
【C++】C++中的容器解析
目录结构:
1 顺序容器
1.1 顺序容器的种类
| 类型 | 描述 |
| vector | 可变大小数组。支持快速随机访问。在尾部之外的位置插入或删除元素可能很慢。 |
| deque | 双端队列。支持快速随机访问。在头尾位置插入/删除速度很快。 |
| list | 双向链表。只支持双向随机访问。在list中的任何位置插入/删除操作速度都很快。 |
| forward_list | 单向链表。只支持单向顺序访问。在链表任何位置插入/删除操作速度都很快。 |
| array | 固定大小数组。支持快速随机访问。不能添加或删除元素。 |
| string | 与vector类似的容器,单专门用于保存字符。随机访问快。在尾部插入/删除速度快。 |
除了array是固定大小外(不能插入/删除元素),其它容器都提供了高效、灵活的内存管理。
string和vector将元素保存在连续的内存空间中。由于元素是连续存储的,由元素的下标来计算其地址是非常快速的。但是,在这两种容器的中间位置插入或删除元素就会非常耗时:在一次插入或删除操作后,需要移动插入/删除位置之后的所有元素,来保持连续存储。而且,添加一个元素有时可能还需要分配额外的存储空间。在这种情况下,每个元素都必需移动到新的存储空间。
list和forward_list都是链表结构,链表在容器的任何位置添加或删除操作都非常快速。作为代价,链表就不支持快速随机访问元素:在链表中,为了访问一个元素,需要遍历整个容器。与vector、deque和array相比,这两个容器的内存开销也很大。
deque是一个双端队列结构(队列数据结构:FIFO,First In First Out)。与vector/string类似,deque支持快速随机访问元素,在deque的中间位置插入或删除元素的代价(可能)很高。但是,在deque的两端添加或删除元素都是很快的。
1.2 顺序容器的操作
容器可以保存元素类型的限制
顺序容器几乎可以保存任意类型的元素。特别是,我们可以定义一个容器,其元素的类型是另外一种容器。这种容器的定义与其他容器类型完全一样:在尖括号中指定元素类型。
vector<vector<string>> lines;//vector的vector
此处的lines是一个vector,其元素的类型是string的vector。
注意:较旧的编译器可能需要在尖括号之间键入空格,例如,vector<vector<string> >。
虽然我们可以在元素中保存几乎任何类型,但某些容器对元素类型有自己的特殊要求。我们可以为不支持特定操作需求的类型定义元素,这种情况下就只能使用那些没有特殊要求的容器操作了。
例如,顺序容器构造函数的一个版本接受容器大小参数,它使用了元素类型的默认构造函数。但某些类没有默认构造函数。我们可以定义一个保存这种类型对象的容器,但我们在构造这种容器时不能只传递给它一个元素数目参数:
//假定 noDefault 是一个没有默认构造函数的类型 vector<noDefault> v1(10,init); // 正确:提供了元素初始化器 vector<noDefault> v2(10); //错误:必须提供一个元素的初始化器 vector<int> ivec(10,-1); //正确:提供了元素初始化器,10个int元素,每个都初始化为-1 vector<string> svec(10,"Hi"); //正确:提供了元素初始化器,10个string元素,每个都初始化为"Hi" vector<int> ivec(10); //正确:int有默认初始化器,10个int元素,每个都使用默认初始化器初始化为0 vector<string> svec(10) //正确:string有默认初始化器,10个string元素,每个都使用默认初始化器初始化为空string
容器的添加、删除、移动、访问元素
标准库中的容器提供了大量的方法,每种容器之间既有相同的操作方法,也有不同的操作方法,主要是依据容器的特性而定。比如:array容器是固定大小的,所以array容器不能有添加、删除操作方法。forward_list是单向链表结构,所以forward_list不支持push_back和emplace_back操作。
除此之外,每种容器之间既有相同点,也有差异点。这里笔者就不一一列举这些异同点了。下面笔者以vector容器展示容器的增、删、查、改操作:
#include <iostream> #include <vector> int main() { // 创建一个包含数字类型的vector容器 std::vector<int> v = {7, 5, 16, 8}; //添加数字到vector容器中 v.push_back(25); v.push_back(13); //插入元素 std::vector<int>::iterator it = v.begin(); it = v.insert(it, 200); // 迭代和打印vector容器中的内容 for(int n : v) { std::cout << n << '\n'; } //清除vector中的所有元素 v.clear(); }
vector与其它容器提供了其它丰富的容器操作方法,详情可以参见标准库文档。
1.3 容器操作可能使迭代器失效
