

GO(三)
Go语言切片(Slice)
slice 并不是数组或数组指针。它通过内部指针和相关属性引用数组片段,以实现变长方案。 Go 语言切片是对数组的抽象。
Go 数组的长度不可改变,在特定场景中这样的集合就不太适用,Go 中提供了一种灵活,功能强悍的内置类型切片("动态数组"),与数组相比切片的长度是不固定的,可以追加元素,在追加时可能使切片的容量增大。
介绍
- 切片:切片是数组的一个引用,因此切片是引用类型。但自身是结构体,值拷贝传递。
- 切片的长度可以改变,因此,切片是一个可变的数组。
- 切片遍历方式和数组一样,可以用len()求长度。表示可用元素数量,读写操作不能超过该限制。
- cap可以求出slice最大扩张容量,不能超出数组限制。0 <= len(slice) <= len(array),其中array是slice引用的数组。
- 切片的定义:var 变量名 []类型,比如 var str []string var arr []int。
- 如果 slice == nil,那么 len、cap 结果都等于 0。
定义切片
你可以声明一个未指定大小的数组来定义切片:
var identifier []type
切片不需要说明长度。
或使用 make() 函数来创建切片:
var slice1 []type = make([]type, len)
也可以简写为
slice1 := make([]type, len)
也可以指定容量,其中 capacity 为可选参数。
make([]T, length, capacity)
这里 len 是数组的长度并且也是切片的初始长度。
切片初始化
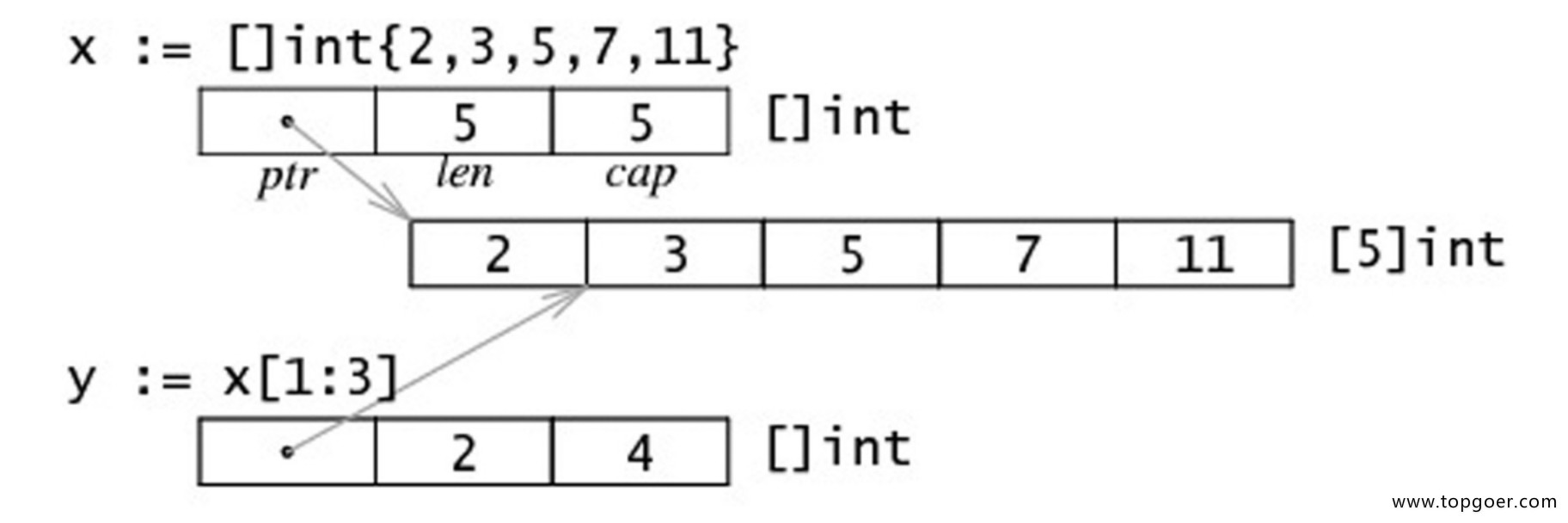
s :=[] int {1,2,3 }
直接初始化切片,[] 表示是切片类型,{1,2,3} 初始化值依次是 1,2,3,其 cap=len=3。
s := arr[:]
初始化切片 s,是数组 arr 的引用。
s := arr[startIndex:endIndex]
将 arr 中从下标 startIndex 到 endIndex-1 下的元素创建为一个新的切片。
s := arr[startIndex:]
默认 endIndex 时将表示一直到arr的最后一个元素。
s := arr[:endIndex]
默认 startIndex 时将表示从 arr 的第一个元素开始。
s1 := s[startIndex:endIndex]
通过切片 s 初始化切片 s1。
make来初始化数组
| 操作 | 含义 |
|---|---|
| s[n] | 切片s中索引位置为n的项 |
| s[:] | 从切片位置s的索引位置0到len(s)-1处获得的切片 |
| s[low:] | 从切片s的索引位置low到len(s)-1处获得的切片 |
| s[:high] | 从切片s的索引位置0到hight处获得的切片,len=high |
| s[low:high:max] | 从切片s的索引位置low到high处获得的切片,len=high-low |
| len(s) | 切片s的长度,总是<=cap(s) |
| cap(s) | 切片s的容量,总是>=len(s) |
s :=make([]int,len,cap)
通过内置函数 make() 初始化切片s,[]int 标识为其元素类型为 int 的切片。
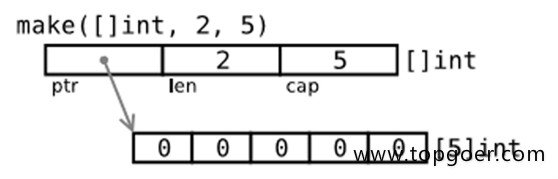
使用 make 动态创建slice,避免了数组必须用常量做长度的麻烦。还可用指针直接访问底层数组,退化成普通数组操作。
package main
import "fmt"
func main() {
s := []int{0, 1, 2, 3}
p := &s[2] // *int, 获取底层数组元素指针。
*p += 100
fmt.Println(s)
}
输出结果:
[0 1 102 3]
[]T类型
至于 [][]T,是指元素类型为 []T 。
package main
import (
"fmt"
)
func main() {
data := [][]int{
[]int{1, 2, 3},
[]int{100, 200},
[]int{11, 22, 33, 44},
}
fmt.Println(data)
}
输出结果:
[[1 2 3] [100 200] [11 22 33 44]]
可直接修改 struct array/slice 成员。
数组对象的使用
package main
import (
"fmt"
)
func main() {
d := [5]struct {
x int
}{}
s := d[:]
d[1].x = 10
s[2].x = 20
fmt.Println(d)
fmt.Printf("%p, %p\n", &d, &d[0])
}
输出结果:
[{0} {10} {20} {0} {0}]
0xc4200160f0, 0xc4200160f0
用append内置函数操作切片(切片追加)
package main
import (
"fmt"
)
func main() {
var a = []int{1, 2, 3}
fmt.Printf("slice a : %v\n", a)
var b = []int{4, 5, 6}
fmt.Printf("slice b : %v\n", b)
c := append(a, b...)
fmt.Printf("slice c : %v\n", c)
d := append(c, 7)
fmt.Printf("slice d : %v\n", d)
e := append(d, 8, 9, 10)
fmt.Printf("slice e : %v\n", e)
}
输出结果:
slice a : [1 2 3]
slice b : [4 5 6]
slice c : [1 2 3 4 5 6]
slice d : [1 2 3 4 5 6 7]
slice e : [1 2 3 4 5 6 7 8 9 10]
append :向 slice 尾部添加数据,返回新的 slice 对象。
package main
import (
"fmt"
)
func main() {
s1 := make([]int, 0, 5)
fmt.Printf("%p\n", &s1)
s2 := append(s1, 1)
fmt.Printf("%p\n", &s2)
fmt.Println(s1, s2)
}
输出结果:
0xc42000a060
0xc42000a080
[] [1]
当数组分配越界时
超出原 slice.cap 限制,就会重新分配底层数组,即便原数组并未填满
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 10: 0}
s := data[:2:3]
s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。
fmt.Println(s, data) // 重新分配底层数组,与原数组无关。
fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。
}
从输出结果可以看出,append 后的 s 重新分配了底层数组,并复制数据。如果只追加一个值,则不会超过 s.cap 限制,也就不会重新分配。 通常以 2 倍容量重新分配底层数组。在大批量添加数据时,建议一次性分配足够大的空间,以减少内存分配和数据复制开销。或初始化足够长的 len 属性,改用索引号进行操作。及时释放不再使用的 slice 对象,避免持有过期数组,造成 GC 无法回收。
slice中cap重新分配规律
package main
import (
"fmt"
)
func main() {
s := make([]int, 0, 1)
c := cap(s)
for i := 0; i < 50; i++ {
s = append(s, i)
if n := cap(s); n > c {
fmt.Printf("cap: %d -> %d\n", c, n)
c = n
}
}
}
输出结果:
cap: 1 -> 2
cap: 2 -> 4
cap: 4 -> 8
cap: 8 -> 16
cap: 16 -> 32
cap: 32 -> 64
len() 和 cap() 函数
切片是可索引的,并且可以由 len() 方法获取长度。
切片提供了计算容量的方法 cap() 可以测量切片最长可以达到多少。
package main
import "fmt"
func main() {
var numbers = make([]int,3,5)
printSlice(numbers)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
空(nil)切片
一个切片在未初始化之前默认为 nil,长度为 0,
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
if(numbers == nil){
fmt.Printf("切片是空的")
}
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
切片截取
可以通过设置下限及上限来设置截取切片 [lower-bound:upper-bound],
package main
import "fmt"
func main() {
/* 创建切片 */
numbers := []int{0,1,2,3,4,5,6,7,8}
printSlice(numbers)
/* 打印原始切片 */
fmt.Println("numbers ==", numbers)
/* 打印子切片从索引1(包含) 到索引4(不包含)*/
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* 默认下限为 0*/
fmt.Println("numbers[:3] ==", numbers[:3])
/* 默认上限为 len(s)*/
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int,0,5)
printSlice(numbers1)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */
number2 := numbers[:2]
printSlice(number2)
/* 打印子切片从索引 2(包含) 到索引 5(不包含) */
number3 := numbers[2:5]
printSlice(number3)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
切片的大小
切片resize(调整大小)
package main
import (
"fmt"
)
func main() {
var a = []int{1, 3, 4, 5}
fmt.Printf("slice a : %v , len(a) : %v\n", a, len(a))
b := a[1:2]
fmt.Printf("slice b : %v , len(b) : %v\n", b, len(b))
c := b[0:3]
fmt.Printf("slice c : %v , len(c) : %v\n", c, len(c))
}
输出结果:
slice a : [1 3 4 5] , len(a) : 4
slice b : [3] , len(b) : 1
slice c : [3 4 5] , len(c) : 3
字符串和切片(string and slice)
string底层就是一个byte的数组,因此,也可以进行切片操作。
package main
import (
"fmt"
)
func main() {
str := "hello world"
s1 := str[0:5]
fmt.Println(s1)
s2 := str[6:]
fmt.Println(s2)
}
输出结果:
hello
world
string本身是不可变的,因此要改变string中字符。需要如下操作: 英文字符串:
package main
import (
"fmt"
)
func main() {
str := "Hello world"
s := []byte(str) //中文字符需要用[]rune(str)
s[6] = 'G'
s = s[:8]
s = append(s, '!')
str = string(s)
fmt.Println(str)
}
输出结果:
Hello Go!
