1935.Codeforces Round 932 (Div. 2) - sol
20240306
逊哎~
打一半去写申请书然后 12 点睡觉,相对成功!
第二天早上起来把赛时发愣的 C 和 F 切了。
A. Entertainment in MAC
Congratulations, you have been accepted to the Master's Assistance Center! However, you were extremely bored in class and got tired of doing nothing, so you came up with a game for yourself.
You are given a string
and an even integer . There are two types of operations that you can apply to it:
- Add the reversed string
to the end of the string (for example, if cpm, then after applying the operation cpmmpc). - Reverse the current string
(for example, if cpm, then after applying the operation mpc). It is required to determine the lexicographically smallest
string that can be obtained after applying exactly operations. Note that you can apply operations of different types in any order, but you must apply exactly operations in total.
A string is lexicographically smaller than a string if and only if one of the following holds:
is a prefix of , but ; - in the first position where
and differ, the string has a letter that appears earlier in the alphabet than the corresponding letter in .
。
比较一下
B. Informatics in MAC
In the Master's Assistance Center, Nyam-Nyam was given a homework assignment in informatics.
There is an array
of length , and you want to divide it into subsegments in such a way that the on each subsegment is equal to the same integer. Help Nyam-Nyam find any suitable division, or determine that it does not exist.
A division of an array into subsegments is defined as pairs of integers such that and for each , , and also and . These pairs represent the subsegments themselves.
of an array is the smallest non-negative integer that does not belong to the array. For example:
of the array is , because does not belong to the array. of the array is , because and belong to the array, but does not. of the array is , because , , , and belong to the array, but does not.
。
考虑每一段的 MEX 一定是全局的 MEX,这是比较好想到的。
于是就做完了,从左往右扫一遍,如果当前段的 MEX 已经是全局的了,就直接断开成一段即可。
最后没匹配完的合并到前面一段,判断一下段数是否为
C. Messenger in MAC
In the new messenger for the students of the Master's Assistance Center, Keftemerum, an update is planned, in which developers want to optimize the set of messages shown to the user. There are a total of
messages. Each message is characterized by two integers and . The time spent reading the set of messages with numbers ( , all are distinct) is calculated by the formula: Note that the time to read a set of messages consisting of one message with number
is equal to . Also, the time to read an empty set of messages is considered to be . The user can determine the time
that he is willing to spend in the messenger. The messenger must inform the user of the maximum possible size of the set of messages, the reading time of which does not exceed . Note that the maximum size of the set of messages can be equal to . The developers of the popular messenger failed to implement this function, so they asked you to solve this problem.
。
赛时忘记比较大小直接寄。
首先,假设我们选出来了一些数,怎么让它们的代价最小呢?
容易发现,排列对于
现在来考虑怎么选集合呢?
首先按照
而这里面的答案其实就是
发现假设我们枚举到当前的
看似需要用 priority_queue 不断加入删除找到最优,这样的时间复杂度是不优的。
但是细想一下发现,我们要求是取最大值,如果当前换成的这个
我们其实不用管它了,因为这样的答案一定不会取到最大值,上一个才有可能最大。
所以这样做了之后,我们就可以保证复杂度了,
只需要在每次换
实现比较简单,时间复杂度
D. Exam in MAC
The Master's Assistance Center has announced an entrance exam, which consists of the following.
The candidate is given a set
of size and some strange integer . For this set, it is needed to calculate the number of pairs of integers such that , is not contained in the set , and also is not contained in the set . Your friend wants to enter the Center. Help him pass the exam!
。
感觉做 A 的时间都比做 D 的时间长。
莫名奇妙地想到了容斥——挺典的吧。
首先,一共有
- 当
- 当
- 当
减去这两部分,根据简单的容斥原理,我们发现需要加上
而由于
于是对于每一个
非常简单地就做完了。代码。
E. Distance Learning Courses in MAC
The New Year has arrived in the Master's Assistance Center, which means it's time to introduce a new feature!
