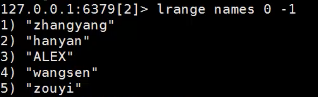
从左侧删除并返回第一个值 如果这个列表没有值就等4秒

保留指定位置的数据,删除其他的

原数据

把names最右边的元素,移动到names2的最左边

将naems列表最右边的元素,移动到names2列表的最左边,
如果names列表没有值则等待40秒

redis set
无序,不可重复
存数据

取数据

获取元素个数

差集
得到name3 减去 name3和name4的交集(两边都有的)
结果=name3-(name3∩name4)

把name3和names4的差集 存到n6

交集
获得 name3和name4的交集
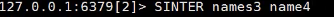
获得到交集存到新的地方 仿照差集

并集 获得names3和name4的并集

判断 集合中是否是指定值 有返回1 无返回0

移动元素到另外一个集合

删除尾部一个元素,并返回这个值

随机获取集合中的一个值

随机获取集合中的几个值

删除指定值

过滤
得到n7集合 中j开头的元素 0是光标,代表从头开始,不是下标。
集合是无序的

过滤 获得一个可迭代的对象

redis 有序集合(不可重复)
分数越小 数据越靠前
存数据
zadd(关键字) z1集合名 10(分数) alex(元素)

取数据 切片取

加个 withscores关键字 显示出排名

获取分数6到8分数之间的数据 有几个

获取alex所在的位置 2代表第3位,从0开始

删除 指定元素 可多个

根据排行删除数据 删除第2个到第4个

根据分数删除数据

获取指定元素的分数

过滤

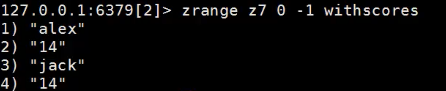
把两个集合的交集 给z7集合 并把交集元素所在集合的分数加起来
命令中的2 意思是要统计几个集合

例如:alex在z1中分数是7 在z2中是7 那么分数就是14
redis其他操作
在redis默认有16个数据库 0到15
切换数据库 如图

把数据移动到其他数据库中
移动name到10数据库中,如果10数据库中有name,则移动失败,返回0

key *
查看redis现在的所有数据
还可以加正则表达式

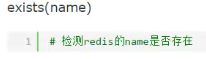
查看redis指定数据是否存在
查看数据的类型

删除任意数据类型 string hash。。

给redis中的数据设置过期时间,2秒后 info被删除

python 连接redis
redis默认每执行一次请求都会创建和断开连接池。如果想在一次连接中执行多个命令,可以利用管道如下:pipeline
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 import redis 4 pool = redis.ConnectionPool(host='10.211.55.4', port=6379) 5 6 r = redis.Redis(connection_pool=pool) 7 8 # pipe = r.pipeline(transaction=False) 9 pipe = r.pipeline(transaction=True) 10 11 pipe.set('name', 'alex') 12 pipe.set('role', 'sb') 13 14 pipe.execute()
redis订阅发布


