爬取QQ空间好友点赞数据——Python+PyQt5(北邮期末python大作业)
效果展示:
![]()
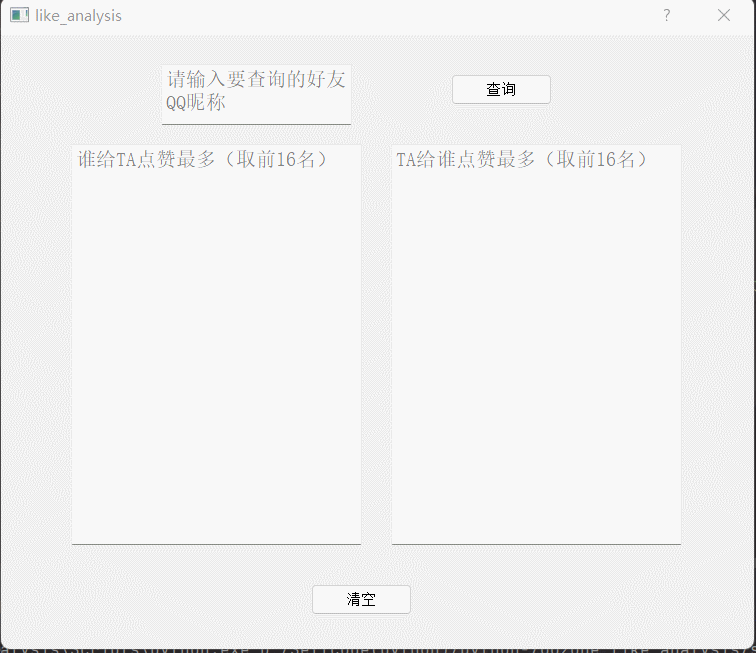