Now students are given distance learning courses, with a total of
courses available. For the -th distance learning course, a student can receive a grade ranging from to . However, not all courses may be available to each student. Specifically, the
-th student is only given courses with numbers from to , meaning the distance learning courses with numbers . The creators of the distance learning courses have decided to determine the final grade in a special way. Let the
-th student receive grades for their distance learning courses. Then their final grade will be equal to , where denotes the bitwise OR operation. Since the chatbot for solving distance learning courses is broken, the students have asked for your help. For each of the
students, tell them the maximum final grade they can achieve.
。
有一个点没想到。
分析样例,首先对于
我们假设上界为
反之,只要这里的
再回到整体,贪心思路,一定是从高到低能为
如果一个位置上有了两个
那么这一位后面就全是
发现这一定是最优的,如果没有,我们就直接用
而哪些可变的
稍加思考发现这些东西都可以用线段树维护,输出的时候在吧可变的
这样就做完了,具体可以看代码。代码。
F. Andrey's Tree
Master Andrey loves trees
very much, so he has a tree consisting of vertices. But it's not that simple. Master Timofey decided to steal one vertex from the tree. If Timofey stole vertex
from the tree, then vertex and all edges with one end at vertex are removed from the tree, while the numbers of other vertices remain unchanged. To prevent Andrey from getting upset, Timofey decided to make the resulting graph a tree again. To do this, he can add edges between any vertices and , but when adding such an edge, he must pay coins to the Master's Assistance Center. Note that the resulting tree does not contain vertex
. Timofey has not yet decided which vertex
he will remove from the tree, so he wants to know for each vertex , the minimum number of coins needed to be spent to make the graph a tree again after removing vertex , as well as which edges need to be added.
A tree is an undirected connected graph without cycles.
。
上午自己做出来了,写了一篇认真的题解,真挺简单的。
首先,贪心地想,对于每一次连边,从
而并不是任何时刻我们都可以得到
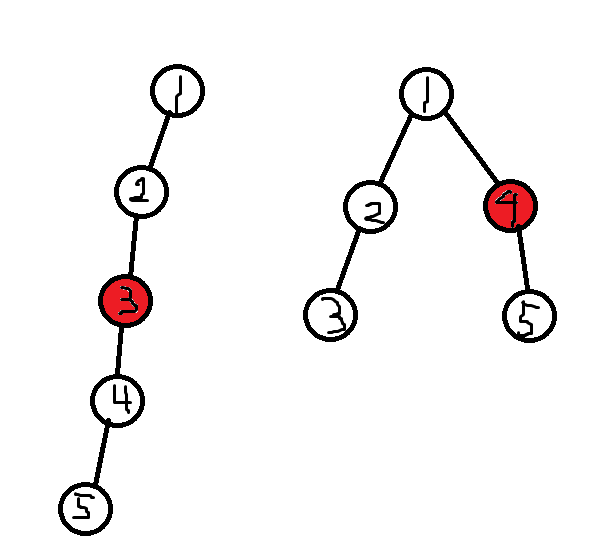
红色点的答案,
,并不能做到 。
这是为什么呢?