向容器中添加元素和从容器中删除元素的操作可能会使容器元素的指针、引用或迭代器失效。一个失效的指针、引用或迭代器不再表示任何元素。使用失效的指针、引用或迭代器是一种严重的程序设计错误,很有可能引起与未初始化指针一样的问题。
向容器添加元素后:
如果容器是vector或string,且存储空间被重新分配,则指向容器的迭代器、引用和指针都会失效。如果存储空间未重新分配,则指向插入位置之前的迭代器、指针或引用仍然有效,但指向插入位置之后元素的迭代器、指针户引用将会失效。
对于deque容器,插入到首位置之外的任何位置都会导致迭代器、指针或引用失效。如果在首元素位置插入元素,迭代器会失效,但指向存在的元素的引用和指针不会失效。
对于list和forward_list容器,指向容器的迭代器(包括尾后迭代器和首前迭代器)、指针或引用仍然有效。
当我们从一个容器中删除元素后,指向被删除元素的迭代器、指针和引用都会失效,这应该不会惊讶。毕竟,这些元素已经被销毁了。
向容器删除元素后:
对于list和forward_list,指向容器其它位置的迭代器、指针和引用仍然有效。
对于deque,如果在首尾之外的任何位置删除元素,那么指向被删除元素外其他元素的迭代器、引用或指针也会失效。如果删除的是deque的尾元素,则尾后迭代器会失效,但其它迭代器、引用和指针不受影响;如果删除首元素,其它的元素不会受影响。
对于vector和string,指向被删除元素之前元素的迭代器、指针和引用仍然有效,指向被删除元素之后元素的迭代器、指针和引用失效。
由于向迭代器添加元素和删除元素后可能会使迭代器失效,因此必须保证每次改变容器的操作后都正确的重新定位迭代器,尤其是vector,string和deque容器。
例如:
//删除偶数元素,复制每个奇数元素 vector<int> vi = {0,1,2,3,4,5,6,7,8,9}; vector<int>::iterator iter = vi.begin(); while(iter != vi.end()){ if(*iter % 2){//是奇数 iter = vi.insert(iter,*iter);//复制元素后,重新定位迭代器 iter += 2;//向前移动迭代器,跳过当前元素以及插入到它之前的元素 }else//是偶数 iter = vi.erase(iter);//删除偶数元素,重新定位迭代器 }
1.4 Vector容器的增长机制
为了支持快速随机访问,vector将元素连续存储-每个元素紧挨着前一个元素。
假定容器中的元素是连续存储的,且容器的大小是可变的,考虑向vector或string中添加元素会发生什么:如果没有空间容纳新元素,容器不可能简单地将它添加到内存中的其他位置-因为元素必须是连续存储的。容器必须分配新的内存空间来保存已有元素和新元素,将已有元素从旧位置移动到新空间中,然后添加新元素,释放旧存储空间。如果我们每添加一个元素,vector就执行一次这样的内存分配和释放操作,性能就会慢到不可接受。
为了避免这种代价,标准库实现者采用了可以减少容器空间重新分配次数的策略。当不得不获取新的内存空间时,vector和string的实现通常会分配比新的空间需求更大的内存空间。容器预留这些空间作为备用,可用来保存更多的新元素。这样,就不需要每次添加新元素都重新分配容器的内存空间了。
这种分配策略比每次添加新元素时都重新分配容器内存空间的策略要高效的多。其实际性能表现得也足够好-虽然vector在每次重新分配内存空间时都要移动所有的元素,但使用此策略后,其扩张操作通常比list和deque还快。
vector和string类型提供了一些成员函数,允许我们与它的实现内存部分互动。
| 操作 | 描述 |
| c.shrink_to_fit() | 将capacity()减少为与size()相同大小 |
| c.capacity() | 不重新分配内存空间的话,c可以保存多少个元素 |
| c.reserve(n) | 分配至少能容纳n个元素的内存空间 |
shrink_to_fit只适用于vector,string,deque。capacity和reserve只适用与vector和string。reserve并不改变容器中元素的数量,它仅影响vector预先分配多大的内存空间。
capacity和size的区别,size表示它已经保存的元素的数目,capacity表示在不分配内存空间的前提下它最多可以保存多少个元素。
例如:
vector<int> ivec; //size 应该为0,capacity依赖于具体的实现 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl; //向ivec添加24个元素。 for(vector<int>::size_type ix = 0; ix != 24 ; ix ++) ivec.push_back(ix); //size应该为24;capacity应该大于或等于24,具体值依赖标准库实现 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl; 输出结果为: ivec: size : 0 capacity : 0 ivec: size : 24 capacity : 32
我们可以看出ivec的当前状态应该如下图所示: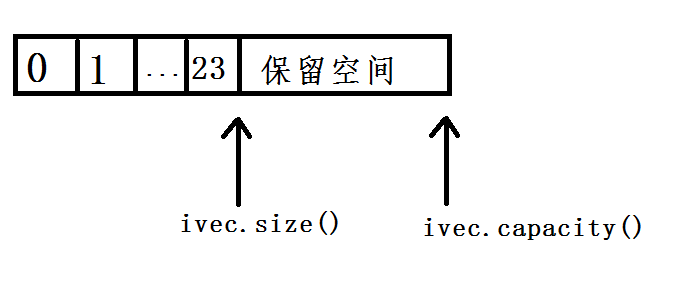
