基于DBSCAN的学生月上网时间聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一一种基于密度的聚类算法。
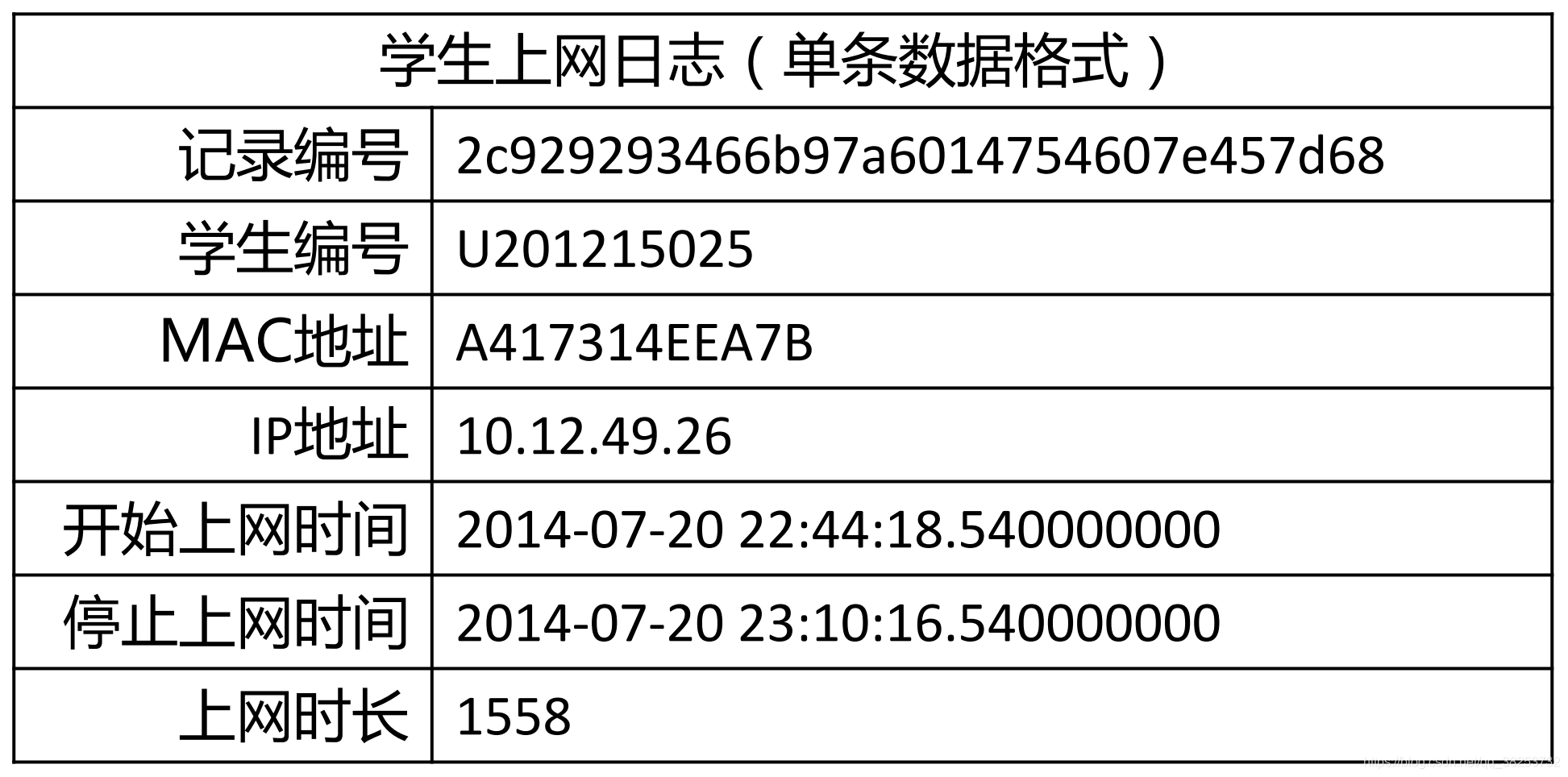
现有学生上网数据格式如下:
数据下载地址:https://pan.baidu.com/s/1eR7doh8
目的:通过DBSCAN聚类,分析学生上网时间和上网时长的模式
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as plt
"""
学生上网日志单条记录格式
记录编号 学生编号 MAC地址 IP地址 开始上网时间 停止上网时间 上网时长
2c929293466b97a6014754607e457d68,U201215025,A417314EEA7B,10.12.49.26,2014-07-20 22:44:18.540000000,2014-07-20 23:10:16.540000000,1558,15,本科生动态IP模版,100元每半年,internet
"""
mac2id = dict()
"""
key是MAC地址
value是开始上网时间和上网时长
"""
onlinetimes = []
f = open("OnlineData.txt", encoding='utf8')
for line in f:
data = line.split(',')
mac = data[2]
onlinetime = int(data[6])
starttime = int(data[4].split(' ')[1].split(':')[0])
if mac not in mac2id:
mac2id[mac] = len(onlinetimes)
onlinetimes.append((starttime, onlinetime))
else:
onlinetimes[mac2id[mac]] = [(starttime, onlinetime)]
real_X = np.array(onlinetimes).reshape((-1, 2)) # 参数-1可以自动确定行数
# 调用DBSCAN方法进行训练,labels是每个数据的簇标签
X = real_X[:, 0:1] # 截取第一列
db = skc.DBSCAN(eps=0.01, min_samples=20, metric='euclidean').fit(X)
