使用mediapipe和OpenCV实现摄像头实时人脸检测
# 摄像头实时人脸检测
# opencv
import time
import cv2
# mediapipe ai工具包
import mediapipe as mp
# 进度条库
from tqdm import tqdm
# 导入模型
mp_face_detection = mp.solutions.face_detection
model = mp_face_detection.FaceDetection(
min_detection_confidence=0.5, # 置信度阈值,过滤掉小于置信度的预测框
model_selection=1, # 选择模型,0 适用于人脸离摄像头比较近(2米内),1 适用于比较远(5米以内)
)
# 导入可视化函数以及可视化样式
mp_drawing = mp.solutions.drawing_utils
# 关键点样式
keypoint_style = mp_drawing.DrawingSpec(thickness=5, circle_radius=3, color=(0, 255, 0))
# 人脸预测框样式
bbox_style = mp_drawing.DrawingSpec(thickness=5, circle_radius=3, color=(255, 0, 0))
# 处理单帧的函数
def process_frame(img):
# 记录该帧开始处理的时间
start_time = time.time()
# BGR转RGB
img_RGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 将RGB输入模型预测结果
results = model.process(img_RGB)
if results.detections: # 只有检测出人脸的时候才可视化
# 可视化人脸框和人脸关键点
for detection in results.detections:
mp_drawing.draw_detection(img,
detection,
keypoint_drawing_spec=keypoint_style,
bbox_drawing_spec=bbox_style)
# 记录该帧完毕处理的时间
end_time = time.time()
# 计算每秒处理图像帧数FPS
FPS = 1 / (end_time - start_time)
scaler = 1
# 在图像上写FPS数值,参数依次为图片、添加的文字、左上角坐标、字体、字体大小、颜色、字体粗细
img = cv2.putText(img, 'FPS ' + str(int(FPS)), (25 * scaler, 50 * scaler), cv2.FONT_HERSHEY_SIMPLEX, 1.25 * scaler,
(0, 0, 255), 1)
return img
# 调用摄像头获取每帧
# 获取摄像头
cap = cv2.VideoCapture(0)
# 打开cap
cap.open(0)
# 无限循环,直到break被触发
while cap.isOpened():
# 获取画面
success, frame = cap.read()
if not success:
print('出错啦!')
break
# 处理帧函数
frame = process_frame(frame)
# 展示处理后的三通道图像
cv2.imshow('my_window', frame)
# 按q或Esc退出
if cv2.waitKey(1) in [ord('q'), 27]:
break
# 关闭摄像头
cap.release
# 关闭窗口图像
cv2.destoryAllWindows()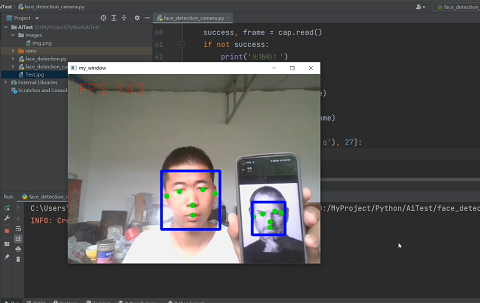
本文来自博客园,作者:木子欢儿,转载请注明原文链接:https://www.cnblogs.com/HGNET/p/16506246.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号