容易发现,假设一个点
而在连接这
题目中需要我们构造,那么我们现在的问题就是如何找到并用上
以下的分析默认在以
对于每一条
- 从
- 从
对于第一种情况,容易发现这两个点
对于第二种情况,这两个点
想到这里,大概就可以写了。
LCA 是可以预处理出来的,你怎么求都可以,笔者写得是用 dfn 序
是否在连动块内的判断可以用并查集完成,实际实现的时候你可以假设
每次的构造方案主要就是上面的两种情况,如果存在这样的一条边,并且它所在的两个连动块不连通,那么就直接加入答案就可以了。
最后如果少一条边,就直接加入
感觉没有什么实现难度,由于
似乎不用任何数据结构,只要会求 LCA 和并查集就可以了。代码。
int T,n,dep[N],f[N];
vector<int> G[N],H[N];//H 数组记录 LCA 为 u 的 (i,i+1),也就是第一类边
struct Answer{
int w,m;
vector<pii> g;
void init(){w=m=0,g.clear();}
}ans[N];
struct node{
int u,v,d;//d 记录 LCA 的 dep
node(int U=0,int V=0,int D=0){u=U,v=V,d=D;}
bool operator <(const node &rhs)const {return d<rhs.d;}
}c[N];//c 数组维护每一个点和子树外的节点连接的最优点对,LCA 在越上面越优秀
void init(){for(int i=1;i<=n;i++) G[i].clear(),H[i].clear(),ans[i].init(),c[i]=node(0,0,n+1),f[i]=i;}
void add(int u,int v){G[u].pb(v),G[v].pb(u);}
namespace Tr{//dfn 序求 LCA
int idx=0,dfn[N],lg[N],st[21][N];
void dfs(int u,int fa){
dfn[u]=++idx,st[0][idx]=fa,dep[u]=dep[fa]+1;
for(auto v:G[u]) if(v!=fa) dfs(v,u);
}
int Min(int u,int v){return dfn[u]<dfn[v]?u:v;}
void init(){
idx=0,dfs(1,0);lg[1]=0;
for(int i=2;i<=n;i++) lg[i]=lg[i/2]+1;
for(int i=1;i<=lg[n]+1;i++)
for(int j=1;j+(1<<i)-1<=n;j++)
st[i][j]=Min(st[i-1][j],st[i-1][j+(1<<(i-1))]);
}
int LCA(int u,int v){
if(u==v) return u;
u=dfn[u],v=dfn[v];
if(u>v) swap(u,v);
int s=lg[v-u];
return Min(st[s][u+1],st[s][v-(1<<s)+1]);
}
}
int find(int x){return x==f[x]?x:f[x]=find(f[x]);}
void merge(int u,int v){//并查集
u=find(u),v=find(v);
if(u!=v) f[u]=v;
}
void dfs(int u,int fa){
ans[u].m=ans[u].w=G[u].size()-1;
for(auto v:G[u]) if(v!=fa){
dfs(v,u),c[u]=min(c[u],c[v]);
if(c[v].d<dep[u]) merge(v,u),ans[u].g.pb({c[v].u,c[v].v});//可能存在的第二类边
}
for(auto i:H[u]) if(i!=u&&i+1!=u&&find(i)!=find(i+1)) merge(i,i+1),ans[u].g.pb({i,i+1});//连第一类边
if((int)ans[u].g.size()<ans[u].m){//(u-1,u+1) 的边
++ans[u].w;ans[u].g.pb({u-1,u+1});
for(auto v:G[u]) if(v!=fa) merge(v,u);
}
}
void sol(){
cin>>n;init();
for(int i=1,u,v;i<n;i++) cin>>u>>v,add(u,v);
Tr::init();
for(int i=1;i<=n;i++){//预处理出 (i,i+1) 点对
if(i>1) c[i]=min(c[i],node(i,i-1,dep[Tr::LCA(i,i-1)]));
if(i<n) c[i]=min(c[i],node(i,i+1,dep[Tr::LCA(i,i+1)])),H[Tr::LCA(i,i+1)].pb(i);
}
dfs(1,0);
for(int i=1;i<=n;i++){
cout<<ans[i].w<<' '<<ans[i].m<<'\n';
for(auto j:ans[i].g) cout<<j.fi<<' '<<j.se<<'\n';
cout<<'\n';
}
}
int main(){
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
cin>>T;
while(T--) sol();
return 0;
}
目前 CF 最短解,比较神秘。
Conclusion
-
二进制上下界问题可以讨论这一位是否确定了为
-
加变量的时候注意自定义的函数里面要赋值,不要变成这个样子:(E)
sgt(int A=0,int B=0,int C=0,int D=0){mx=A,d=B,s=C;}//没有 w=D 啊啊啊! -
贪心地选数的题目一定注意——新加入一个数的时候是不是更优,从而替换掉前面的数!(C)
本文作者:H_W_Y
本文链接:https://www.cnblogs.com/H-W-Y/p/18057273/cf1935
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步