# eps:两个样本被看作邻居节点的最大距离
# min_sample:簇的样本数
# metrics:距离计算方式(默认欧几里得距离)
labels = db.labels_
# 计算噪声数据的比例
print("Labels")
print(labels)
ratio = len(labels[labels[:] == -1]) / len(labels[:]) # 判定噪声数据(label被打上-1)数据所占的比例
# print("Noise ratio:{:.2f}".format(ratio))
print('Noise raito:', format(ratio, '.2%'))
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
# 计算簇的比例并打印,评价聚类效果
print("Estimate number of clusters:%d" % n_clusters_)
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels))
# 轮廓系数(Silhouette Coefficient)的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优
# 打印各簇标号以及各簇内数据
for i in range(n_clusters_):
print("Cluster", i, ":")
print(list(X[labels == i].flatten()))
# flatten()方法:将numpy对象(如array、mat)折叠成一维数组返回
plt.hist(X, 24)
"""
hist的参数非常多,但常用的就这六个,只有第一个是必须的,后面四个可选
arr: 需要计算直方图的一维数组
bins: 直方图的柱数,可选项,默认为10
normed: 是否将得到的直方图向量归一化。默认为0
facecolor: 直方图颜色
edgecolor: 直方图边框颜色
alpha: 透明度
histtype: 直方图类型,‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’
"""
plt.show()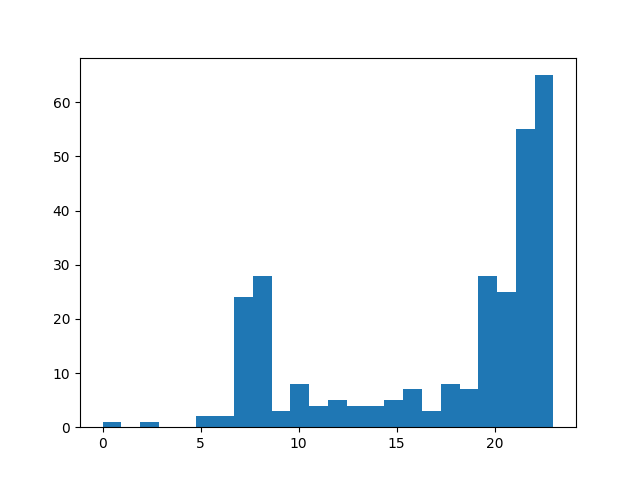
结论:上网时间大多聚集在22:00和23:00
本文来自博客园,作者:木子欢儿,转载请注明原文链接:https://www.cnblogs.com/HGNET/p/16843243.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号