Python对豆瓣电影Top250并进行数据分析并可视化
数据获取
翻页操作
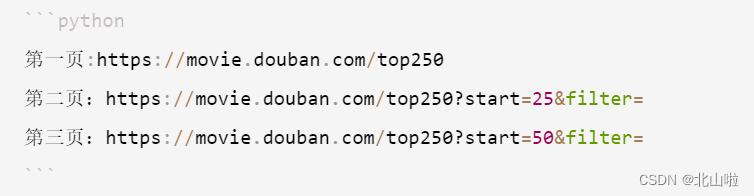
观察可知,我们只需要修改start参数即可
headers字段
headers中有很多字段,这些字段都有可能会被对方服务器拿过来进行判断是否为爬虫
通过headers中的User-Agent字段来
原理:默认情况下没有User-Agent,而是使用模块默认设置
解决方法:请求之前添加User-Agent即可;更好的方式是使用User-Agent池来解决(收集一堆User-Agent的方式,或者是随机生成User-Agent)
在这里我们只需要添加请求头即可
数据定位
这里我使用的是xpath
# -*- coding: utf-8 -*-
# @Author: Kun
import requests
from lxml import etree
import pandas as pd
df = []
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36',
'Referer': 'https://movie.douban.com/top250'}
columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']
def get_data(html):
xp = etree.HTML(html)
lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
"""排名、标题、导演、演员、"""
ranks = li.xpath('div/div[1]/em/text()')
titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')
directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")
infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')
dates,areas,genres = infos[0],infos[1],infos[2]
ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]
quotes = li.xpath('.//p[@class="quote"]/span/text()')
for rank,title,director in zip(ranks,titles,directors):
if len(quotes) == 0:
quotes = None
else:
quotes = quotes[0]
df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])
d = pd.DataFrame(df,columns=columns)
d.to_excel('Top250.xlsx',index=False)
for i in range(0,251,25):
url = "https://movie.douban.com/top250?start={}&filter=".format(str(i))
res = requests.get(url,headers=headers)
html = res.text
get_data(html)生成的数据保存在Top250.xlsx中。
- 使用面向对象+线程
# -*- coding: utf-8 -*-
"""
Created on Tue Feb 2 15:19:29 2021
@author: 北山啦
"""
import pandas as pd
import time
import requests
from lxml import etree
from queue import Queue
from threading import Thread, Lock
class Movie():
def __init__(self):
self.df = []
self.headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4343.0 Safari/537.36',
'Referer': 'https://movie.douban.com/top250'}
self.columns = ['排名','电影名称','导演','上映年份','制作国家','类型','评分','评价分数','短评']
self.lock = Lock()
self.url_list = Queue()
def get_url(self):
url = 'https://movie.douban.com/top250?start={}&filter='
for i in range(0,250,25):
self.url_list.put(url.format(str(i)))
def get_html(self):
while True:
if not self.url_list.empty():
url = self.url_list.get()
resp = requests.get(url,headers=self.headers)
html = resp.text
self.xpath_parse(html)
else:
break
def xpath_parse(self,html):
xp = etree.HTML(html)
lis = xp.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
"""排名、标题、导演、演员、"""
ranks = li.xpath('div/div[1]/em/text()')
titles = li.xpath('div/div[2]/div[1]/a/span[1]/text()')
directors = li.xpath('div/div[2]/div[2]/p[1]/text()')[0].strip().replace("\xa0\xa0\xa0","\t").split("\t")
infos = li.xpath('div/div[2]/div[2]/p[1]/text()')[1].strip().replace('\xa0','').split('/')
dates,areas,genres = infos[0],infos[1],infos[2]
ratings = li.xpath('.//div[@class="star"]/span[2]/text()')[0]
scores = li.xpath('.//div[@class="star"]/span[4]/text()')[0][:-3]
quotes = li.xpath('.//p[@class="quote"]/span/text()')
for rank,title,director in zip(ranks,titles,directors):
if len(quotes) == 0:
quotes = None
else:
quotes = quotes[0]
self.df.append([rank,title,director,dates,areas,genres,ratings,scores,quotes])
d = pd.DataFrame(self.df,columns=self.columns)
d.to_excel('douban.xlsx',index=False)
def main(self):
start_time = time.time()
self.get_url()
th_list = []
for i in range(5):
th = Thread(target=self.get_html)
th.start()
th_list.append(th)
for th in th_list:
th.join()
end_time = time.time()
print(end_time-start_time)
if __name__ == '__main__':
spider = Movie()
spider.main()文章目录
一、上映高分电影数量最多的年份Top10
import collections
import pandas as pd
from matplotlib import pyplot as plt
# 读取数据
df = pd.read_excel("movie.xlsx")
# print(type(df)) # <class 'pandas.core.frame.DataFrame'>
show_time = list(df["上映时间"])
# 有上映时间数据是1961(中国大陆)这样的 处理一下 字符串切片
show_time = [s[:4] for s in show_time]
