【SqlServer】聚集索引与主键、非聚集索引 解析
目录结构:
聚集索引、非聚集索引在SqlServer、MySQL、Oracle...等数据库中都有这个概念,只不过在SqlServer中叫做聚集索引和非聚集索引而已。下面笔者将会以SqlServer数据库来讲解。
1.聚集索引和非聚集索引的区别
聚集索引:该索引中键值的逻辑顺序决定了表中相应行的物理顺序。
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
索引是通过二叉树的数据结构来描述的,我们可以这么理解聚集索引:索引的叶子节点就是数据节点。而非聚集索引的叶节点仍然是索引节点,只不过有一个指针指向真正数据所在的数据块。
看下图
聚集索引:
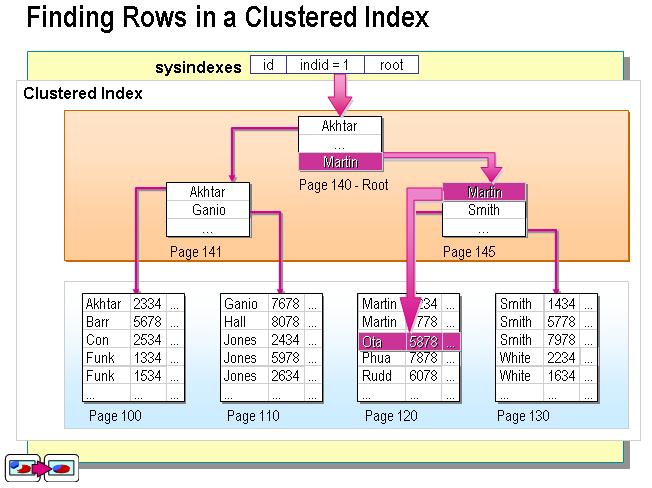
通过这张图片可以看出,数据库的数据是按照某一顺序排列好的,而叶子节点就是真实的数据节点。
非聚集索引:
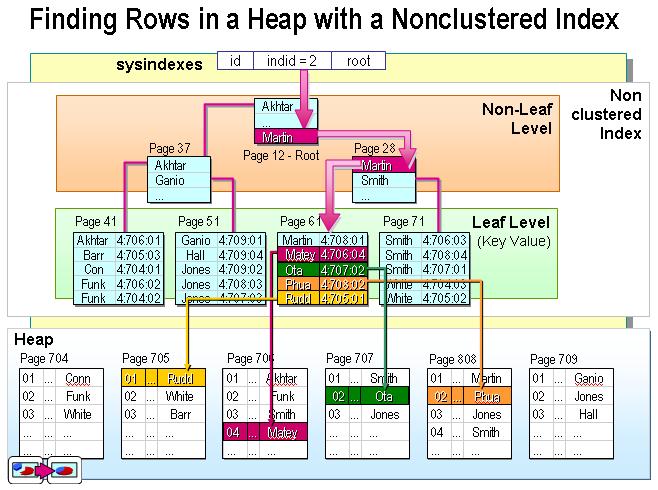
通过这张非聚集索引的图片,我们也可以看出,叶子节点也是数据节点,只不过该节点并非真实的数据节点,该节点存储的是真实数据的内存地址。
下面是一张何时使用聚集索引和非聚集索引的表:
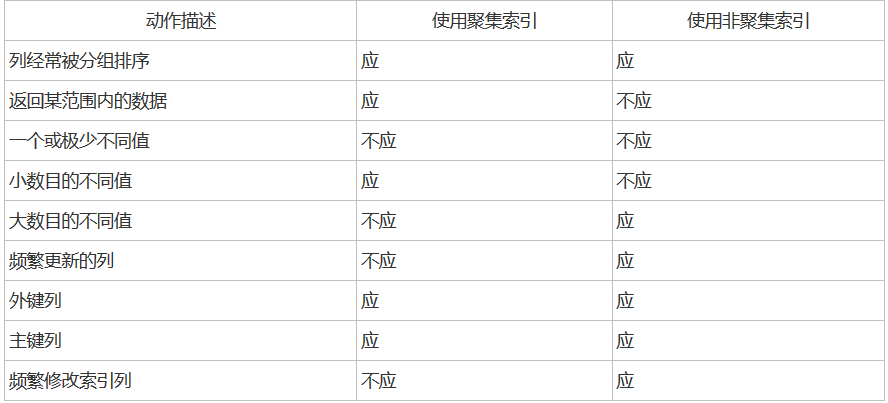
通过上面的图,相信对聚集索引和非聚集索引有了一定的概念了。接来下举个实例,假如有一张500万条数据的消息表,id是主键(13位随机数),time是数据的添加日期,现在需要查询2两年内的所有数据,这很显而易见应该给time添加聚集索引,因为查询的条件为 where time 。所以应该给time添加添加聚集索引,如果是这样的情况,笔者建议最好再给表添加一个idate字段,idate存储当前时间的毫秒数,字段的类型不建议为varchar,最好为int,若int装不下可以设置为numeric,因为int的查询效率要比varchar的效率高。
2.聚集索引和主键的区别
笔者在网上看见有人提出,主键就是加了唯一性约束的聚集索引,这句话不全对。
主键的定义:“主键指的是一个列或多列的组合,其值能唯一地标识表中的每一行,通过它可强制表的实体完整性。”
在SqlServer中,创建主键的列,默认添加一个聚集索引。主键不仅可以关联聚集索引,还可以关联非聚集索引。因此只能说主键和索引有关系。
但是需要明白,主键和索引的作用是不一样的,主键的作用是为了唯一标识表中的某一行,而索引的作用是为了提高查询效率。SqlServer默认给主键列添加聚集索引,这在某些情况下就显得比较浪费,在实际情况中,我们一般都会给ID设置为主键,如果ID是随机产生的,那么这个时候给ID再设置上聚集索引就有点浪费了,原因有二,第一,一般情况不会再按照ID查询区间值数据了,第二,一个表中只能有一个聚集索引,所以聚集索引比较珍贵,要尽可能的发挥聚集索引的最大作用。
3.主键, 聚集索引, 和 非聚集索引 的常规操作
-- 创建聚集索引
create clustered index inx_entry_stock_bi on entry_stock_d(entry_stock_bi)
-- 创建非聚集索引
create nonclustered index inx_entry_stock on entry_stock_d(entry_stock_bi)
-- 索引包含列
create nonclustered index inx_entry_stock on entry_stock_d(entry_stock_bi) include(column1, column2,...)
-- 创建 主键非聚集索引
alter table entry_stock_d add primary key nonclustered--主键且非聚集 ( entry_stock_bi,aid )
-- 创建 主键, 聚集索引 和 自增长
create table entry_stock_d( aid int primary key clustered IDENTITY(1,1), entry_stock_bi varchar(10) );
-- 撤销主键或索引
alter table table_name drop constraint name
4. 建立索引的一般原则
- 每个表中只能创建一个聚集索引。
- 定义text,image,bit数据类型的列上不要建立索引。
- 在经常查询的字段上建立索引。
- 在主键列上一定要建立索引。
- 在那些重复的值比较多,查询较少的列上不要建立索引。
- 要Select的字段,可以考虑在Where字段的索引上,添加包含列。
- 默认情况下,如果未指定聚集,将创建非聚集索引。 对于每个表可创建的最大非聚集索引数为 999。 这包括使用 PRIMARY KEY 或 UNIQUE 约束创建的任何索引,但不包括 XML 索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号