含有中文字符串:
package main
import (
"fmt"
)
func main() {
str := "你好,世界!hello world!"
s := []rune(str)
s[3] = '够'
s[4] = '浪'
s[12] = 'g'
s = s[:14]
str = string(s)
fmt.Println(str)
}
输出结果:
你好,够浪!hello go
golang slice data[:6:8] 两个冒号的理解
常规slice , data[6:8],从第6位到第8位(返回6, 7),长度len为2, 最大可扩充长度cap为4(6-9)
另一种写法: data[:6:8] 每个数字前都有个冒号, slice内容为data从0到第6位,长度len为6,最大扩充项cap设置为8
a[x:y:z] 切片内容 [x:y] 切片长度: y-x 切片容量:z-x
package main
import (
"fmt"
)
func main() {
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
d1 := slice[6:8]
fmt.Println(d1, len(d1), cap(d1))
d2 := slice[:6:8]
fmt.Println(d2, len(d2), cap(d2))
}
数组or切片转字符串:
strings.Replace(strings.Trim(fmt.Sprint(array_or_slice), "[]"), " ", ",", -1)
append() 和 copy() 函数
从拷贝切片的 copy 方法和向切片追加新元素的 append 方法。
package main
import "fmt"
func main() {
var numbers []int
printSlice(numbers)
/* 允许追加空切片 */
numbers = append(numbers, 0)
printSlice(numbers)
/* 向切片添加一个元素 */
numbers = append(numbers, 1)
printSlice(numbers)
/* 同时添加多个元素 */
numbers = append(numbers, 2,3,4)
printSlice(numbers)
/* 创建切片 numbers1 是之前切片的两倍容量*/
numbers1 := make([]int, len(numbers), (cap(numbers))*2)
/* 拷贝 numbers 的内容到 numbers1 */
copy(numbers1,numbers)
printSlice(numbers1)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
copy函数
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
fmt.Println("array data : ", data)
s1 := data[8:]
s2 := data[:5]
fmt.Printf("slice s1 : %v\n", s1)
fmt.Printf("slice s2 : %v\n", s2)
copy(s2, s1)
fmt.Printf("copied slice s1 : %v\n", s1)
fmt.Printf("copied slice s2 : %v\n", s2)
fmt.Println("last array data : ", data)
}
array data : [0 1 2 3 4 5 6 7 8 9]
slice s1 : [8 9]
slice s2 : [0 1 2 3 4]
copied slice s1 : [8 9]
copied slice s2 : [8 9 2 3 4]
last array data : [8 9 2 3 4 5 6 7 8 9]
应及时将所需数据 copy 到较小的 slice,以便释放超大号底层数组内存。
Go语言范围(Range)
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
for 循环的 range 格式可以对 slice、map、数组、字符串等进行迭代循环。
for key, value := range oldMap {
newMap[key] = value
}
例子:
package main
import "fmt"
var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
func main() {
for i, v := range pow {
fmt.Printf("2**%d = %d\n", i, v)
}
}
for 循环的 range 格式可以省略 key 和 value,
例子:
package main
import "fmt"
func main() {
map1 := make(map[int]float32)
map1[1] = 1.0
map1[2] = 2.0
map1[3] = 3.0
map1[4] = 4.0
// 读取 key 和 value
for key, value := range map1 {
fmt.Printf("key is: %d - value is: %f\n", key, value)
}
// 读取 key
for key := range map1 {
fmt.Printf("key is: %d\n", key)
}
// 读取 value
for _, value := range map1 {
fmt.Printf("value is: %f\n", value)
}
}
range 遍历其他的数据结构:
package main
import "fmt"
func main() {
//这是我们使用 range 去求一个 slice 的和。使用数组跟这个很类似
nums := []int{2, 3, 4}
sum := 0
for _, num := range nums {
sum += num
}
fmt.Println("sum:", sum)
//在数组上使用 range 将传入索引和值两个变量。上面那个例子我们不需要使用该元素的序号,所以我们使用空白符"_"省略了。有时侯我们确实需要知道它的索引。
for i, num := range nums {
if num == 3 {
fmt.Println("index:", i)
}
}
//range 也可以用在 map 的键值对上。
kvs := map[string]string{"a": "apple", "b": "banana"}
for k, v := range kvs {
fmt.Printf("%s -> %s\n", k, v)
}
//range也可以用来枚举 Unicode 字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
for i, c := range "go" {
fmt.Println(i, c)
}
}
Go语言Map(集合)
Map 是一种无序的键值对的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序,这是因为 Map 是使用 hash 表来实现的。
定义 Map
可以使用内建函数 make 也可以使用 map 关键字来定义 Map:
/* 声明变量,默认 map 是 nil */
var map_variable map[key_data_type]value_data_type
/* 使用 make 函数 */
map_variable := make(map[key_data_type]value_data_type)
如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对
例子:
package main
import "fmt"
func main() {
var countryCapitalMap map[string]string /*创建集合 */
countryCapitalMap = make(map[string]string)
/* map插入key - value对,各个国家对应的首都 */
countryCapitalMap [ "France" ] = "巴黎"
countryCapitalMap [ "Italy" ] = "罗马"
countryCapitalMap [ "Japan" ] = "东京"
countryCapitalMap [ "India " ] = "新德里"
/*使用键输出地图值 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [country])
}
/*查看元素在集合中是否存在 */
capital, ok := countryCapitalMap [ "American" ] /*如果确定是真实的,则存在,否则不存在 */
/*fmt.Println(capital) */
/*fmt.Println(ok) */
if (ok) {
fmt.Println("American 的首都是", capital)
} else {
fmt.Println("American 的首都不存在")
}
}
delete()函数
delete() 函数用于删除集合的元素, 参数为 map 和其对应的 key。 ·
package main
import "fmt"
func main() {
/* 创建map */
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
fmt.Println("原始地图")
/* 打印地图 */
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [ country ])
}
/*删除元素*/ delete(countryCapitalMap, "France")
fmt.Println("法国条目被删除")
fmt.Println("删除元素后地图")
/*打印地图*/
for country := range countryCapitalMap {
fmt.Println(country, "首都是", countryCapitalMap [ country ])
}
}
按照指定顺序遍历map
func main() {
rand.Seed(time.Now().UnixNano()) //初始化随机数种子
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}
判断某个键是否存在
Go语言中有个判断map中键是否存在的特殊写法,格式如下:
value, ok := map[key]
- v:表示为key的值
- ok:表示查找结果的状态--不存在为false
举个例子:
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
// 如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值
v, ok := scoreMap["张三"]
if ok {
fmt.Println(v)
} else {
fmt.Println("查无此人")
}
}
元素为map类型的切片
下面的代码演示了切片中的元素为map类型时的操作:
func main() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "王五"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "红旗大街"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}
值为切片类型的map
下面的代码演示了map中值为切片类型的操作:
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
流程控制
Go条件循环语句
| 语句 | 描述 |
|---|---|
| if 语句 | if 语句 由一个布尔表达式后紧跟一个或多个语句组成。 |
| if...else 语句 | if 语句 后可以使用可选的 else 语句, else 语句中的表达式在布尔表达式为 false 时执行。 |
| if 嵌套语句 | 你可以在 if 或 else if 语句中嵌入一个或多个 if 或 else if 语句。 |
| switch 语句 | switch 语句用于基于不同条件执行不同动作。 |
| select 语句 | select 语句类似于 switch 语句,但是select会随机执行一个可运行的case。如果没有case可运行,它将阻塞,直到有case可运行。 |
if
Go 编程语言中 if 语句的语法如下:
• 可省略条件表达式括号。
• 持初始化语句,可定义代码块局部变量。
• 代码块左 括号必须在条件表达式尾部。
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
}
if 在布尔表达式为 true 时,其后紧跟的语句块执行,如果为 false 则不执行。
- 语法
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
}
- 例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* 使用 if 语句判断布尔表达式 */
if a < 20 {
/* 如果条件为 true 则执行以下语句 */
fmt.Printf("a 小于 20\n" )
}
fmt.Printf("a 的值为 : %d\n", a)
}
if...else
- 语法
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} else {
/* 在布尔表达式为 false 时执行 */
}
- 例子
package main
import "fmt"
func main() {
/* 局部变量定义 */
var a int = 100;
/* 判断布尔表达式 */
if a < 20 {
/* 如果条件为 true 则执行以下语句 */
fmt.Printf("a 小于 20\n" );
} else {
/* 如果条件为 false 则执行以下语句 */
fmt.Printf("a 不小于 20\n" );
}
fmt.Printf("a 的值为 : %d\n", a);
}
if嵌套
- 语法
if 布尔表达式 1 {
/* 在布尔表达式 1 为 true 时执行 */
if 布尔表达式 2 {
/* 在布尔表达式 2 为 true 时执行 */
}
}
- 例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
/* 判断条件 */
if a == 100 {
/* if 条件语句为 true 执行 */
if b == 200 {
/* if 条件语句为 true 执行 */
fmt.Printf("a 的值为 100 , b 的值为 200\n" );
}
}
fmt.Printf("a 值为 : %d\n", a );
fmt.Printf("b 值为 : %d\n", b );
}
switch语句
- 语法
switch var1 {
case val1:
...
case val2:
...
default:
...
