
JUC并发编程
1、什么是juc
利用java.util.concurrent包下的工具进行并发编程(在执行时创建多个线程来执行不同的任务,看起来像是这些事情是同时做的一样)

2、Lock锁
一些补充
- 公平锁(不可插队,顺序执行线程)和非公平锁(默认,可以插队)
- 防止虚假唤醒,获取锁的条件用while不用if
传统synchronized
作为关键字用来保证线程安全,利用wait()和notifyAll()进行加锁解锁,相当于系统的默认锁,不可定制
Lock
利用await()和signalAll()进行加锁解锁
Lock l = new ReentrantLock();
l.lock(); //tryLock()尝试获取锁
try {
// access the resource protected by this lock
} finally {
l.unlock();
}
除了ReentrantLock还有

同时Lock中还有newCondition()方法,产生一个Condition对象(可以看成是用来记录被锁的对象的信息);当多个线程同时执行时,只有不满足while条件的那个会继续执行(获取到锁),其他线程锁的请求会被阻塞也就是while里面的conditions.await(),在业务执行完成后,可以通过conditionx.signal()指定名叫conditionx的被锁对象解除阻塞获取锁继续执行
即通过condition来记录了进程中被锁对象的信息,可以达到控制线程执行顺序的目的
生产者消费者问题
class BoundedBuffer<E> {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(E x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal(); //
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
E x = (E) items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
三个对象的情况
package com.Gw.pc;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class A {
public static void main(String[] args) {
B b = new B();
new Thread(()->{
for (int i = 0; i < 20; i++) {
b.printA();
}
},"A").start();
new Thread(()->{
for (int i = 0; i < 20; i++) {
b.printB();
}
},"B").start();
new Thread(()->{
for (int i = 0; i < 20; i++) {
b.printC();
}
},"C").start();
}
}
class B{
private int number = 1;
private Lock lock = new ReentrantLock();
Condition a = lock.newCondition();
Condition b = lock.newCondition();
Condition c = lock.newCondition();
//加锁 执行业务 释放锁
public void printA(){
lock.lock();
try {
while(number != 1){
a.await();
}
number = 2;
System.out.println("AAAAA" + "=>" + Thread.currentThread().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
b.signal();
}
}
public void printB(){
lock.lock();
try {
while(number != 2){
b.await();
}
number = 3;
System.out.println("BBBBBB" + "=>" + Thread.currentThread().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
c.signal();
}
}
public void printC(){
lock.lock();
try {
while(number != 3){
c.await();
}
number = 1;
System.out.println("CCCCCC" + "=>" + Thread.currentThread().getName());
} catch (Exception e) {
e.printStackTrace();
} finally {
a.signal();
}
}
}
synchronized和Lock的对比
- synchronized是java内置的一个关键字,Lock是一个java类
- synchronized无法获取锁的状态,Lock可以判断是否获取到了锁
- synchronized会自动释放锁,lock必须要手动释放锁,如果不释放会发生死锁
- synchronized获得锁后如被阻塞,则其他线程会死等;lock中有tryLock获取不到锁时线程结束
- synchronized可重入锁,不可中断的非公平锁;lock可重入锁,可以判断锁,非公平(可自定义)
- synchronized适合锁小量的代码块,lock锁可以锁大量的代码块
3、8锁问题
- 当方法前用synchronized加锁时,本质上是对对象实例的加锁,锁住的是当前对象。当只有一个对象时,多个线程执行synchronized方法,必须要获得当前对象的锁,即先拿到锁的先执行;当有多个对象时,不同对象的锁互不干扰
- 普通方法(未加锁的方法)与加锁的方法执行时互不干扰,普通方法不需要等待synchronized方法释放锁
