算法题——我在哪
题目

分析题意,寻找最小的K值,使得任意连续K个邮箱序列都是唯一的,也即寻找最小的K值,使得字符串中所有长度为K的子串都是唯一的。
由于n最大为100,可以直接暴力求解。先遍历K值,再遍历两个子串,然后判断这两个子串是否相同,使用四个for循环。
#include<iostream>
#include<stdio.h>
#include<cstring>
#include<algorithm>
using namespace std;
int main()
{
int n;
string s;
cin>>n>>s;
for(int k=1; k<=n; k++)
{
bool isAnswer=true;
for(int i=0; i+k-1<n; i++)
{
for(int j=i+1; j+k-1<n; j++)
{
//
bool isSame=true;
for(int p=0; p<k; p++)
{
//检查到不相等说明两个串不一样,此时isSame是false,会去判断下一个串
if(s[i+p]!=s[j+p])
{
isSame=false;
break;
}
}
//当两个串相同时isSame是最初设置的true,此时就会跳出循环
//两个串不相等只要有一个字符不相等即可,两个串相等需要所有字符对应相同
//所以开始默认相等,检测到不相等就可以判断了
//如果开始默认不相等,检测到相等就跳出,这种可能只有一个字符相等,属于错误做法
if(isSame==true)
{
isAnswer=false;
break;
}
}
if(!isAnswer)
{
break;
}
}
if(isAnswer)
{
cout<<k<<endl;
break;
}
}
return 0;
}
注意两个子串不相同只要有一个字符不相同就可以,而两个子串相同则需要所有字符对应相同,因此首先默认isSame为true,判断当前两个子串是否不同,如果不同,继续判断该K值下的另外的子串。
如果长度为K的子串都是唯一的,那么循环结束isAnswer还是true,因为K是从小到大遍历的,此时一定是最小的满足题意的K,直接输出。如果长度为K的子串不是唯一的,遇到重复的两个子串,isSame就为true,然后直接跳出循环,判断长度K+1的子串。
j从i+1开始避免两个子串截取自同一位置,也可以减少判断次数。
暴力解法时间复杂度为O(n4),可以用二分法和哈希表进行改进。
分析:串长为n,K值为1到n的任意一个数,使用二分法必须要有分界点,分界点一边满足要求、另一边不满足要求。本题中小于K的不满足唯一性条件,大于K的满足唯一性条件,但是不是最小的K值。
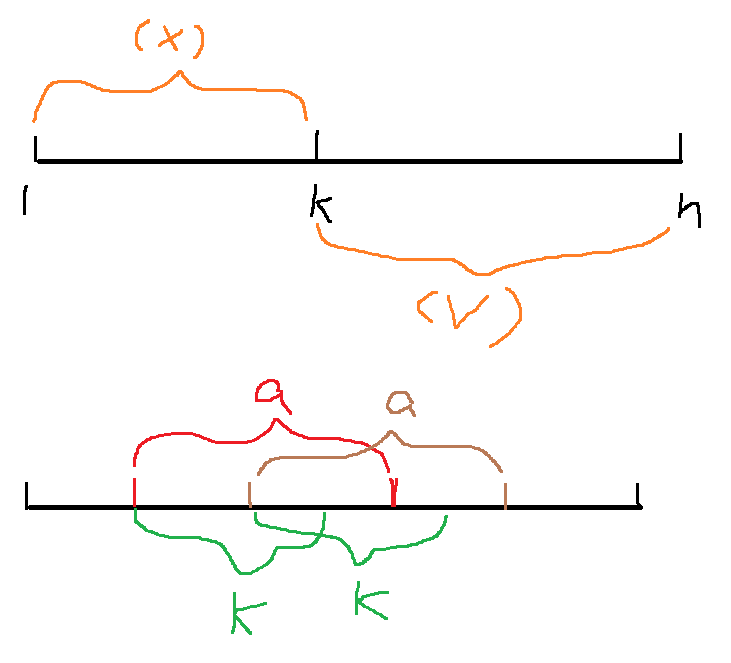
证明:当K为最小的满足长度为K的子串是唯一的时,假设某个大于K的值a不满足题意,那么一定有长度为a的两个子串是相同的(因为它不唯一),但是a>K,长度为a的子串一定包含长度为K的子串,由于两个长度为a的子串相同,那么它们长度为K的前缀也一定相同,这与长度为K的子串都是不重复的前提相矛盾。所以长度大于K的子串都是唯一的。
同理可以证明长度小于K的子串都是不唯一的。
#include<iostream>
#include<stdio.h>
#include<algorithm>
#include<cstring>
#include<unordered_set>
using namespace std;
int n;
string s;
bool check(int mid);
int main()
{
cin>>n>>s;
int l=1, r=n;
while(l<r)
{
int mid=(l+r)>>1;
if(check(mid)) r=mid;
else l=mid+1;
}
cout<<l<<endl;
return 0;
}
bool check(int mid)
{
unordered_set<string> hash;
for(int i=0; i+mid-1<n ;++i)
{
string tmp=s.substr(i, mid);
if(hash.count(tmp)) return false;
hash.insert(tmp);
}
}
substr截取从i开始长度为mid的子串。
hash.count返回表中串tmp的个数。
hash.insert把tmp插入到表中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号