}
- 例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var grade string = "B"
var marks int = 90
switch marks {
case 90: grade = "A"
case 80: grade = "B"
case 50,60,70 : grade = "C"
default: grade = "D"
}
switch {
case grade == "A" :
fmt.Printf("优秀!\n" )
case grade == "B", grade == "C" :
fmt.Printf("良好\n" )
case grade == "D" :
fmt.Printf("及格\n" )
case grade == "F":
fmt.Printf("不及格\n" )
default:
fmt.Printf("差\n" );
}
fmt.Printf("你的等级是 %s\n", grade );
}
Type Switch
switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际存储的变量类型。
Type Switch 语法格式如下:
switch x.(type){
case type:
statement(s)
case type:
statement(s)
/* 你可以定义任意个数的case */
default: /* 可选 */
statement(s)
}
实例:
package main
import "fmt"
func main() {
var x interface{}
//写法一:
switch i := x.(type) { // 带初始化语句
case nil:
fmt.Printf(" x 的类型 :%T\r\n", i)
case int:
fmt.Printf("x 是 int 型")
case float64:
fmt.Printf("x 是 float64 型")
case func(int) float64:
fmt.Printf("x 是 func(int) 型")
case bool, string:
fmt.Printf("x 是 bool 或 string 型")
default:
fmt.Printf("未知型")
}
//写法二
var j = 0
switch j {
case 0:
case 1:
fmt.Println("1")
case 2:
fmt.Println("2")
default:
fmt.Println("def")
}
//写法三
var k = 0
switch k {
case 0:
println("fallthrough")
fallthrough
/*
Go的switch非常灵活,表达式不必是常量或整数,执行的过程从上至下,直到找到匹配项;
而如果switch没有表达式,它会匹配true。
Go里面switch默认相当于每个case最后带有break,
匹配成功后不会自动向下执行其他case,而是跳出整个switch,
但是可以使用fallthrough强制执行后面的case代码。
*/
case 1:
fmt.Println("1")
case 2:
fmt.Println("2")
default:
fmt.Println("def")
}
//写法三
var m = 0
switch m {
case 0, 1:
fmt.Println("1")
case 2:
fmt.Println("2")
default:
fmt.Println("def")
}
//写法四
var n = 0
switch { //省略条件表达式,可当 if...else if...else
case n > 0 && n < 10:
fmt.Println("i > 0 and i < 10")
case n > 10 && n < 20:
fmt.Println("i > 10 and i < 20")
default:
fmt.Println("def")
}
}
以上代码执行结果为:
x 的类型 :<nil>
fallthrough
1
1
def
select
- 语法
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
描述
- 每个case都必须是一个通信
- 所有channel表达式都会被求值
- 所有被发送的表达式都会被求值
- 如果任意某个通信可以进行,它就被执行,其他被忽略
- 如果有多个case都可以运行,Select会随机公平地选出一个执行。其他不会执行否则:
- 如果有default子句,则执行改语句
- 如果没有default子句,select将阻塞,直到某个通信可以运行;Go不会重新对channel或值进行求值
例子
select 会循环检测条件,如果有满足则执行并退出,否则一直循环检测。
package main
import (
"fmt" "time")
func Chann(ch chan int, stopCh chan bool) {
for j := 0; j < 10; j++ {
ch <- j
time.Sleep(time.Second)
}
stopCh <- true}
func main() {
ch := make(chan int)
c := 0 stopCh := make(chan bool)
go Chann(ch, stopCh)
for {
select {
case c = <-ch:
fmt.Println("Receive C", c)
case s := <-ch:
fmt.Println("Receive S", s)
case _ = <-stopCh:
goto end
}
}
end:
}
Go循环语句
| 控制语句 | 描述 |
|---|---|
| break 语句 | 经常用于中断当前 for 循环或跳出 switch 语句 |
| continue 语句 | 跳过当前循环的剩余语句,然后继续进行下一轮循环。 |
| goto 语句 | 将控制转移到被标记的语句。 |
for
for循环是一个循环控制结构,可以执行指定次数的循环。
语法
Go语言的For循环有3中形式,只有其中的一种使用分号。
for init; condition; post { }
for condition { }
for { }
init: 一般为赋值表达式,给控制变量赋初值;
condition: 关系表达式或逻辑表达式,循环控制条件;
post: 一般为赋值表达式,给控制变量增量或减量。
for语句执行过程如下:
①先对表达式 init 赋初值;
②判别赋值表达式 init 是否满足给定 condition 条件,若其值为真,满足循环条件,则执行循环体内语句,然后执行 post,进入第二次循环,再判别 condition;否则判断 condit
基本格式
package main
import "fmt"
func main() {
sum := 0
for i := 0; i <= 10; i++ {
sum += i
}
fmt.Println(sum)
}
for 循环的 range 格式
可以对 slice、map、数组、字符串等进行迭代循环。格式如下:
for key, value := range oldMap {
newMap[key] = value
}
例子
package main
import "fmt"
func main() {
strings := []string{"google", "runoob"}
for i, s := range strings {
fmt.Println(i, s)
}
numbers := [6]int{1, 2, 3, 5}
for i,x:= range numbers {
fmt.Printf("第 %d 位 x 的值 = %d\n", i,x)
}
}
输出:
0 google
1 runoob
第 0 位 x 的值 = 1
第 1 位 x 的值 = 2
第 2 位 x 的值 = 3
第 3 位 x 的值 = 5
第 4 位 x 的值 = 0
第 5 位 x 的值 = 0
无限循环
如果循环中条件语句永远不为 false 则会进行无限循环,我们可以通过 for 循环语句中只设置一个条件表达式来执行无限循环:
例子
package main
import "fmt"
func main() {
for true {
fmt.Printf("这是无限循环。\n");
}
}
break
- 用于循环语句中跳出循环,并开始执行循环之后的语句。
- break 在 switch(开关语句)中在执行一条 case 后跳出语句的作用。
- 在多重循环中,可以用标号 label 标出想 break 的循环
例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* for 循环 */
for a < 20 {
fmt.Printf("a 的值为 : %d\n", a);
a++;
if a > 15 {
/* 使用 break 语句跳出循环 */
break;
}
}
}
continue
Go 语言的 continue 语句 有点像 break 语句。但是 continue 不是跳出循环,而是跳过当前循环执行下一次循环语句。
for 循环中,执行 continue 语句会触发 for 增量语句的执行。
在多重循环中,可以用标号 label 标出想 continue 的循环
例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* for 循环 */
for a < 20 {
if a == 15 {
/* 跳过此次循环 */
a = a + 1;
continue;
}
fmt.Printf("a 的值为 : %d\n", a);
a++;
}
}
goto
Go 语言的 goto 语句可以无条件地转移到过程中指定的行。
goto 语句通常与条件语句配合使用。可用来实现条件转移, 构成循环,跳出循环体等功能。
但是,在结构化程序设计中一般不主张使用 goto 语句, 以免造成程序流程的混乱,使理解和调试程序都产生困难。
语法
goto label;
..
.
label: statement;
例子
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 10
/* 循环 */
LOOP: for a < 20 {
if a == 15 {
/* 跳过迭代 */
a = a + 1
goto LOOP
}
fmt.Printf("a的值为 : %d\n", a)
a++
}
}
补充-学习小算法
1-100素数
输出 1-100 素数:
package main
import "fmt"
func main() {
var C, c int//声明变量
C=1 /*这里不写入FOR循环是因为For语句执行之初会将C的值变为1,当我们goto A时for语句会重新执行(不是重新一轮循环)*/
A: for C < 100 {
C++ //C=1不能写入for这里就不能写入
for c=2; c < C ; c++ {
if C%c==0 {
goto A //若发现因子则不是素数
}
}
fmt.Println(C,"是素数")
}
}
实现99乘法表
Go 语言实现99乘法表
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ { // i 控制行,以及计算的最大值
for j := 1; j <= i; j++ { // j 控制每行的计算个数
fmt.Printf("%d*%d=%d ", j, i, j*i)
}
fmt.Println("")
}
}
1-100素数(2.0)
package main
import "fmt"
func main() {
var a, b int
for a = 2; a <= 100; a++ {
for b = 2; b <= (a / b); b++ {
if a%b == 0 {
break
}
}
if b > (a / b) {
fmt.Printf("%d\t是素数\n", a)
}
}
}
循环
循环:
package main
import "fmt"
import "strconv"
import "os"
func main(){
var score int = 0
var fenshu string = "A"
fmt.Printf("欢迎进入成绩查询系统\n")
ZHU: for true{
var xuanzhe int = 0
fmt.Println("1.进入成绩查询 2.退出程序")
fmt.Printf("请输入序号选择:")
fmt.Scanln(&xuanzhe)
fmt.Printf("\n")
if xuanzhe == 1{
goto CHA
}
if xuanzhe == 2{
os.Exit(1)
}
}
CHA: for true {
fmt.Printf("请输入一个学生的成绩:")
fmt.Scanln(&score)
switch {
case score >= 90:fenshu = "A"
case score >= 80&&score < 90:fenshu = "B"
case score >= 60&&score < 80:fenshu = "C"
default: fenshu = "D"
}
//fmt.Println(fenshu)
var c string = strconv.Itoa(score)
switch{
case fenshu == "A":
fmt.Printf("你考了%s分,评价为%s,成绩优秀\n",c,fenshu)
case fenshu == "B" || fenshu == "C":
fmt.Printf("你考了%s分,评价为%s,成绩良好\n",c,fenshu)
case fenshu == "D":
fmt.Printf("你考了%s分,评价为%s,成绩不合格\n",c,fenshu)
}
fmt.Printf("\n")
goto ZHU
}
//fmt.Println(score)
}
Go函数
golang函数特点:
• 无需声明原型。
• 支持不定 变参。
• 支持多返回值。
• 支持命名返回参数。
• 支持匿名函数和闭包。
• 函数也是一种类型,一个函数可以赋值给变量。
• 不支持 嵌套 (nested) 一个包不能有两个名字一样的函数。
• 不支持 重载 (overload)
• 不支持 默认参数 (default parameter)。
函数是基本的代码块,用于执行一个任务。
Go 语言最少有个 main() 函数。
你可以通过函数来划分不同功能,逻辑上每个函数执行的是指定的任务。
函数声明告诉了编译器函数的名称,返回类型,和参数。
Go 语言标准库提供了多种可动用的内置的函数。例如,len() 函数可以接受不同类型参数并返回该类型的长度。如果我们传入的是字符串则返回字符串的长度,如果传入的是数组,则返回数组中包含的元素个数。
语法
func function_name( [parameter list] ) [return_types] {
函数体
}
- func:函数由 func 开始声明
- function_name:函数名称,参数列表和返回值类型构成了函数签名。
- parameter list:参数列表,参数就像一个占位符,当函数被调用时,你可以将值传递给参数,这个值被称为实际参数。参数列表指定的是参数类型、顺序、及参数个数。参数是可选的,也就是说函数也可以不包含参数。
- return_types:返回类型,函数返回一列值。return_types 是该列值的数据类型。有些功能不需要返回值,这种情况下 return_types 不是必须的。
- 函数体:函数定义的代码集合。
简单例子
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int {
/* 声明局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
函数调用
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int = 200
var ret int
/* 调用函数并返回最大值 */
ret = max(a, b)
fmt.Printf( "最大值是 : %d\n", ret )
}
/* 函数返回两个数的最大值 */
func max(num1, num2 int) int {
/* 定义局部变量 */
var result int
if (num1 > num2) {
result = num1
} else {
result = num2
}
return result
}
函数返回多个值
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func main() {
a, b := swap("Google", "Runoob")
fmt.Println(a, b)
}
函数参数
函数定义时指出,函数定义时有参数,该变量可称为函数的形参。形参就像定义在函数体内的局部变量。
但当调用函数,传递过来的变量就是函数的实参,函数可以通过两种方式来传递参数:
值传递:指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
函数如果使用参数,该变量可称为函数的形参。
形参就像定义在函数体内的局部变量。
调用函数,可以通过两种方式来传递参数:
| 传递类型 | 描述 |
|---|---|
| 值传递 | 值传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。 |
| 引用传递 | 引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。 |
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
注意1:无论是值传递,还是引用传递,传递给函数的都是变量的副本,不过,值传递是值的拷贝。引用传递是地址的拷贝,一般来说,地址拷贝更为高效。而值拷贝取决于拷贝的对象大小,对象越大,则性能越低。
注意2:map、slice、chan、指针、interface默认以引用的方式传递。
不定参数传值 就是函数的参数不是固定的,后面的类型是固定的。(可变参数)
Golang 可变参数本质上就是 slice。只能有一个,且必须是最后一个。
在参数赋值时可以不用用一个一个的赋值,可以直接传递一个数组或者切片,特别注意的是在参数后加上“…”即可。
写法:
func myfunc(args ...int) { //0个或多个参数
}
func add(a int, args…int) int { //1个或多个参数
}
func add(a int, b int, args…int) int { //2个或多个参数
}
注意:其中args是一个slice,我们可以通过arg[index]依次访问所有参数,通过len(arg)来判断传递参数的个数.