- 用static synchronized方法加锁时,锁的是类模板Class(全局唯一),方法执行时对Class加锁,多个线程执行static synchronized方法时,即使有多个对象,他们的Class也被锁住,需等待锁释放
- static synchronized和synchronized执行时前者锁的是Class后者锁的是实例对象,被锁的对象不同,互不干扰
4、集合类不安全
list不安全
解决方法
- 用vector替代list
List<String> list = new Vector<>();
- 使用Collection.sychronizedList
List<String> list = Collection.sychronizedList(new ArrayList<>());
- 使用CopyOnWriteArrayList
List<String> list = new CopyOnWriteArrayList<>();
CopyOnWriteArrayList
写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种通用优化策略,通俗易懂的讲,写入时复制技术就是不同进程在访问同一资源的时候,只有更新操作,才会去复制一份新的数据并更新替换,否则都是访问同一个资源。
多个线程同时执行时,都可以读CopyOnWriteArrayList中的数据;当某个线程对CopyOnWriteArrayList的数据进行修改时,先将ArrayList复制一遍,在将新值插入。数据修改完后,副本将直接替代原来的ArrayList。
缺点
- 由于CopyOnWrite操作中读操作是没有锁的,因此在数据一致性方面略差(只保证了最终数据一致,拷贝后数据替换前获取的数据不一致)
- 并且当对象很大时,频繁的替换会消耗内存,从而引起GC问题,考虑换容器
源码
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
es = Arrays.copyOf(es, len + 1); //先复制
es[len] = e; //再写入
setArray(es);
return true;
}
}
不能保证读的与写的实时一致
public E get(int index) {
return elementAt(getArray(), index);
}
小结
CopyOnWriteArrayList 并发安全且性能比 Vector 好。Vector 是增删改查方法都加了synchronized 来保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而 CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于 Vector。
set不安全
解决方法
- 使用synchronizedSet
Set<String> set= Collection.sychronizedSet(new HashSet<>());
- 使用CopyOnWriteSet
Set<String> set= new CopyOnWriteSet();
HashSet底层是什么?就是HashMap,利用HashMap的Key唯一
map不安全
解决方法
- 使用synchronizedMap
Map<String,String> map= Collection.sychronizedMap(new HashMap<>());
- 使用ConcurrentHashMap
Map<String, String> map = new ConcurrentHashMap;
5、callable
@FunctionalInterface
public interface Callable<V>
callable和runnable的不同:callable有参数、有返回值、实现call方法(runnable实现run方法)
使用:callable的使用实际上是通过FutureTask适配器将其变成Runnable类型,再将FutureTask交由Thread执行
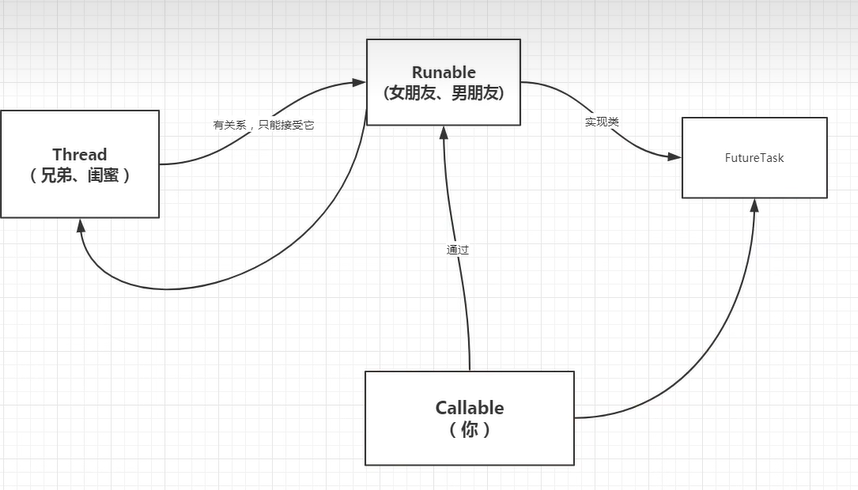
使用示例
package com.Gw.pc;
import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;
public class demo02 {
public static void main(String[] args) {
//将Callable放入Thread中
FutureTask<Integer> futureTask = new FutureTask<>(new MyCallable());
new Thread(futureTask).start();
futureTask.get(); //获取返回值
}
}
class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return 1024;
}
}
6、CountDownLatch、CyclicBarrier、Semaphore
CountDownLatch、CyclicBarrier这两个都可看成是计数类,CountDownLatch是向下减、CyclicBarrier是向上增。用来控制当前业务步骤中,必须要等待指定数量线程都执行完后主线程才能继续向下执行。
CountDownLatch的用法
package com.Gw;
import java.util.concurrent.CountDownLatch;
public class demo02 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(6); //设置总数
for (int i = 1; i <= 6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName());
countDownLatch.countDown(); //计数减一,注意放在线程的末尾
},String.valueOf(i)).start();
}
countDownLatch.await(); //当六个线程不执行完毕主线程无法继续往下走
