python 读取不同格式文本
关键词:BOM;文本编码格式;UTF-8
常见文本编码格式:UTF-8、UTF-16、UTF-32、ANSCII
什么是BOM
BOM 是 Byte Order Mark 的简称,即字节序标记。用于标记文本流:
- 表示文本流的字节顺序,是小端序(little-endian)还是大端序(big-endian);
- 表示文本流是 Unicode 字符;
- 表示文本流的编码方式。
微软在自己的UTF-8格式的文本文件开头加上了EF BB BF三个字节, windows上面的notepad等程序就是根据这三个字节来确定一个文本文件是ASCII的还是UTF-8的,几种编码方式的 BOM 值:
- UTF-8:0xEFBBBF
- UTF-16(BE):0xFEFF
- UTF-16(LE):0xFFFE
- UTF-32(BE):0x0000FEFF
- UTF-32(LE):0xFFFE0000
然而这个只是微软自己作的标记, 其它平台上并没有对UTF-8文本文件做个这样的标记,这对文件读取造成麻烦。要注意编码是否是带有bom。
检查文件是否有BOM
用UltraEdit打开文件,切换到十六进制编辑模式(Ctrl + H),察看文件头部是否有BOM 值。
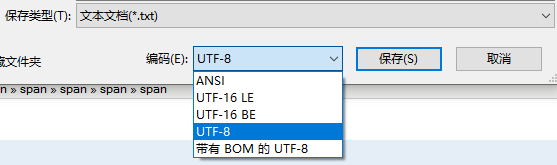
用Windows的记事本打开,选择 “另存为”,看文件的默认编码是UTF-8还是ANSI,如果是ANSI则不带BOM。
去除文件的BOM
1. Utraledit 文件 -> 另存为。
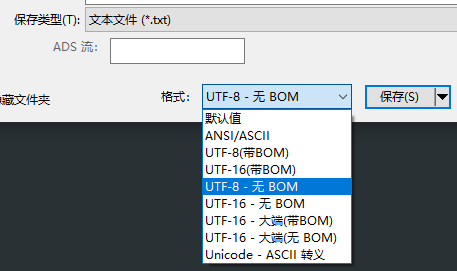
注意:Utraledit右下角只能改变编码格式,不能去除bom
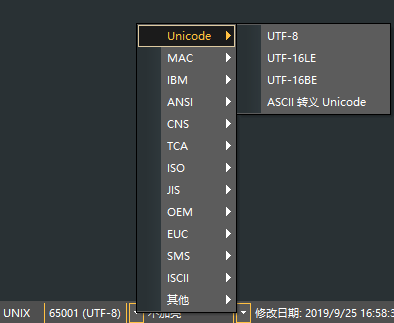
2. 记事本 文件 -> 另存为。
python 读取不同格式文本
Python核心库的open函数是按照ascii设计的。但是,现在我们越来越多地要面对Unicode文件。好在python提供了codecs模块,帮我们解决了这个问题。使用中有一些需要注意的问题。
codecs模块的open定义如下
open(filename, mode[, encoding[, errors[, buffering]])
#Open an encoded file using the given mode and return a wrapped version providing transparent encoding/decoding.
其中前两个参数filename和mode和默认的open相同。第三个参数encoding是关键,制定了文件的编码方式。
对于常用的Unicode有这几种utf_16、utf_16_le、utf_16_be、utf_8,每一种还有一些可用的别名,具体可以查找python manual。
utf_16、utf_16_le、utf_16_be参数的区别是这样的。
如果指定了utf_16,python会检查文件的BOM(Byte Order Mark)来判断,文件类型到底是utf_16_le、utf_16_be。对于没有BOM的文件会报错。
如果我们直接指定了utf_16_le、utf_16_be,python就不检查BOM了。对于没有BOM的文件很好用。但是,对于有BOM的文件就要注意,它会把BOM当作第一个字符读入。
在python下读取带bom的utf-8格式的文件可以用encoding='utf_8_sig'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号