任意类型的不定参数: 就是函数的参数和每个参数的类型都不是固定的。
用interface{}传递任意类型数据是Go语言的惯例用法,而且interface{}是类型安全的。
func myfunc(args ...interface{}) {
}
代码:
package main
import (
"fmt"
)
func test(s string, n ...int) string {
var x int
for _, i := range n {
x += i
}
return fmt.Sprintf(s, x)
}
func main() {
println(test("sum: %d", 1, 2, 3))
}
输出结果:
sum: 6
使用 slice 对象做变参时,必须展开。(slice...)
package main
import (
"fmt"
)
func test(s string, n ...int) string {
var x int
for _, i := range n {
x += i
}
return fmt.Sprintf(s, x)
}
func main() {
s := []int{1, 2, 3}
res := test("sum: %d", s...) // slice... 展开slice
println(res)
}
函数的用法
| 函数用法 | 描述 |
|---|---|
| 函数作为另外一个函数的实参 | 函数定义后可作为另外一个函数的实参数传入 |
| 闭包 | 闭包是匿名函数,可在动态编程中使用 |
| 方法 | 方法就是一个包含了接受者的函数 |
- 函数作为另外一个函数的实参
Go 语言可以很灵活的创建函数,并作为另外一个函数的实参 .
package main
import "fmt"
// 声明一个函数类型
type cb func(int) int
func main() {
testCallBack(1, callBack)
testCallBack(2, func(x int) int {
fmt.Printf("我是回调,x:%d\n", x)
return x
})
}
func testCallBack(x int, f cb) {
f(x)
}
func callBack(x int) int {
fmt.Printf("我是回调,x:%d\n", x)
return x
}
- 闭包
Go 语言支持匿名函数,可作为闭包。匿名函数是一个"内联"语句或表达式。匿名函数的优越性在于可以直接使用函数内的变量,不必申明。
package main
import "fmt"
// 闭包使用方法,函数声明中的返回值(闭包函数)不用写具体的形参名称
func add(x1, x2 int) func(int, int) (int, int, int) {
i := 0
return func(x3, x4 int) (int, int, int) {
i += 1
return i, x1 + x2, x3 + x4
}
}
func main() {
add_func := add(1, 2)
fmt.Println(add_func(4, 5))
fmt.Println(add_func(1, 3))
fmt.Println(add_func(2, 2))
}
- 方法
**Go 语言中同时有函数和方法。一个方法就是一个包含了接受者的函数,接受者可以是命名类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。 **
补充:
Go 没有面向对象,而我们知道常见的 Java。C++ 等语言中,实现类的方法做法都是编译器隐式的给函数加一个 this 指针,而在 Go 里,这个 this 指针需要明确的申明出来,其实和其它 OO 语言并没有很大的区别。
学习的例子:
package main
import (
"fmt"
)
/* 定义结构体 */
type Circle struct {
radius float64
}
func main() {
var c1 Circle
c1.radius = 10.00
fmt.Println("圆的面积 = ", c1.getArea())
}
//该 method 属于 Circle 类型对象中的方法
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
比较学习:
c++:
class Circle {
public:
float getArea() {
return 3.14 * radius * radius;
}
private:
float radius;
}
// 其中 getArea 经过编译器处理大致变为
float getArea(Circle *const c) {
...
}
Go中是:
func (c Circle) getArea() float64 {
//c.radius 即为 Circle 类型对象中的属性
return 3.14 * c.radius * c.radius
}
**关于值和指针,如果想在方法中改变结构体类型的属性,需要对方法传递指针,体会如下对结构体类型改变的方法 changRadis() 和普通的函数 change() 中的指针操作: **
package main
import (
"fmt"
)
/* 定义结构体 */
type Circle struct {
radius float64
}
func main() {
var c Circle
fmt.Println(c.radius)
c.radius = 10.00
fmt.Println(c.getArea())
c.changeRadius(20)
fmt.Println(c.radius)
change(&c, 30)
fmt.Println(c.radius)
}
func (c Circle) getArea() float64 {
return c.radius * c.radius
}
// 注意如果想要更改成功c的值,这里需要传指针
func (c *Circle) changeRadius(radius float64) {
c.radius = radius
}
// 以下操作将不生效
//func (c Circle) changeRadius(radius float64) {
// c.radius = radius
//}
// 引用类型要想改变值需要传指针
func change(c *Circle, radius float64) {
c.radius = radius
}
返回值
"_"标识符,用来忽略函数的某个返回值
Go 的返回值可以被命名,并且就像在函数体开头声明的变量那样使用。
返回值的名称应当具有一定的意义,可以作为文档使用。
没有参数的 return 语句返回各个返回变量的当前值。这种用法被称作“裸”返回。
直接返回语句仅应当用在像下面这样的短函数中。在长的函数中它们会影响代码的可读性。
package main
import (
"fmt"
)
func add(a, b int) (c int) {
c = a + b
return
}
func calc(a, b int) (sum int, avg int) {
sum = a + b
avg = (a + b) / 2
return
}
func main() {
var a, b int = 1, 2
c := add(a, b)
sum, avg := calc(a, b)
fmt.Println(a, b, c, sum, avg)
}
输出结果:
1 2 3 3 1
Golang返回值不能用容器对象接收多返回值。只能用多个变量,或 "_" 忽略。
package main
func test() (int, int) {
return 1, 2
}
func main() {
// s := make([]int, 2)
// s = test() // Error: multiple-value test() in single-value context
x, _ := test()
println(x)
}
输出结果:
1
多返回值可直接作为其他函数调用实参。
package main
func test() (int, int) {
return 1, 2
}
func add(x, y int) int {
return x + y
}
func sum(n ...int) int {
var x int
for _, i := range n {
x += i
}
return x
}
func main() {
println(add(test()))
println(sum(test()))
}
输出结果:
3
3
命名返回参数可看做与形参类似的局部变量,最后由 return 隐式返回。
package main
func add(x, y int) (z int) {
z = x + y
return
}
func main() {
println(add(1, 2))
}
输出结果:
3
命名返回参数可被同名局部变量遮蔽,此时需要显式返回。
func add(x, y int) (z int) {
{ // 不能在一个级别,引发 "z redeclared in this block" 错误。
var z = x + y
// return // Error: z is shadowed during return
return z // 必须显式返回。
}
}
命名返回参数允许 defer 延迟调用通过闭包读取和修改。
package main
func add(x, y int) (z int) {
defer func() {
z += 100
}()
z = x + y
return
}
func main() {
println(add(1, 2))
}
输出结果:
103
显式 return 返回前,会先修改命名返回参数。
package main
func add(x, y int) (z int) {
defer func() {
println(z) // 输出: 203
}()
z = x + y
return z + 200 // 执行顺序: (z = z + 200) -> (call defer) -> (return)
}
func main() {
println(add(1, 2)) // 输出: 203
}
输出结果:
203
203
函数类型
定义一个函数类型变量
type fun func(int,int)int
下面定义了两个函数:
func sum(a int,b int)int{
return a+b
}
func max(a int,b int)int{
if a>b{
return a
}else{
return b
}
}
下面定义一个主函数:
func main(){
var f fun
f = sum
s:=f(1,2)
fmt.Printf("s:%v\n",s)
f = max
m:=f(3,4)
fmt.Printf("m:%v\n",m)
}
匿名函数
匿名函数是指不需要定义函数名的一种函数实现方式。1958年LISP首先采用匿名函数。
在Go里面,函数可以像普通变量一样被传递或使用,Go语言支持随时在代码里定义匿名函数。
匿名函数由一个不带函数名的函数声明和函数体组成。匿名函数的优越性在于可以直接使用函数内的变量,不必申明。
package main
import (
"fmt"
"math"
)
func main() {
getSqrt := func(a float64) float64 {
return math.Sqrt(a)
}
fmt.Println(getSqrt(4))
}
上面先定义了一个名为getSqrt 的变量,初始化该变量时和之前的变量初始化有些不同,使用了func,func是定义函数的,可是这个函数和上面说的函数最大不同就是没有函数名,也就是匿名函数。这里将一个函数当做一个变量一样的操作。
Golang匿名函数可赋值给变量,做为结构字段,或者在 channel 里传送。
package main
func main() {
// --- function variable ---
fn := func() { println("Hello, World!") }
fn()
// --- function collection ---
fns := [](func(x int) int){
func(x int) int { return x + 1 },
func(x int) int { return x + 2 },
}
println(fns[0](100))
// --- function as field ---
d := struct {
fn func() string
}{
fn: func() string { return "Hello, World!" },
}
println(d.fn())
// --- channel of function ---
fc := make(chan func() string, 2)
fc <- func() string { return "Hello, World!" }
println((<-fc)())
}
输出结果:
Hello, World!
101
Hello, World!
Hello, World!