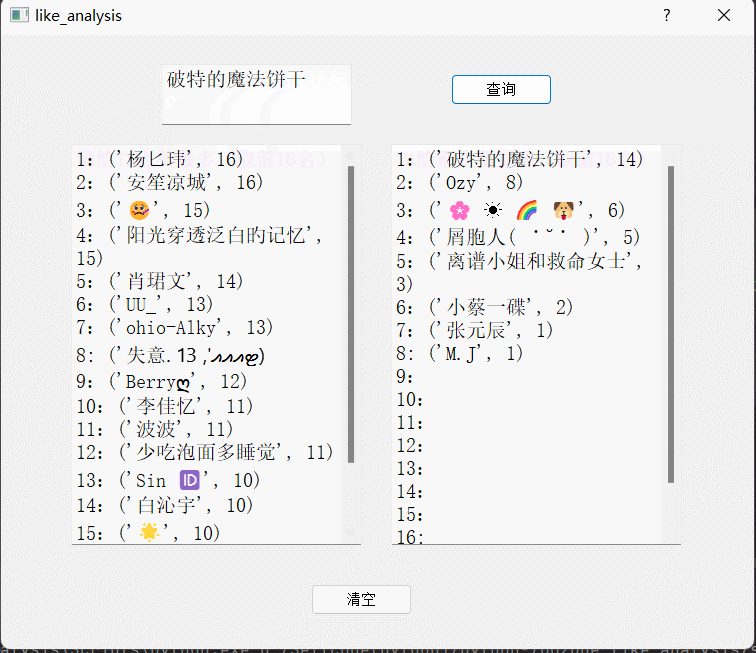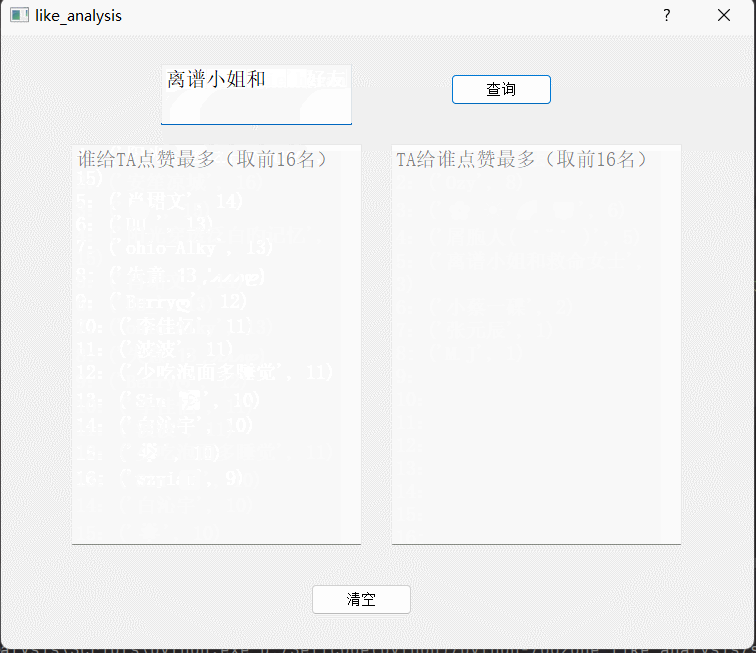