现在可以预分配一些额外空间:
ivec.reserve(50); // 将capacity至少设置为50,可能会更大 //size应为为24;capacity应该大于等于50,具体值依赖标准库的实现 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl
输出结果为
ivec: size : 24 capacity : 50
添加元素用光预留空间:
//添加元素用光多余容量 while(ivec.size() != ivec.capacity()) ivec.push_back(0); //capacity应该未改变,size和capacity相等 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl;
输出结果为:
ivec: size : 50 capacity : 50
由于我们用完了预留空间,因此没必要为vector重新分配新的空间。实际上,只要没有超出vector容量,vector就不会添加新的元素。
如果我们再添加一个元素,vector就不得不重新分配空间:
ivec.push_back(0);//再添加一个元素 //size应该为51,capacity应该大于等于51,具体值依赖标准库实现 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl;
输出结果为:
ivec: size : 51 capacity : 100
这表明vector的实现采用的策略似乎是在每次分配新的内存空间时将当前容量翻倍。
可以调用shrink_to_fit来要求vector将超出当前大小的多余内存退回给系统:
ivec.shrink_to_fit(); //要求归还内存 //size应该未改变,capacity的值依赖具体的标准库实现 cout << " ivec: size : " << ivec.size() << " capacity : " << ivec.capacity() << endl;
调用shrink_to_fit只是一个请求,标准库不保证退换内存。
1.5 容器适配器
除了顺序容器外,标准库还定义了三个顺序容器适配器:stack、queue 和 priority_queue。适配器是标准库的一个通用概念。容器、迭代器和函数都有适配器。本质上,适配器是一种机制,能使某种事物的行为看起来像另外一种事物。一个容器适配器接受一种已有的容器类型,使其行为看起来像一种不同的类型。例如:stack适配器接受一个顺序容器(除array或forward_list外),并使操作看起来像stack一样。
栈适配器
stack类型定义在stack头文件中。下面展示了如何使用stack:
stack<int> intStack; // 空栈 //填满栈 for(size_t ix = 0; ix != 10; ++ix) intStack.push(ix); // intStack 保存0到9十个数 while(!intStack.empty()){// intStack中有值就继续循环 int value = intStack.top(); //使用栈顶值的代码 intStack.pop();//弹出栈顶元素,继续循环 }
其中声明语句
stack<int> intStack;//空栈
定义了一个保存整形元素的栈intStack,初始时为空。for循环将10个元素添加到栈中,这些元素被初始化从0开始连续的整数。while循环遍历整个stack,获取top值,将其从栈中弹出,直至栈空。
队列适配器
queue和priority_queue适配器定义在queue头文件中。
标准库queue是一种先进先出的存储和访问策略。进入队列的对象被安置到队尾,而离开队列的对象则从队首删除。饭店按照客人的到达顺序来为他们安排座位,就一个先进先出的案例。
下面展示了如何使用queue:
#include <queue> #include <deque> #include <iostream> int main() { std::queue<int> q;//空队列 //填满队列 for(size_t ix = 0; ix != 10; ++ix){ q.push(ix); } while(!q.empty()){ int value = q.front(); //队列首位置的值 std::cout << value << " "; q.pop();//弹出首位置的值 } std::cout << std::endl; }
输出结果:
0 1 2 3 4 5 6 7 8 9
priority_queue运行我们为队列中的元素建立优先级。新加入的元素会安排在所有优先级低于它已有元素之前。饭店按照客人的预订时间而不是到达时间的早晚来为他们安排座位,就是一个队列优先的例子。priority_queue总是会优先输出较大元素,当然我们也可以指定自定义的大小比较器。
下面展示了如何使用priority_queue:
#include <functional> #include <queue> #include <vector> #include <iostream> template<typename T> void print_queue(T& q) { while(!q.empty()) { std::cout << q.top() << " "; q.pop(); } std::cout << '\n'; } int main() { std::priority_queue<int> q; for(int n : {1,8,5,6,3,4,0,9,7,2}) q.push(n); print_queue(q); std::priority_queue<int, std::vector<int>, std::greater<int> > q2; for(int n : {1,8,5,6,3,4,0,9,7,2}) q2.push(n); print_queue(q2); // 使用lambda表达式比较元素 auto cmp = [](int left, int right) {return (left ^ 1) < (right ^ 1);}; std::priority_queue<int, std::vector<int>, decltype(cmp)> q3(cmp); for(int n : {0,1,2,3,4,5,6,7,8,9}) q3.push(n); print_queue(q3); }
输出结果:
9 8 7 6 5 4 3 2 1 0
0 1 2 3 4 5 6 7 8 9
8 9 6 7 4 5 2 3 0 1
2.关联容器
在上面我们介绍了顺序容器,这一节介绍关联容器。关联容器和顺序容器有着更本的不同:关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来保存和访问的。
2.1 关联容器的分类
按关键字有序保存元素(有序容器)
| 类型 | 描述 |
| map | 关联数组:保存关键字-值对 |
| set | 关键字即值,即只保存关键字的容器 |
| multimap | 关键字可重复出现的map |
| multiset | 关键字可重复出现的set |
按哈希值无序保存元素(无序容器)
| 类型 | 描述 |
| unordered_map | 用哈希函数组织的map |
| unordered_set | 用哈希函数组织的set |
| unordered_multimap | 哈希组织的map; 关键字可以重复 |
| unordered_multiset | 哈希组织的set; 关键字可以重复 |
类型map和multimap定义在头文件map中,set和multiset定义在头文件set中。按哈希值存储的无序容器则是定义在头文件unordered_map、unordered_set中。
2.2 关联容器操作
2.2.1 关联容器对关键字的要求
关联容器对其关键字类型有一些限制。对于无序容器关键字的要求将会在2.3.1阐述;这里就先说一下有序容器对关键字的要求。有序容器-map,multimap,set以及multiset,关键字类型必须定义元素比较的方法。在默认情况下,标准库使用关键字类型的<运算符来比较两个关键字。
例如:
fruit.h
#include <string> //定义Fruit类 struct Fruit{ std::string name; Fruit(std::string nm):name(nm){} }; //定义比较操作符< bool operator<(const Fruit &f1,const Fruit &f2){ return f1.name < f2.name; }
Test.cpp
#include <string> #include "fruit.h" #include <set> using namespace std; int main(int argc,char* argv[]){ Fruit apple("apple"); Fruit orange("orange"); set<Fruit> fts;//使用set模板 fts.insert(apple); fts.insert(orange); return 0; }
除了像上面那样显示的定义<比较操作符,我们也可以在构造set的时候传入一个比较函数。例如:
car.h
#pragma once #include <string> class Car{ public: std::string name; Car(std::string nm):name(nm){} };
test.cpp
#include "car.h" #include <string> #include <set> using namespace std; //compareCar用于比较两个car bool compareCar(const Car& a,const Car& b){ return a.name < b.name; } int main(int argc,char* argv[]){ Car car1("BMW"); Car car2("Benz"); set<Car,decltype(compareCar)*> cars(compareCar); // 也可以用如下的形式定义: // using f = bool(const Car&,const Car&); // set<Car,f*> cars(compareCar); cars.insert(car1); cars.insert(car2); return 0; }