例子:
//自己调用自己
package main
import "fmt"
func main() {
r := func(a int, b int) int {
if a > b {
return a
} else {
return b
}
}(1, 2)
fmt.Printf("r: %v\n", r)
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
r: 2
[Done] exited with code=0 in 1.341 seconds
高阶函数
go语言的函数,可以作为函数的参数
作为参数
package main
import "fmt"
func sayHello (name string){
fmt.Printf("hello.%s",name)
}
func f1(namne string,f func(string)){
f(name)
}
func main(){
f1("tom",sayHello)
}
hello,tom
作为返回值
package main
import "fmt"
func add(x,y int)int{
return x+y
}
func sub (x,y int) int{
return x-y
}
func cal(operator string) func (int,int)int{
switch operator{
case "+":
return add
case "-":
return sub
default:
return nil
}
}
func main(){
add:= cal("+")
r:=add(1,2)
fmt.Printf("r:%v\n",r)
fmt.Println("--------------")
sub:= cal("-")
j:=sub(1,2)
fmt.Printf("j:%v\n",j)
}
Go的闭包
定义在一个函数内部的函数,一个函数有一个返回值,返回值是一个函数。
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单而言,闭包=函数+引用环境
例子--认识闭包
package main
import "fmt"
func add() func(y int) int {
var x int
return func(y int) int {
x += y
return x
}
}
func main() {
f := add()
r := f(10)
fmt.Printf("r: %v\n", r)
r = f(20)
fmt.Printf("r: %v\n", r)
r = f(30)
fmt.Printf("r: %v\n", r)
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
r: 10
r: 30
r: 60
[Done] exited with code=0 in 5.847 seconds
变量f是一个函数并且它引用了其外部作用域中的x变量,此时的f就是一个闭包。在f的生命周期内,变量x也一直有效。
例子--拼接前缀
package main
import (
"fmt"
"strings"
)
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func main() {
jpgFunc := makeSuffixFunc(".jpg")
txtFunc := makeSuffixFunc(".txt")
fmt.Printf("jpgFunc(\"test\"): %v\n", jpgFunc("test"))
fmt.Printf("txtFunc(\"test\"): %v\n", txtFunc("test"))
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
jpgFunc("test"): test.jpg
txtFunc("test"): test.txt
[Done] exited with code=0 in 1.338 seconds
例子--多返回值函数
package main
import "fmt"
func calc(base int) (func(int) int, func(int) int) {
add := func(i int) int {
base += i
return base
}
sub := func(i int) int {
base -= i
return base
}
return add, sub
}
func main() {
f1, f2 := calc(10)
fmt.Println(f1(1), f2(5))
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
11 6
[Done] exited with code=0 in 3.701 seconds
闭包的应该都听过,但到底什么是闭包呢?
闭包是由函数及其相关引用环境组合而成的实体(即:闭包=函数+引用环境)。
“官方”的解释是:所谓“闭包”,指的是一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
维基百科讲,闭包(Closure),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
看着上面的描述,会发现闭包和匿名函数似乎有些像。可是可能还是有些云里雾里的。因为跳过闭包的创建过程直接理解闭包的定义是非常困难的。目前在JavaScript、Go、PHP、Scala、Scheme、Common Lisp、Smalltalk、Groovy、Ruby、 Python、Lua、objective c、Swift 以及Java8以上等语言中都能找到对闭包不同程度的支持。通过支持闭包的语法可以发现一个特点,他们都有垃圾回收(GC)机制。
package main
import (
"fmt"
)
func a() func() int {
i := 0
b := func() int {
i++
fmt.Println(i)
return i
}
return b
}
func main() {
c := a()
c()
c()
c()
a() //不会输出i
}
输出结果:
1
2
3
包复制的是原对象指针,这就很容易解释延迟引用现象。
基本例子
package main
import "fmt"
func test() func() {
x := 100
fmt.Printf("x (%p) = %d\n", &x, x)
return func() {
fmt.Printf("x (%p) = %d\n", &x, x)
}
}
func main() {
f := test()
f()
}
输出:
x (0xc42007c008) = 100
x (0xc42007c008) = 100
在汇编层 ,test 实际返回的是 FuncVal 对象,其中包含了匿名函数地址、闭包对象指针。当调 匿名函数时,只需以某个寄存器传递该对象即可。
FuncVal { func_address, closure_var_pointer ... }
外部引用函数参数局部变量
package main
import "fmt"
// 外部引用函数参数局部变量
func add(base int) func(int) int {
return func(i int) int {
base += i
return base
}
}
func main() {
tmp1 := add(10)
fmt.Println(tmp1(1), tmp1(2))
// 此时tmp1和tmp2不是一个实体了
tmp2 := add(100)
fmt.Println(tmp2(1), tmp2(2))
}
返回2个闭包
package main
import "fmt"
// 返回2个函数类型的返回值
func test01(base int) (func(int) int, func(int) int) {
// 定义2个函数,并返回
// 相加
add := func(i int) int {
base += i
return base
}
// 相减
sub := func(i int) int {
base -= i
return base
}
// 返回
return add, sub
}
func main() {
f1, f2 := test01(10)
// base一直是没有消
fmt.Println(f1(1), f2(2))
// 此时base是9
fmt.Println(f1(3), f2(4))
}
Go语言递归调用
- 递归就是自己调用自己
- 必须先定义函数的退出条件,没有退出条件,递归将成为死循环
- go语言递归函数很可能会产生一大堆的goroutine,也很可能出现栈空间内存溢出问题
递归,就是在运行的过程中调用自己。
语法格式如下:
func recursion() {
recursion() /* 函数调用自身 */
}
func main() {
recursion()
}
阶乘
package main
import "fmt"
func number_x(a int) int {
if a == 1 {
return 1
} else {
return a * number_x(a-1)
}
}
func main() {
fmt.Printf("number_x(5): %v\n", number_x(5))
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
number_x(5): 120
[Done] exited with code=0 in 2.634 seconds
斐波那契数列
package main
import "fmt"
func fibonacci(n int) int {
if n < 2 {
return n
}
return fibonacci(n-2) + fibonacci(n-1)
}
func main() {
var i int
for i = 0; i < 10; i++ {
fmt.Printf("%d\t", fibonacci(i))
}
}
补充-小例子
杨辉三角
杨辉三角形:
package main
import "fmt"
//行数
const LINES int = 10
// 杨辉三角
func ShowYangHuiTriangle() {
nums := []int{}
for i := 0; i < LINES; i++ {
//补空白
for j := 0; j < (LINES - i); j++ {
fmt.Print(" ")
}
for j := 0; j < (i + 1); j++ {
var length = len(nums)
var value int
if j == 0 || j == i {
value = 1
} else {
value = nums[length-i] + nums[length-i-1]
}
nums = append(nums, value)
fmt.Print(value, " ")
}
fmt.Println("")
}
}
func main() {
ShowYangHuiTriangle()
}
执行输出结果为:
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
1 8 28 56 70 56 28 8 1
1 9 36 84 126 126 84 36 9 1
99乘法表
九九乘法表
package main
import (
"fmt"
"strconv"
)
func add(a, b int) int {
return a + b
}
func multiplicationTable() {
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
var ret string
if i*j < 10 && j != 1 {
ret = " " + strconv.Itoa(i*j)
} else {
ret = strconv.Itoa(i * j)
}
fmt.Print(j, " * ", i, " = ", ret, " ")
}
fmt.Print("\n")
}
}
func main() {
multiplicationTable()
}
执行输出为:
1 * 1 = 1
1 * 2 = 2 2 * 2 = 4
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
菱形
菱形
package main
import "fmt"
func main() {
// 长
x := 9
// 宽
y := 9
// 行数
row := 1
for row <= y {
// 计算每行得星星数
count := 0
if row <= (y/2 + 1) {
count = (2 * row - 1)
} else {
count = 2 * (y - row) + 1
}
row++
text := ""
// 算出显示星星的范围
star_min := ((x - count) / 2) + 1
star_max := ((x - count) / 2) + count
for index := 1;index <= x;index++ {
if index >= star_min && index <= star_max {
text += "*"
} else {
text += " "
}
}
fmt.Println(text)
}
}
计算结果:
*
***
*****
*******
*********
*******
*****
***
*
值传递
所有参数都是值传递:slice,map,channel 会有传引用的错觉(比如切片,他背后对应的是一个数组,切片本身是一个数据结构,在这个数据结构中包含了指向了这个数组的指针。所以说,即便是在传值的情况下这个结构被复制到函数里了,在通过指针去操作这个数组的值的时候,其实是操作的是同一块空间,实际上是结构被复制了,但是结构里包含的指针指向的是同一个数组,所以才有这个错觉)
延迟调用
defer特性:
执行顺序是栈
1. 关键字 defer 用于注册延迟调用。
2. 这些调用直到 return 前才被执。因此,可以用来做资源清理。
3. 多个defer语句,按先进后出的方式执行。
4. defer语句中的变量,在defer声明时就决定了。
defer用途:
1. 关闭文件句柄
2. 锁资源释放
3. 数据库连接释放
go语言 defer
go 语言的defer功能强大,对于资源管理非常方便,但是如果没用好,也会有陷阱。
defer 是先进后出
这个很自然,后面的语句会依赖前面的资源,因此如果先前面的资源先释放了,后面的语句就没法执行了。
package main
import "fmt"
func main() {
var whatever [5]struct{}
for i := range whatever {
defer fmt.Println(i)
}
}
输出结果:
4
3
2
1
0
碰上闭包
package main
import "fmt"
func main() {
var whatever [5]struct{}
for i := range whatever {
defer func() { fmt.Println(i) }()
}
}
输出结果:
4
4
4
4
4
其实go说的很清楚,我们一起来看看go spec如
Each time a "defer" statement executes, the function value and parameters to the call are evaluated as usualand saved anew but the actual function is not invoked.
也就是说函数正常执行,由于闭包用到的变量 i 在执行的时候已经变成4,所以输出全都是4.
Close
这个大家用的都很频繁,但是go语言编程举了一个可能一不小心会犯错的例子.
package main
import "fmt"
type Test struct {
name string
}
func (t *Test) Close() {
fmt.Println(t.name, " closed")
}
func main() {
ts := []Test{{"a"}, {"b"}, {"c"}}
for _, t := range ts {
defer t.Close()
}
}
输出结果:
c closed
c closed
c closed
这个输出并不会像我们预计的输出c b a,而是输出c c c
可是按照前面的go spec中的说明,应该输出c b a才对啊.
那我们换一种方式来调用一下.
package main
import "fmt"
type Test struct {
name string
}
func (t *Test) Close() {
fmt.Println(t.name, " closed")
}
func Close(t Test) {
t.Close()
}
func main() {
ts := []Test{{"a"}, {"b"}, {"c"}}
for _, t := range ts {
defer Close(t)
}
}
输出结果:
c closed
b closed
a closed
这个时候输出的就是c b a
当然,如果你不想多写一个函数,也很简单,可以像下面这样,同样会输出c b a
看似多此一举的声明
package main
import "fmt"
type Test struct {
name string
}
func (t *Test) Close() {
fmt.Println(t.name, " closed")
}
func main() {
ts := []Test{{"a"}, {"b"}, {"c"}}
for _, t := range ts {
t2 := t
defer t2.Close()
}
}
输出结果:
c closed
b closed
a closed
通过以上例子,结合
Each time a "defer" statement executes, the function value and parameters to the call are evaluated as usualand saved anew but the actual function is not invoked.