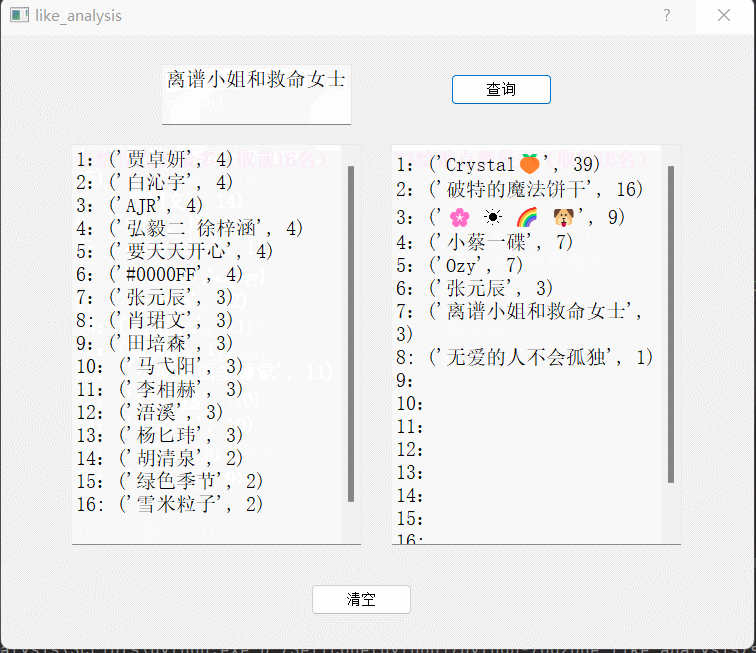
功能介绍:输入好友昵称,获取在QQ空间中,谁给TA点赞最多和TA给谁点赞最多的数据
目录
一,获取登录信息
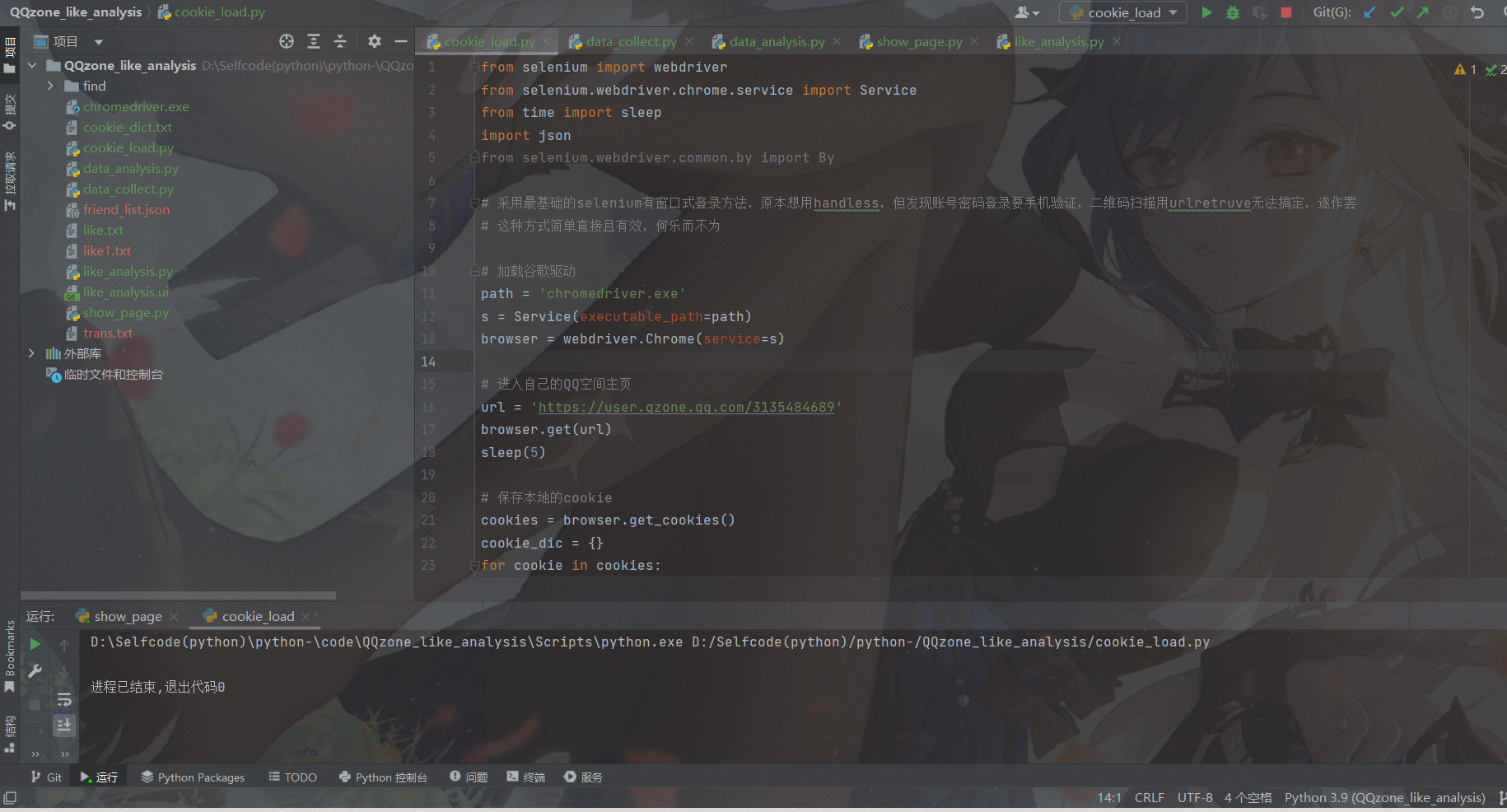