show_time_count = collections.Counter(show_time)
# 取数量最多的前10 得到一个列表 里面每个元素是元组
# (年份, 数量)
show_time_count = show_time_count.most_common(10)
# 字典推导式
show_time_dic = {k: v for k, v in show_time_count}
# 按年份排序
show_time = sorted(show_time_dic)
# 年份对应高分电影数量
counts = [show_time_dic[k] for k in show_time]
plt.figure(figsize=(9, 6), dpi=100)
# 设置字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 绘制条形图
plt.bar(show_time, counts, width=0.5, color="cyan")
# y轴刻度重新设置一下
plt.yticks(range(0, 16, 2))
# 添加描述信息
plt.xlabel("年份")
plt.ylabel("高分电影数量")
plt.title("上映高分电影数量最多的年份Top10", fontsize=15)
# 添加网格 网格的透明度 线条样式
plt.grid(alpha=0.2, linestyle=":")
plt.show()
二、豆瓣电影Top250评分-排名的散点分布
import pandas as pd
from matplotlib import pyplot as plt
# 读取数据
df = pd.read_excel("movie.xlsx")
# 豆瓣电影Top250 排名 评分 散点图 描述关系
rating = list(df["排名"])
rating_score = list(df["评分"])
plt.figure(figsize=(9, 6), dpi=100)
# 设置字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 绘制散点图 设置点的颜色
plt.scatter(rating_score, rating, c='r')
# 添加描述信息 设置字体大小
plt.xlabel("评分", fontsize=12)
plt.ylabel("排名", fontsize=12)
plt.title("豆瓣电影Top250评分-排名的散点分布", fontsize=15)
# 添加网格 网格的透明度 线条样式
plt.grid(alpha=0.5, linestyle=":")
plt.savefig('test2.PNG')
plt.show()
三、电影类型分析
import collections
import xlrd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# 读取数据
data = xlrd.open_workbook('movie.xlsx')
table = data.sheets()[0]
type_list = []
for i in range(1, table.nrows):
x = table.row_values(i)
genres = x[5].split(" ")
for j in genres:
type_list.append(j)
type_count = collections.Counter(type_list)
# 绘制词云
my_wordcloud = WordCloud(
max_words=100, # 设置最大显示的词数
font_path='simhei.ttf', # 设置字体格式
max_font_size=66, # 设置字体最大值
random_state=30, # 设置随机生成状态,即多少种配色方案
min_font_size=12, # 设置字体最小值
).generate_from_frequencies(type_count)
# 显示生成的词云图片
plt.imshow(my_wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig('test3.PNG')
plt.show()
四、国家或地区上榜电影数量最多的Top10
import pandas as pd
import collections
from matplotlib import pyplot as plt
df = pd.read_excel('movie.xlsx')
area = list(df['上映地区'])
sum_area = []
for x in area:
x = x.split(" ")
for i in x:
sum_area.append(i)
area_count = collections.Counter(sum_area)
area_dic = dict(area_count)
area_count = [(k, v) for k, v in list(area_dic.items())]
# 按国家或地区上榜电影数量排序
area_count.sort(key=lambda k: k[1])
# 取国家或地区上榜电影数量最多的前十
area = [m[0] for m in area_count[-10:]]
nums = [m[1] for m in area_count[-10:]]
plt.figure(figsize=(9, 6), dpi=100)
# 设置字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 绘制横着的条形图
plt.barh(area, nums, color='red')
# 添加描述信息
plt.xlabel('电影数量')
plt.title('国家或地区上榜电影数量最多的Top10')
plt.savefig('test4.PNG')
plt.show()
五、豆瓣电影Top250-评价人数Top10
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_excel('movie.xlsx')
name = list(df['电影名'])
ranting_num = list(df['评价人数'])
# (电影名, 评价人数)
info = [(m, int(n.split('人')[0])) for m, n in list(zip(name, ranting_num))]
# 按评价人数排序
info.sort(key=lambda x: x[1])
# print(info)
name = [x[0] for x in info[-10:]]
ranting_num = [x[1] for x in info[-10:]]
plt.figure(figsize=(12, 6), dpi=100)
# 设置字体
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
# 绘制横着的条形图
plt.barh(name, ranting_num, color='cyan', height=0.4)
# 添加描述信息
plt.xlabel('评价人数')
plt.title('豆瓣电影Top250-评价人数Top10')
plt.savefig('test5.PNG')
plt.show()
六、对肖申克的救赎的部分评论进行文本分词并绘制词云
from stylecloud import gen_stylecloud
import jieba
import re
# 读取数据
with open('reviews.txt', encoding='utf-8') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=False)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
gen_stylecloud(
text=' '.join(result_list),
size=500,
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
output_name='test3.png',
icon_name='fas fa-video',
palette='colorbrewer.qualitative.Dark2_7'
)运行效果如下:

本文来自博客园,作者:木子欢儿,转载请注明原文链接:https://www.cnblogs.com/HGNET/p/16930286.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号