在我们定义set时,使用了set<Car,decltype(compareCar)*>的模板类型,其中我们使用了自定义的函数比较类型(应该是一种函数指针类型)。此次,我们使用decltype来指出自定义操作的类型。记住,当用decltype来获得一个函数指针类型时,必须加上一个*来指出我们要使用一个给定的函数类型的指针。
2.2.2 pair类型
pair类型在map,multimap,ordered_map,unordered_map容器中应用非常广泛,关于pair在它们中扮演的角色读者可以自行查阅文档。这里笔者介绍一下pair的使用语法。
pair标准库类型保存在容器utility中。一个pair保存两个数据成员,类似容器,pair是一个用来生成特定类型的模板。当创建一个pair时,我们必须提供两个类型名,pair的数据成员将具有对应的类型。
pair<string,string> a;//保存两个string pair<string,size_t> b;//保存一个string和一个size_t
pair的默认构造函数对数据成员进行值初始化,我们也可以为每个成员提供初始化器,pair的数据成员是public的,两个成员名分别是first和second:
pair<string,string> auther{"james","joyes"}; cout << auther.first << "\n"; cout << auther.second << endl;
下面在函数中返回一个pair:
pair<string,int> process(vector<string> &v){ if(!v.empty()) return {v.back(),v.back().size()}; // 列表初始化 else return pair<string,int>(); //隐式构造返回值 }
2.2.3 关联容器迭代器
当解引用一个关联容器迭代器时,我们会得到一个类型为容器的value_type的值的引用。对于map而言,value_type是一个pair类型,其first成员保存const的关键字,second成员保存值。
//words是map<string,size_t>类型 auto map_it = words.begin(); //map_it是map<string,size_t>::iterator类型 //*map_it是一个指向pair<const string,size_t>对象的引用 cout << map_it->first; cout << map_it->second; //map_it->first = "newKey";//错误,关键字是const,不能更改 ++map_it->second;//正确
set的迭代器是const的,虽然set类型同时定义了iterator和const_iterator类型,但两种类型都只允许读取set中的元素。与不能改变map元素关键字一样,一个set中的关键字也是const的。可以用一个set迭代器来读取元素的值。
2.2.4 元素的访问、修改、添加和删除
标准库中提供了大量的操作方法,读者可以自行查阅文档,下面笔者简单列举两三个方法。
| 方法 | 描述 |
| insert | 向容器添加一个元素或一个元素范围 |
| erase | 删除一个元素或是元素范围 |
| find | 访问指定关键字处的元素 |
#include <set>/*set,multiset*/ #include <map>/*map,multimap*/ #include <string>/*string*/ #include <iostream>/*cout,cin*/ using namespace std; int main(int argc,char* argv[]){ cout << "set examples : " << endl; set<int> set_a; set_a.insert(10); set<int>::const_iterator set_a_iter = set_a.find(10);//set不支持at和[]操作 cout << *set_a_iter << endl; set_a.erase(10);//删除元素 cout << "multiset examples : " << endl; multiset<int> set_b;//可以存放相同的值 set_b.insert(15); set_b.insert(15); set_b.insert(16); pair<multiset<int>::const_iterator,multiset<int>::const_iterator> set_b_pair = set_b.equal_range(15); while(set_b_pair.first != set_b_pair.second){ cout << *set_b_pair.first << endl; ++set_b_pair.first; } cout << "map example : " << endl; map<string,size_t> map_a; map_a.insert(make_pair<string,size_t>("a",1)); size_t