这句话。可以得出下面的结论:
defer后面的语句在执行的时候,函数调用的参数会被保存起来,但是不执行。也就是复制了一份。但是并没有说struct这里的this指针如何处理,通过这个例子可以看出go语言并没有把这个明确写出来的this指针当作参数来看待。
defer陷阱
defer 与 closure
package main
import (
"errors"
"fmt"
)
func foo(a, b int) (i int, err error) {
defer fmt.Printf("first defer err %v\n", err)
defer func(err error) { fmt.Printf("second defer err %v\n", err) }(err)
defer func() { fmt.Printf("third defer err %v\n", err) }()
if b == 0 {
err = errors.New("divided by zero!")
return
}
i = a / b
return
}
func main() {
foo(2, 0)
}
输出结果:
third defer err divided by zero!
second defer err <nil>
first defer err <nil>
解释:如果 defer 后面跟的不是一个 closure 最后执行的时候我们得到的并不是最新的值。
defer 与 return
package main
import "fmt"
func foo() (i int) {
i = 0
defer func() {
fmt.Println(i)
}()
return 2
}
func main() {
foo()
}
输出结果:
2
解释:在有具名返回值的函数中(这里具名返回值为 i),执行 return 2 的时候实际上已经将 i 的值重新赋值为 2。所以defer closure 输出结果为 2 而不是 1。
defer nil 函数
package main
import (
"fmt"
)
func test() {
var run func() = nil
defer run()
fmt.Println("runs")
}
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
test()
}
输出结果:
runs
runtime error: invalid memory address or nil pointer dereference
解释:名为 test 的函数一直运行至结束,然后 defer 函数会被执行且会因为值为 nil 而产生 panic 异常。然而值得注意的是,run() 的声明是没有问题,因为在test函数运行完成后它才会被调用。
在错误的位置使用 defer
当 http.Get 失败时会抛出异常。
package main
import "net/http"
func do() error {
res, err := http.Get("http://www.google.com")
defer res.Body.Close()
if err != nil {
return err
}
// ..code...
return nil
}
func main() {
do()
}
输出结果:
panic: runtime error: invalid memory address or nil pointer dereference
因为在这里我们并没有检查我们的请求是否成功执行,当它失败的时候,我们访问了 Body 中的空变量 res ,因此会抛出异常
解决方案
总是在一次成功的资源分配下面使用 defer ,对于这种情况来说意味着:当且仅当 http.Get 成功执行时才使用 defer
package main
import "net/http"
func do() error {
res, err := http.Get("http://xxxxxxxxxx")
if res != nil {
defer res.Body.Close()
}
if err != nil {
return err
}
// ..code...
return nil
}
func main() {
do()
}
在上述的代码中,当有错误的时候,err 会被返回,否则当整个函数返回的时候,会关闭 res.Body 。
解释:在这里,你同样需要检查 res 的值是否为 nil ,这是 http.Get 中的一个警告。通常情况下,出错的时候,返回的内容应为空并且错误会被返回,可当你获得的是一个重定向 error 时, res 的值并不会为 nil ,但其又会将错误返回。上面的代码保证了无论如何 Body 都会被关闭,如果你没有打算使用其中的数据,那么你还需要丢弃已经接收的数据。
不检查错误
在这里,f.Close() 可能会返回一个错误,可这个错误会被我们忽略掉
package main
import "os"
func do() error {
f, err := os.Open("book.txt")
if err != nil {
return err
}
if f != nil {
defer f.Close()
}
// ..code...
return nil
}
func main() {
do()
}
改进一下
package main
import "os"
func do() error {
f, err := os.Open("book.txt")
if err != nil {
return err
}
if f != nil {
defer func() {
if err := f.Close(); err != nil {
// log etc
}
}()
}
// ..code...
return nil
}
func main() {
do()
}
再改进一下
通过命名的返回变量来返回 defer 内的错误。
package main
import "os"
func do() (err error) {
f, err := os.Open("book.txt")
if err != nil {
return err
}
if f != nil {
defer func() {
if ferr := f.Close(); ferr != nil {
err = ferr
}
}()
}
// ..code...
return nil
}
func main() {
do()
}
释放相同的资源
如果你尝试使用相同的变量释放不同的资源,那么这个操作可能无法正常执行。
package main
import (
"fmt"
"os"
)
func do() error {
f, err := os.Open("book.txt")
if err != nil {
return err
}
if f != nil {
defer func() {
if err := f.Close(); err != nil {
fmt.Printf("defer close book.txt err %v\n", err)
}
}()
}
// ..code...
f, err = os.Open("another-book.txt")
if err != nil {
return err
}
if f != nil {
defer func() {
if err := f.Close(); err != nil {
fmt.Printf("defer close another-book.txt err %v\n", err)
}
}()
}
return nil
}
func main() {
do()
}
输出结果: defer close book.txt err close ./another-book.txt: file already closed
当延迟函数执行时,只有最后一个变量会被用到,因此,f 变量 会成为最后那个资源 (another-book.txt)。而且两个 defer 都会将这个资源作为最后的资源来关闭
解决方案:
package main
import (
"fmt"
"io"
"os"
)
func do() error {
f, err := os.Open("book.txt")
if err != nil {
return err
}
if f != nil {
defer func(f io.Closer) {
if err := f.Close(); err != nil {
fmt.Printf("defer close book.txt err %v\n", err)
}
}(f)
}
// ..code...
f, err = os.Open("another-book.txt")
if err != nil {
return err
}
if f != nil {
defer func(f io.Closer) {
if err := f.Close(); err != nil {
fmt.Printf("defer close another-book.txt err %v\n", err)
}
}(f)
}
return nil
}
func main() {
do()
}
异常处理
Golang 没有结构化异常,使用 panic 抛出错误,recover 捕获错误。
异常的使用场景简单描述:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理。
panic:
1、内置函数
2、假如函数F中书写了panic语句,会终止其后要执行的代码,在panic所在函数F内如果存在要执行的defer函数列表,按照defer的逆序执行
3、返回函数F的调用者G,在G中,调用函数F语句之后的代码不会执行,假如函数G中存在要执行的defer函数列表,按照defer的逆序执行
4、直到goroutine整个退出,并报告错误
recover:
1、内置函数
2、用来控制一个goroutine的panicking行为,捕获panic,从而影响应用的行为
3、一般的调用建议
a). 在defer函数中,通过recever来终止一个goroutine的panicking过程,从而恢复正常代码的执行
b). 可以获取通过panic传递的error
注意:
1.利用recover处理panic指令,defer 必须放在 panic 之前定义,另外 recover 只有在 defer 调用的函数中才有效。否则当panic时,recover无法捕获到panic,无法防止panic扩散。
2.recover 处理异常后,逻辑并不会恢复到 panic 那个点去,函数跑到 defer 之后的那个点。
3.多个 defer 会形成 defer 栈,后定义的 defer 语句会被最先调用。
package main
func main() {
test()
}
func test() {
defer func() {
if err := recover(); err != nil {
println(err.(string)) // 将 interface{} 转型为具体类型。
}
}()
panic("panic error!")
}
输出结果:
panic error!
由于 panic、recover 参数类型为 interface{},因此可抛出任何类型对象。
func panic(v interface{})
func recover() interface{}
向已关闭的通道发送数据会引发panic
package main
import (
"fmt"
)
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
var ch chan int = make(chan int, 10)
close(ch)
ch <- 1
}
输出结果:
send on closed channel
延迟调用中引发的错误,可被后续延迟调用捕获,但仅最后一个错误可被捕获。
package main
import "fmt"
func test() {
defer func() {
fmt.Println(recover())
}()
defer func() {
panic("defer panic")
}()
panic("test panic")
}
func main() {
test()
}
输出:
defer panic
捕获函数 recover 只有在延迟调用内直接调用才会终止错误,否则总是返回 nil。任何未捕获的错误都会沿调用堆栈向外传递。
package main
import "fmt"
func test() {
defer func() {
fmt.Println(recover()) //有效
}()
defer recover() //无效!
defer fmt.Println(recover()) //无效!
defer func() {
func() {
println("defer inner")
recover() //无效!
}()
}()
panic("test panic")
}
func main() {
test()
}
输出:
defer inner
<nil>
test panic
使用延迟匿名函数或下面这样都是有效的。
package main
import (
"fmt"
)
func except() {
fmt.Println(recover())
}
func test() {
defer except()
panic("test panic")
}
func main() {
test()
}
输出结果:
test panic
如果需要保护代码 段,可将代码块重构成匿名函数,如此可确保后续代码被执 。
package main
import "fmt"
func test(x, y int) {
var z int
func() {
defer func() {
if recover() != nil {
z = 0
}
}()
panic("test panic")
z = x / y
return
}()
fmt.Printf("x / y = %d\n", z)
}
func main() {
test(2, 1)
}
输出结果:
x / y = 0
除用 panic 引发中断性错误外,还可返回 error 类型错误对象来表示函数调用状态。
type error interface {
Error() string
}
标准库 errors.New 和 fmt.Errorf 函数用于创建实现 error 接口的错误对象。通过判断错误对象实例来确定具体错误类型。
package main
import (
"errors"
"fmt"
)
var ErrDivByZero = errors.New("division by zero")
func div(x, y int) (int, error) {
if y == 0 {
return 0, ErrDivByZero
}
return x / y, nil
}
func main() {
defer func() {
fmt.Println(recover())
}()
switch z, err := div(10, 0); err {
case nil:
println(z)
case ErrDivByZero:
panic(err)
}
}
输出结果:
division by zero
Go实现类似 try catch 的异常处理
package main
import "fmt"
func Try(fun func(), handler func(interface{})) {
defer func() {
if err := recover(); err != nil {
handler(err)
}
}()
fun()
}
func main() {
Try(func() {
panic("test panic")
}, func(err interface{}) {
fmt.Println(err)
})
}
输出结果:
test panic
如何区别使用 panic 和 error 两种方式?