System.out.println("执行完毕");
}
}
CyclicBarrier的用法
package com.Gw;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class demo03 {
public static void main(String[] args) {
/**
* 设置计数总数,和线程数达到目标数后应执行的线程
* 达不到目标值就不继续执行
*/
CyclicBarrier cb = new CyclicBarrier(7, () -> {
System.out.println("执行完毕");
});
for (int i = 0; i < 7; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName());
try {
cb.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},String.valueOf(i)).start();
}
}
}
Semaphore
两个方法:acquire()、release()
使用示例
package com.Gw;
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
public class demo04 {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3); //设置信号量的数量,即最多并发执行的线程数
for (int i = 0; i < 6; i++) {
new Thread(()->{
try {
semaphore.acquire(); //获取信号量
System.out.println(Thread.currentThread().getName()+"进行停车");
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName()+"结束停车");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
semaphore.release(); //释放信号量
}
}, String.valueOf(i)).start();
}
}
}
7、读写锁、阻塞队列
读写锁
ReadWriteLock 仅有ReentrantReadWriteLock一个实现类。在Lock的基础上又增加了读和写的区分。共享读,独占写。其实使用和Lock一致,只是让Lock有了读和写的区分。
| 修饰符和类型 | 方法 | 描述 |
|---|---|---|
| Lock | readLock() | 返回用于读取的锁。 |
| Lock | writeLock() | 返回用于写入的锁。 |
使用示例
package com.Gw;
import java.sql.Time;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class rw {
public static void main(String[] args) {
MyCache myCache = new MyCache();
for (int i = 0; i < 6; i++) {
new Thread(()->{
myCache.write();
myCache.read();
}, String.valueOf(i)).start();
}
}
}
class MyCache{
private ReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
public void read(){
reentrantReadWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "开始读");
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName() + "读ok");
} catch (Exception e) {
e.printStackTrace();
} finally {
reentrantReadWriteLock.readLock().unlock();
}
}
public void write(){
reentrantReadWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "开始写");
TimeUnit.SECONDS.sleep(2);
System.out.println(Thread.currentThread().getName() + "写ok");
} catch (Exception e) {
e.printStackTrace();
} finally {
reentrantReadWriteLock.writeLock().unlock();
}
}
}
阻塞队列
当线程池中的线程不够使用时,会使用阻塞队列。BlockingQueue四组api处理异常的方式不同,有ArrayBlockingQueue和LinkedBlockingQueue。在创建队列时声明队列大小和元素类型ArrayBlockingQueue<Object> objects = new ArrayBlockingQueue<>(5);
| 方式 | 抛出异常 | 有返回值,不抛出异常 | 阻塞等待 | 超时等待 |
|---|---|---|---|---|
| 添加 | add | offer() | put() | offer(),带有时间参数 |
| 移除(移除后返回移除的元素) | remove | poll() | take() | poll(),带有时间参数 |
| 检测队首元素 | element | peek | - | - |
同步队列(SynchronousQueue):阻塞队列,大小为1,放进一个元素后,必须取出才能放下一个元素
8、池化技术和线程池
线程复用、可以控制最大并发数、管理线程
三大方法
Executors.newSingleThreadExecutor(); //单线程线程池