map_a_val = map_a["a"]; map<string,size_t>::iterator map_a_iter = map_a.begin(); cout << map_a_iter->first << ":" << map_a_iter->second << endl; pair<string,size_t> map_a_pair = *map_a_iter; cout << "multimap example : " << endl; multimap<string,size_t> map_b;//可以存放重复关键字的元素 map_b.insert(pair<string,size_t>("b",2)); map_b.insert(pair<string,size_t>("b",3)); map_b.insert(make_pair<string,size_t>("c",4)); pair<multimap<string,size_t>::iterator,multimap<string,size_t>::iterator> map_b_pair = map_b.equal_range("b"); while(map_b_pair.first != map_b_pair.second){ cout << map_b_pair.first->first << ":" << map_b_pair.first->second << endl; ++map_b_pair.first; } return 0; }
2.3 无序容器
C++11中定义了4个无序关联容器(unordered associative container)。这些容器不是使用比较运算符来组织元素,而是使用一个哈希函数(hash function)和关键字类型的==运算符。在关键字类型的元素没有明显的序的情况下,无序容器非常有用的。
2.3.1 无序容器对关键字类型的要求
无序容器使用关键字类型的==运算符来比较元素,它们还使用一个hash<key_type>类型的对象来生成每个元素的哈希值。标准库为内置类型(包括指针)提供了hash模板,还为一些标准库类型,包括string和智能指针类型提供了hash,我们可以直接使用这些类型。
但是,如果是我们自定义类型的无序容器,则我们必需定义自己的hash模板或是提供默认的比较方法,否则不能作为无序容器的key。
例如:
#include <string> #include <unordered_set> using namespace std; struct Foo{ int val; }; size_t hasher(const Foo& foo){ return hash<int>()(foo.val); } bool eqOp(const Foo& fooa,const Foo& foob){ return fooa.val == foob.val; } int main(int argc,char* argv[]){ using Foo_multiset = unordered_multiset<Foo,decltype(hasher)*,decltype(eqOp)*>; Foo_multiset fm(10,hasher,eqOp);//10是容器的初始化桶的大小 return 0; }
如果为Foo提供了==操作符,那么就只需要提供hasher函数就可以了。
unordered_set<Foo,decltype(hasher)*> fooSet(10,hasher);
2.3.2 无序容器桶的管理
无序容器在存储上组织为一组桶(buckets),每个桶保存零个或多个元素。无序容器使用一个哈希函数将元素映射到桶。为了访问一个元素,容器首先计算元素的哈希值,指出应该搜索那个桶。容器将具有一个特定哈希值的所有元素都保持在相同的桶中。如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。因此无序容器的性能依赖哈希函数的质量和桶的数量和大小。
无序容器提供了一组管理桶的函数,这些成员函数运行我们查询容器的状态以及在必要时强制进行重组。
| 桶接口 | |
| c.bucket_count() | 当前创建桶的数量(并不是每个桶都有元素) |
| c.max_bucket_count() | 容器能容纳桶的最大数量 |
| c.bucket_size(n) | 第n个桶有多少个元素 |
| c.bucket(k) | 关键字k在那个桶中 |
| 桶迭代 | |
| local_iterator | 访问桶中元素的迭代器类型 |
| const_local_iterator | 桶迭代器的const版本 |
| c.begin(n),c.end(n) | 桶n的首元素迭代器和尾后迭代器 |
| c.cbegin(n),c.cend(n) | 桶n的首元素const迭代器和尾后const迭代器 |
| 哈希策略 | |
| c.load_factor() | 每个桶的平均数量 |
| c.max_load_factor() | c试图维护的桶的平均大小 |
| c.rehash(n) | 重组存储 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号