惯例是:导致关键流程出现不可修复性错误的使用 panic,其他使用 error。
Go 错误处理
Go 语言通过内置的错误接口提供了非常简单的错误处理机制。
error类型是一个接口类型,这是它的定义:
type error interface {
Error() string
}
我们可以在编码中通过实现 error 接口类型来生成错误信息。
函数通常在最后的返回值中返回错误信息。使用errors.New 可返回一个错误信息:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New("math: square root of negative number")
}
// 实现
}
在下面的例子中,我们在调用Sqrt的时候传递的一个负数,然后就得到了non-nil的error对象,将此对象与nil比较,结果为true,所以fmt.Println(fmt包在处理error时会调用Error方法)被调用,以输出错误,请看下面调用的示例代码:
result, err:= Sqrt(-1)
if err != nil {
fmt.Println(err)
}
例子:
package main
import (
"fmt"
)
// 定义一个 DivideError 结构
type DivideError struct {
dividee int
divider int
}
// 实现 `error` 接口
func (de *DivideError) Error() string {
strFormat := `
Cannot proceed, the divider is zero.
dividee: %d
divider: 0
`
return fmt.Sprintf(strFormat, de.dividee)
}
// 定义 `int` 类型除法运算的函数
func Divide(varDividee int, varDivider int) (result int, errorMsg string) {
if varDivider == 0 {
dData := DivideError{
dividee: varDividee,
divider: varDivider,
}
errorMsg = dData.Error()
return
} else {
return varDividee / varDivider, ""
}
}
func main() {
// 正常情况
if result, errorMsg := Divide(100, 10); errorMsg == "" {
fmt.Println("100/10 = ", result)
}
// 当除数为零的时候会返回错误信息
if _, errorMsg := Divide(100, 0); errorMsg != "" {
fmt.Println("errorMsg is: ", errorMsg)
}
}
单元测试
go test工具
Go语言中的测试依赖go test命令。编写测试代码和编写普通的Go代码过程是类似的,并不需要学习新的语法、规则或工具。
go test命令是一个按照一定约定和组织的测试代码的驱动程序。在包目录内,所有以_test.go为后缀名的源代码文件都是go test测试的一部分,不会被go build编译到最终的可执行文件中。
在*_test.go文件中有三种类型的函数,单元测试函数、基准测试函数和示例函数。
| 类型 | 格式 | 作用 |
|---|---|---|
| 测试函数 | 函数名前缀为Test | 测试程序的一些逻辑行为是否正确 |
| 基准函数 | 函数名前缀为Benchmark | 测试函数的性能 |
| 示例函数 | 函数名前缀为Example | 为文档提供示例文档 |
go test命令会遍历所有的*_test.go文件中符合上述命名规则的函数,然后生成一个临时的main包用于调用相应的测试函数,然后构建并运行、报告测试结果,最后清理测试中生成的临时文件。
Golang单元测试对文件名和方法名,参数都有很严格的要求。
1、文件名必须以xx_test.go命名
2、方法必须是Test[^a-z]开头
3、方法参数必须 t *testing.T
4、使用go test执行单元测试
go test的参数解读:
go test是go语言自带的测试工具,其中包含的是两类,单元测试和性能测试
通过go help test可以看到go test的使用说明:
格式形如: go test [-c][-i] [build flags][packages] [flags for test binary]
参数解读:
-c : 编译go test成为可执行的二进制文件,但是不运行测试。
-i : 安装测试包依赖的package,但是不运行测试。
关于build flags,调用go help build,这些是编译运行过程中需要使用到的参数,一般设置为空
关于packages,调用go help packages,这些是关于包的管理,一般设置为空
关于flags for test binary,调用go help testflag,这些是go test过程中经常使用到的参数
-test.v : 是否输出全部的单元测试用例(不管成功或者失败),默认没有加上,所以只输出失败的单元测试用例。
-test.run pattern: 只跑哪些单元测试用例
-test.bench patten: 只跑那些性能测试用例
-test.benchmem : 是否在性能测试的时候输出内存情况
-test.benchtime t : 性能测试运行的时间,默认是1s
-test.cpuprofile cpu.out : 是否输出cpu性能分析文件
-test.memprofile mem.out : 是否输出内存性能分析文件
-test.blockprofile block.out : 是否输出内部goroutine阻塞的性能分析文件
-test.memprofilerate n : 内存性能分析的时候有一个分配了多少的时候才打点记录的问题。这个参数就是设置打点的内存分配间隔,也就是profile中一个sample代表的内存大小。默认是设置为512 * 1024的。如果你将它设置为1,则每分配一个内存块就会在profile中有个打点,那么生成的profile的sample就会非常多。如果你设置为0,那就是不做打点了。
你可以通过设置memprofilerate=1和GOGC=off来关闭内存回收,并且对每个内存块的分配进行观察。
-test.blockprofilerate n: 基本同上,控制的是goroutine阻塞时候打点的纳秒数。默认不设置就相当于-test.blockprofilerate=1,每一纳秒都打点记录一下
-test.parallel n : 性能测试的程序并行cpu数,默认等于GOMAXPROCS。
-test.timeout t : 如果测试用例运行时间超过t,则抛出panic
-test.cpu 1,2,4 : 程序运行在哪些CPU上面,使用二进制的1所在位代表,和nginx的nginx_worker_cpu_affinity是一个道理
-test.short : 将那些运行时间较长的测试用例运行时间缩短
目录结构:
test
|
—— calc.go
|
—— calc_test.go
Go语言的继承-多态
继承
package main
import "fmt"
type Animal struct {
name string
action string
}
func (this *Animal) Talk() {
fmt.Printf("名字是%s,行为是%s", this.name, this.action)
fmt.Println()
}
type Brid struct {
Animal
body string
}
// func (this *Brid) Talk() {
// fmt.Printf("名字是%s,行为是%s,动物是%s", this.name, this.action, this.body)
// fmt.Println()
// }
func (this *Brid) Fly() {
fmt.Printf("名字是%s,会飞", this.name)
fmt.Println()
}
func main() {
var father Animal
father.name = "动物"
father.action = "正常"
father.Talk()
var children Brid
children.name = "小鸟"
children.action = "飞"
children.body = "小"
children.Talk()
children.Fly()
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
名字是动物,行为是正常
名字是小鸟,行为是飞
名字是小鸟,会飞
[Done] exited with code=0 in 2.028 seconds
[Running] go run "d:\桌面\GOlearn\test\main.go"
名字是动物,行为是正常
名字是小鸟,行为是飞,动物是小
名字是小鸟,会飞
[Done] exited with code=0 in 0.731 seconds
多态
package main
import "fmt"
//接口
type Animal interface {
Sleep()
GetColor() string
GetType()
}
//具体类
type Cat struct {
color string
}
func (this *Cat) Sleep() {
fmt.Print("小猫睡觉")
}
func (this *Cat) GetColor() string {
return this.color
}
func (this *Cat) GetType() {
fmt.Print("当前是一只猫")
}
func main() {
var i Animal = &Cat{"cat"}
fmt.Print("animal is ", i.GetColor())
fmt.Println()
i.Sleep()
fmt.Println()
i.GetType()
}
[Running] go run "d:\桌面\GOlearn\test\main.go"
animal is cat
小猫睡觉
当前是一只猫
[Done] exited with code=0 in 1.841 seconds
Go module
使用方法
- 初始化模块
go mod init <项目模块名称>
- 依据依赖关系处理,根据go.mod文件
go mod tidy
- 将依赖包复制到项目的vendor目录下
go mod vendor
如果包被屏蔽(墙),可以用这个命令,随后使用go build -mod=vendor编译
- 显示依赖关系
go list -m all
- 显示详细的依赖关系
go list -m -json all
- 下载依赖
go mod download [path@version]
.
方法
方法定义
Golang 方法总是绑定对象实例,并隐式将实例作为第一实参 (receiver)。
• 只能为当前包内命名类型定义方法。
• 参数 receiver 可任意命名。如方法中未曾使用 ,可省略参数名。
• 参数 receiver 类型可以是 T 或 *T。基类型 T 不能是接口或指针。
• 不支持方法重载,receiver 只是参数签名的组成部分。
• 可用实例 value 或 pointer 调用全部方法,编译器自动转换。
一个方法就是一个包含了接受者的函数,接受者可以是命名类型或者结构体类型的一个值或者是一个指针。
所有给定类型的方法属于该类型的方法集。
例子
func (recevier type) methodName(参数列表)(返回值列表){}
参数和返回值可以省略
package main
type Test struct{}
// 无参数、无返回值
func (t Test) method0() {
}
// 单参数、无返回值
func (t Test) method1(i int) {
}
// 多参数、无返回值
func (t Test) method2(x, y int) {
}
// 无参数、单返回值
func (t Test) method3() (i int) {
return
}
// 多参数、多返回值
func (t Test) method4(x, y int) (z int, err error) {
return
}
// 无参数、无返回值
func (t *Test) method5() {
}
// 单参数、无返回值
func (t *Test) method6(i int) {
}
// 多参数、无返回值
func (t *Test) method7(x, y int) {
}
// 无参数、单返回值
func (t *Test) method8() (i int) {
return
}
// 多参数、多返回值
func (t *Test) method9(x, y int) (z int, err error) {
return
}
func main() {}
下面定义一个结构体类型和该类型的一个方法:
package main
import (
"fmt"
)
//结构体
type User struct {
Name string
Email string
}
//方法
func (u User) Notify() {
fmt.Printf("%v : %v \n", u.Name, u.Email)
}
func main() {
// 值类型调用方法
u1 := User{"golang", "golang@golang.com"}
u1.Notify()
// 指针类型调用方法
u2 := User{"go", "go@go.com"}
u3 := &u2
u3.Notify()
}
输出结果:
golang : golang@golang.com
go : go@go.com
解释: 首先我们定义了一个叫做 User 的结构体类型,然后定义了一个该类型的方法叫做 Notify,该方法的接受者是一个 User 类型的值。要调用 Notify 方法我们需要一个 User 类型的值或者指针。
在这个例子中当我们使用指针时,Go 调整和解引用指针使得调用可以被执行。注意,当接受者不是一个指针时,该方法操作对应接受者的值的副本(意思就是即使你使用了指针调用函数,但是函数的接受者是值类型,所以函数内部操作还是对副本的操作,而不是指针操作。
我们修改 Notify 方法,让它的接受者使用指针类型:
package main
import (
"fmt"
)
//结构体
type User struct {
Name string
Email string
}
//方法
func (u *User) Notify() {
fmt.Printf("%v : %v \n", u.Name, u.Email)
}
func main() {
// 值类型调用方法
u1 := User{"golang", "golang@golang.com"}
u1.Notify()
// 指针类型调用方法
u2 := User{"go", "go@go.com"}
u3 := &u2
u3.Notify()
}
输出结果:
golang : golang@golang.com
go : go@go.com
注意:当接受者是指针时,即使用值类型调用那么函数内部也是对指针的操作。
方法不过是一种特殊的函数,只需将其还原,就知道 receiver T 和 *T 的差别。
package main
import "fmt"
type Data struct {
x int
}
func (self Data) ValueTest() { // func ValueTest(self Data);
fmt.Printf("Value: %p\n", &self)
}
func (self *Data) PointerTest() { // func PointerTest(self *Data);
fmt.Printf("Pointer: %p\n", self)
}
func main() {
d := Data{}
p := &d
fmt.Printf("Data: %p\n", p)
d.ValueTest() // ValueTest(d)
d.PointerTest() // PointerTest(&d)
p.ValueTest() // ValueTest(*p)
p.PointerTest() // PointerTest(p)
}
输出:
Data: 0xc42007c008
Value: 0xc42007c018
Pointer: 0xc42007c008
Value: 0xc42007c020
Pointer: 0xc42007c008
普通函数与方法的区别
1.对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然。
2.对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
package main
//普通函数与方法的区别(在接收者分别为值类型和指针类型的时候)
import (
"fmt"
)
//1.普通函数
//接收值类型参数的函数
func valueIntTest(a int) int {
return a + 10
}
//接收指针类型参数的函数
func pointerIntTest(a *int) int {
return *a + 10
}
func structTestValue() {
a := 2
fmt.Println("valueIntTest:", valueIntTest(a))
//函数的参数为值类型,则不能直接将指针作为参数传递
//fmt.Println("valueIntTest:", valueIntTest(&a))
//compile error: cannot use &a (type *int) as type int in function argument
b := 5
fmt.Println("pointerIntTest:", pointerIntTest(&b))