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); //设置成特定大小的线程池,其中Runtime.getRuntime().availableProcessors()是获得当前cpu核心数
Executors.newCachedThreadPool(); //有缓存,可伸缩的线程池
但是一般不用Excutors直接创建线程池,三个方法本质上调用的还是ThreadPoolExcutor来创建的,在使用ThreadPoolExcutor()创建,让自己清楚线程池的具体信息

七大参数
关于ThreadPoolExcutor()七大参数的说明
public ThreadPoolExecutor(int corePoolSize, //核心数,业务数量少的时候线程池开启的线程数
int maximumPoolSize, //最大线程数,当阻塞队列满了会触发最大并发
long keepAliveTime, //超时没有人调用就会释放线程池中没有使用的窗口
TimeUnit unit, //超时的单位
BlockingQueue<Runnable> workQueue, //阻塞队列,允许在线程池中等待的线程队列
ThreadFactory threadFactory, //线程工厂,用来创建线程的,不动
RejectedExecutionHandler handler /*拒绝策略*/) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
关于maximumPoolSize最大值的设置:
- cpu密集型:与cpu核心数相同,通过Runtime.getRuntime().availableProcessors()获取当前用户的核心数
- io密集型:判断程序中十分耗io的线程,设置成io线程数的两倍,让线程池有多余的窗口处理其他线程
四种拒绝策略
拒绝策略就是当线程池达到最大并发,并且阻塞队列同时满了,对于新来的线程请求进行的处理

AbortPolicy //线程池和阻塞队列都满了,对于新来的线程,不进行处理,并抛出异常
DiscardPolicy //处理线程不会抛出异常
DiscardOldestPolicy //队列满了尝试去和队列中最早的进行竞争,即使失败了也不会抛出异常
CallerRunsPolicy //哪里来的去哪里,哪个线程发来的让哪个线程执行
小结
线程池可以有效地管理线程:它可以管理线程的数量,可以避免无节制的创建线程,导致超出系统负荷直至崩溃。它还可以让线程复用,可以大大地减少创建和销毁线程所带来的开销。 线程池需要依赖一些参数来控制任务的执行流程,其中最重要的参数有:corePoolSize(核心线程数)、workQueue(等待队列)、maxinumPoolSize(最大线程数)、handler(拒绝策略)、keepAliveTime(空闲线程存活时间)。
当我们向线程池提交一个任务之后,线程池按照如下步骤处理这个任务:
- 判断线程数是否达到corePoolSize,若没有则新建线程执行该任务,否则进入下一步。
- 判断等待队列是否已满,若没有则将任务放入等待队列,否则进入下一步。
- 判断线程数是否达到maxinumPoolSize,如果没有则新建线程执行任务,否则进入下一步。
- 采用初始化线程池时指定的拒绝策略,拒绝执行该任务。
- 新建的线程处理完当前任务后,不会立刻关闭,而是继续处理等待队列中的任务。如果线程的空闲时间达到了keepAliveTime,则线程池会销毁一部分线程,将线程数量收缩至corePoolSize。
第2步中的队列可以有界也可以无界。若指定了无界的队列,则线程池永远无法进入第3步,相当于废弃了maxinumPoolSize参数。这种用法是十分危险的,如果任务在队列中产生大量的堆积,就很容易造成内存溢出。JDK为我们提供了一个名为Executors的线程池的创建工具,该工具创建出来的就是带有无界队列的线程池,所以一般在工作中我们是不建议使用这个类来创建线程池的。
拒绝策略主要有4个:让调用者自己执行任务、直接抛出异常、丢弃任务不做任何处理、删除队列中最老的任务并把当前任务加入队列。这4个拒绝策略分别对应着RejectedExecutionHandler接口的4个实现类,我们也可以基于这个接口实现自己的拒绝策略。
9、四大函数式接口
新时代的程序员:lambda表达式、链式编程、函数式接口、Stream流式计算
函数式接口:只有一个方法的接口
@FunctionalInterface //函数式接口
public interface Runnable {
public abstract void run();
}
Function
函数型接口,一个参数,一个返回值
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
//使用lambda表达式简化
Function<Object, Object> function = (/*参数*/)->{/*函数体*/}
Function<String, String> function= (str) -> {return str;};
//等价于Function<String, String> function= str -> str;
System.out.println(function.apply("111"));
Consumer
消费性接口,只有参数,没有返回值
Consumer<String> consumer = (str)->{System.out.println(str);};
consumer.accept("1111");
Predicate
断定型接口,只接受一个参数,返回一个布尔值
Predicate<String> predicate =str->str.isEmpty();
System.out.println(predicate.test(""));
Supplier
供给型接口,没有输入,只有返回值
Supplier<Integer> supplier = ()->1024;
System.out.println(supplier.get());

 浙公网安备 33010602011771号
浙公网安备 33010602011771号