//同样,当函数的参数为指针类型时,也不能直接将值类型作为参数传递
//fmt.Println("pointerIntTest:", pointerIntTest(b))
//compile error:cannot use b (type int) as type *int in function argument
}
//2.方法
type PersonD struct {
id int
name string
}
//接收者为值类型
func (p PersonD) valueShowName() {
fmt.Println(p.name)
}
//接收者为指针类型
func (p *PersonD) pointShowName() {
fmt.Println(p.name)
}
func structTestFunc() {
//值类型调用方法
personValue := PersonD{101, "hello world"}
personValue.valueShowName()
personValue.pointShowName()
//指针类型调用方法
personPointer := &PersonD{102, "hello golang"}
personPointer.valueShowName()
personPointer.pointShowName()
//与普通函数不同,接收者为指针类型和值类型的方法,指针类型和值类型的变量均可相互调用
}
func main() {
structTestValue()
structTestFunc()
}
输出结果:
valueIntTest: 12
pointerIntTest: 15
hello world
hello world
hello golang
hello golang
匿名字段
Golang匿名字段 :可以像字段成员那样访问匿名字段方法,编译器负责查找。
package main
import "fmt"
type User struct {
id int
name string
}
type Manager struct {
User
}
func (self *User) ToString() string { // receiver = &(Manager.User)
return fmt.Sprintf("User: %p, %v", self, self)
}
func main() {
m := Manager{User{1, "Tom"}}
fmt.Printf("Manager: %p\n", &m)
fmt.Println(m.ToString())
}
输出结果:
Manager: 0xc42000a060
User: 0xc42000a060, &{1 Tom}
通过匿名字段,可获得和继承类似的复用能力。依据编译器查找次序,只需在外层定义同名方法,就可以实现 "override"。
package main
import "fmt"
type User struct {
id int
name string
}
type Manager struct {
User
title string
}
func (self *User) ToString() string {
return fmt.Sprintf("User: %p, %v", self, self)
}
func (self *Manager) ToString() string {
return fmt.Sprintf("Manager: %p, %v", self, self)
}
func main() {
m := Manager{User{1, "Tom"}, "Administrator"}
fmt.Println(m.ToString())
fmt.Println(m.User.ToString())
}
输出结果:
Manager: 0xc420074180, &{{1 Tom} Administrator}
User: 0xc420074180, &{1 Tom}
方法集
Golang方法集 :每个类型都有与之关联的方法集,这会影响到接口实现规则。
• 类型 T 方法集包含全部 receiver T 方法。
• 类型 *T 方法集包含全部 receiver T + *T 方法。
• 如类型 S 包含匿名字段 T,则 S 和 *S 方法集包含 T 方法。
• 如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 T + *T 方法。
• 不管嵌入 T 或 *T,*S 方法集总是包含 T + *T 方法。
用实例 value 和 pointer 调用方法 (含匿名字段) 不受方法集约束,编译器总是查找全部方法,并自动转换 receiver 实参。
Go 语言中内部类型方法集提升的规则:
类型 T 方法集包含全部 receiver T 方法。
package main
import (
"fmt"
)
type T struct {
int
}
func (t T) test() {
fmt.Println("类型 T 方法集包含全部 receiver T 方法。")
}
func main() {
t1 := T{1}
fmt.Printf("t1 is : %v\n", t1)
t1.test()
}
输出结果:
t1 is : {1}
类型 T 方法集包含全部 receiver T 方法。
类型 *T 方法集包含全部 receiver T + *T 方法。
package main
import (
"fmt"
)
type T struct {
int
}
func (t T) testT() {
fmt.Println("类型 *T 方法集包含全部 receiver T 方法。")
}
func (t *T) testP() {
fmt.Println("类型 *T 方法集包含全部 receiver *T 方法。")
}
func main() {
t1 := T{1}
t2 := &t1
fmt.Printf("t2 is : %v\n", t2)
t2.testT()
t2.testP()
}
输出结果:
t2 is : &{1}
类型 *T 方法集包含全部 receiver T 方法。
类型 *T 方法集包含全部 receiver *T 方法。
给定一个结构体类型 S 和一个命名为 T 的类型,方法提升像下面规定的这样被包含在结构体方法集中:
如类型 S 包含匿名字段 T,则 S 和 *S 方法集包含 T 方法。
这条规则说的是当我们嵌入一个类型,嵌入类型的接受者为值类型的方法将被提升,可以被外部类型的值和指针调用。
package main
import (
"fmt"
)
type S struct {
T
}
type T struct {
int
}
func (t T) testT() {
fmt.Println("如类型 S 包含匿名字段 T,则 S 和 *S 方法集包含 T 方法。")
}
func main() {
s1 := S{T{1}}
s2 := &s1
fmt.Printf("s1 is : %v\n", s1)
s1.testT()
fmt.Printf("s2 is : %v\n", s2)
s2.testT()
}
输出结果:
s1 is : {{1}}
如类型 S 包含匿名字段 T,则 S 和 *S 方法集包含 T 方法。
s2 is : &{{1}}
如类型 S 包含匿名字段 T,则 S 和 *S 方法集包含 T 方法。
如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 T + *T 方法。
这条规则说的是当我们嵌入一个类型的指针,嵌入类型的接受者为值类型或指针类型的方法将被提升,可以被外部类型的值或者指针调用。
package main
import (
"fmt"
)
type S struct {
T
}
type T struct {
int
}
func (t T) testT() {
fmt.Println("如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 T 方法")
}
func (t *T) testP() {
fmt.Println("如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 *T 方法")
}
func main() {
s1 := S{T{1}}
s2 := &s1
fmt.Printf("s1 is : %v\n", s1)
s1.testT()
s1.testP()
fmt.Printf("s2 is : %v\n", s2)
s2.testT()
s2.testP()
}
输出结果:
s1 is : {{1}}
如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 T 方法
如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 *T 方法
s2 is : &{{1}}
如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 T 方法
如类型 S 包含匿名字段 *T,则 S 和 *S 方法集包含 *T 方法
表达式
Golang 表达式 :根据调用者不同,方法分为两种表现形式:
instance.method(args...) ---> <type>.func(instance, args...)
前者称为 method value,后者 method expression。
两者都可像普通函数那样赋值和传参,区别在于 method value 绑定实例,而 method expression 则须显式传参。
package main
import "fmt"
type User struct {
id int
name string
}
func (self *User) Test() {
fmt.Printf("%p, %v\n", self, self)
}
func main() {
u := User{1, "Tom"}
u.Test()
mValue := u.Test
mValue() // 隐式传递 receiver
mExpression := (*User).Test
mExpression(&u) // 显式传递 receiver
}
输出结果:
0xc42000a060, &{1 Tom}
0xc42000a060, &{1 Tom}
0xc42000a060, &{1 Tom}
需要注意,method value 会复制 receiver。
package main
import "fmt"
type User struct {
id int
name string
}
func (self User) Test() {
fmt.Println(self)
}
func main() {
u := User{1, "Tom"}
mValue := u.Test // 立即复制 receiver,因为不是指针类型,不受后续修改影响。
u.id, u.name = 2, "Jack"
u.Test()
mValue()
}
输出结果
{2 Jack}
{1 Tom}
在汇编层面,method value 和闭包的实现方式相同,实际返回 FuncVal 类型对象。
FuncVal { method_address, receiver_copy }
可依据方法集转换 method expression,注意 receiver 类型的差异。
package main
import "fmt"
type User struct {
id int
name string
}
func (self *User) TestPointer() {
fmt.Printf("TestPointer: %p, %v\n", self, self)
}
func (self User) TestValue() {
fmt.Printf("TestValue: %p, %v\n", &self, self)
}
func main() {
u := User{1, "Tom"}
fmt.Printf("User: %p, %v\n", &u, u)
mv := User.TestValue
mv(u)
mp := (*User).TestPointer
mp(&u)
mp2 := (*User).TestValue // *User 方法集包含 TestValue。签名变为 func TestValue(self *User)。实际依然是 receiver value copy。
mp2(&u)
}
输出:
User: 0xc42000a060, {1 Tom}
TestValue: 0xc42000a0a0, {1 Tom}
TestPointer: 0xc42000a060, &{1 Tom}
TestValue: 0xc42000a100, {1 Tom}
将方法 "还原" 成函数,就容易理解下面的代码了。
package main
type Data struct{}
func (Data) TestValue() {}
func (*Data) TestPointer() {}
func main() {
var p *Data = nil
p.TestPointer()
(*Data)(nil).TestPointer() // method value
(*Data).TestPointer(nil) // method expression
// p.TestValue() // invalid memory address or nil pointer dereference
// (Data)(nil).TestValue() // cannot convert nil to type Data
// Data.TestValue(nil) // cannot use nil as type Data in function argument
}
自定义error
package main
import "fmt"
// 系统抛
func test01() {
a := [5]int{0, 1, 2, 3, 4}
a[1] = 123
fmt.Println(a)
//a[10] = 11
index := 10
a[index] = 10
fmt.Println(a)
}
func getCircleArea(radius float32) (area float32) {
if radius < 0 {
// 自己抛
panic("半径不能为负")
}
return 3.14 * radius * radius
}
func test02() {
getCircleArea(-5)
}
//
func test03() {
// 延时执行匿名函数
// 延时到何时?(1)程序正常结束 (2)发生异常时
defer func() {
// recover() 复活 恢复
// 会返回程序为什么挂了
if err := recover(); err != nil {
fmt.Println(err)
}
}()
getCircleArea(-5)
fmt.Println("这里有没有执行")
}
func test04() {
test03()
fmt.Println("test04")
}
func main() {
test04()
}
1.1.2. 返回异常
package main
import (
"errors"
"fmt"
)
func getCircleArea(radius float32) (area float32, err error) {
if radius < 0 {
// 构建个异常对象
err = errors.New("半径不能为负")
return
}
area = 3.14 * radius * radius
return
}
func main() {
area, err := getCircleArea(-5)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(area)
}
}
1.1.3. 自定义error:
package main
import (
"fmt"
"os"
"time"
)
type PathError struct {
path string
op string
createTime string
message string
}
func (p *PathError) Error() string {
return fmt.Sprintf("path=%s \nop=%s \ncreateTime=%s \nmessage=%s", p.path,
p.op, p.createTime, p.message)
}
func Open(filename string) error {
file, err := os.Open(filename)
if err != nil {
return &PathError{
path: filename,
op: "read",
message: err.Error(),
createTime: fmt.Sprintf("%v", time.Now()),
}
}
defer file.Close()
return nil
}
func main() {
err := Open("/Users/5lmh/Desktop/go/src/test.txt")
switch v := err.(type) {
case *PathError:
fmt.Println("get path error,", v)
default:
}
}
输出结果:
get path error, path=/Users/pprof/Desktop/go/src/test.txt
op=read
createTime=2018-04-05 11:25:17.331915 +0800 CST m=+0.000441790
message=open /Users/pprof/Desktop/go/src/test.txt: no such file or directory


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人