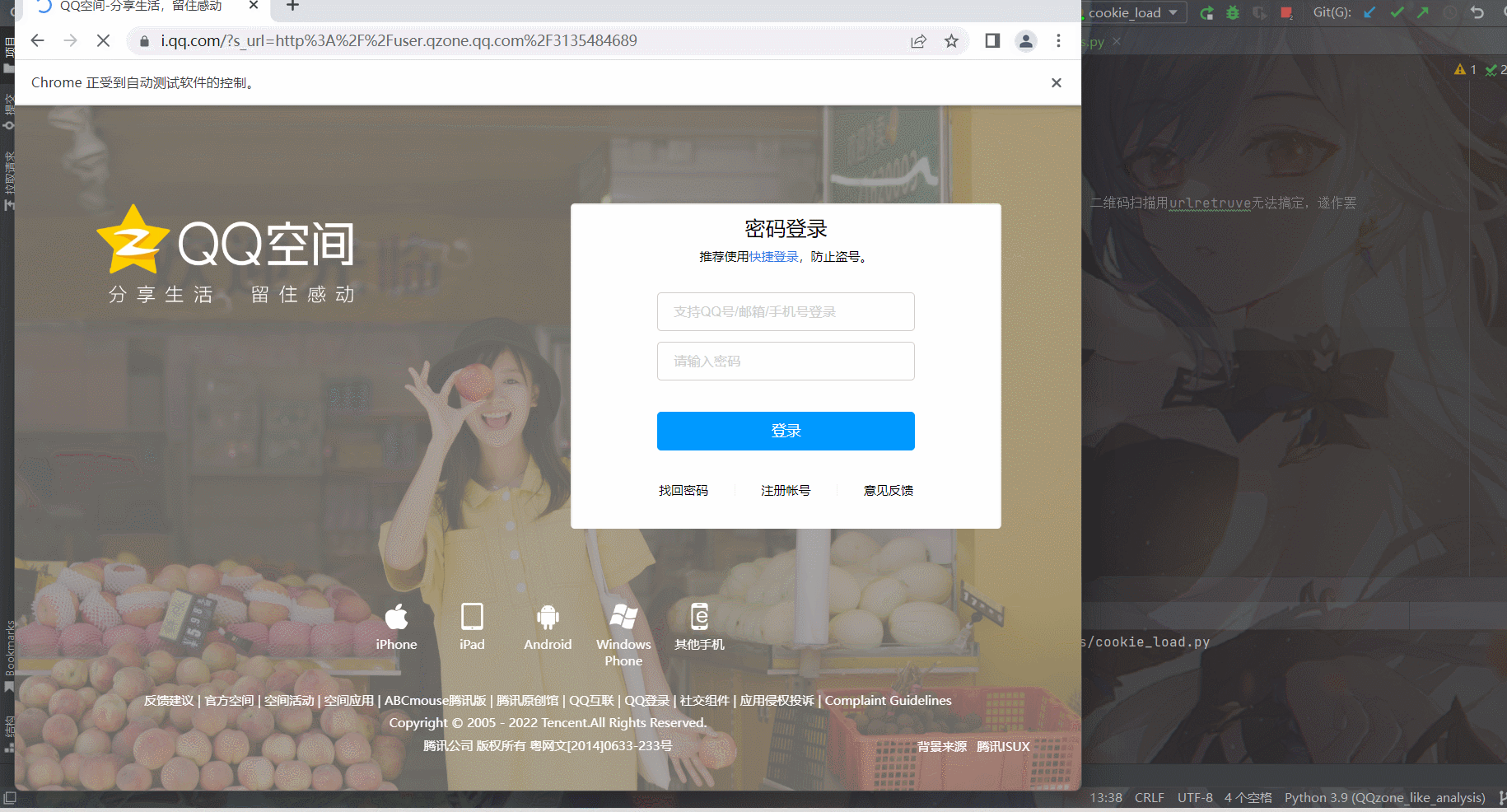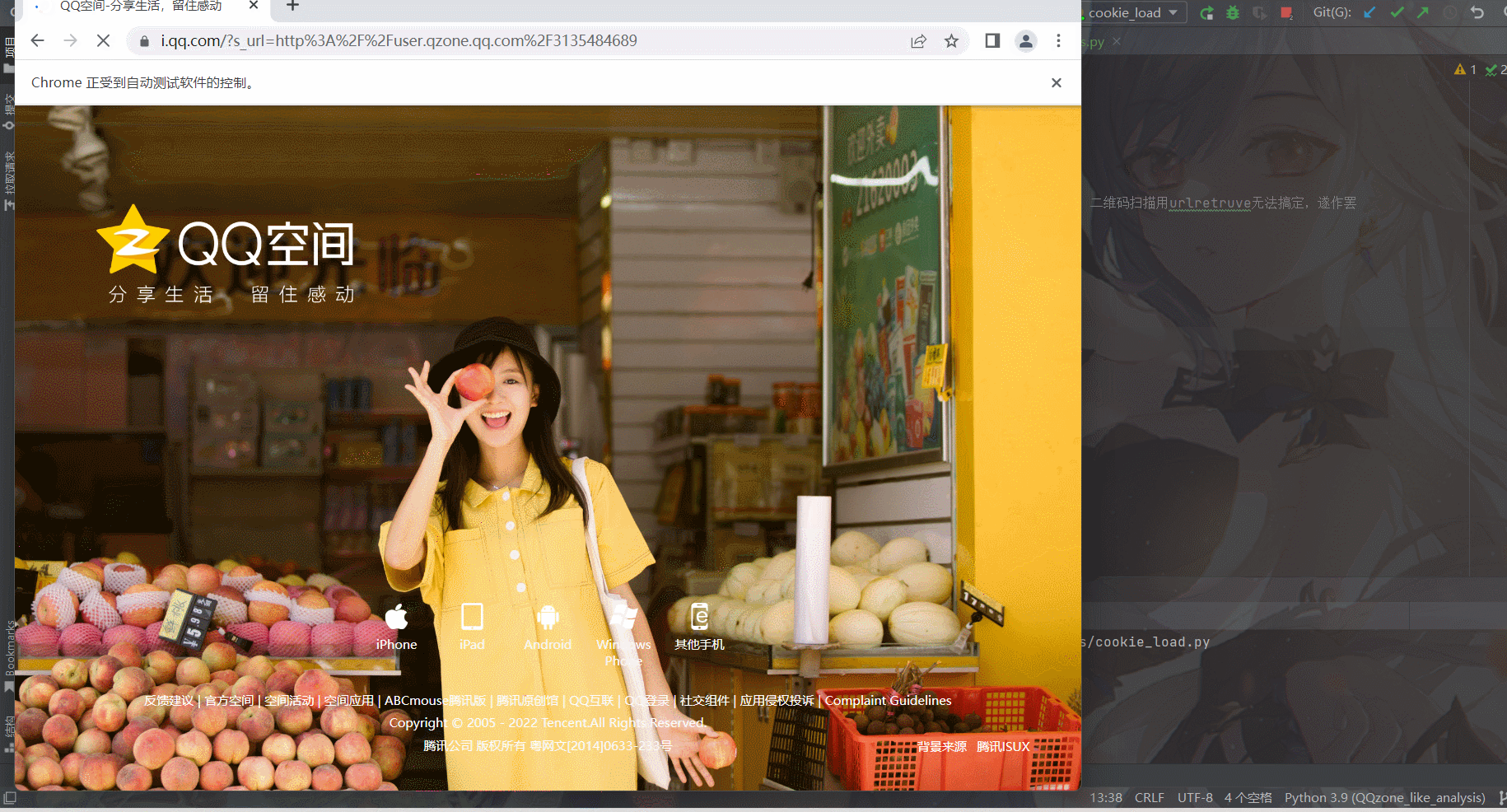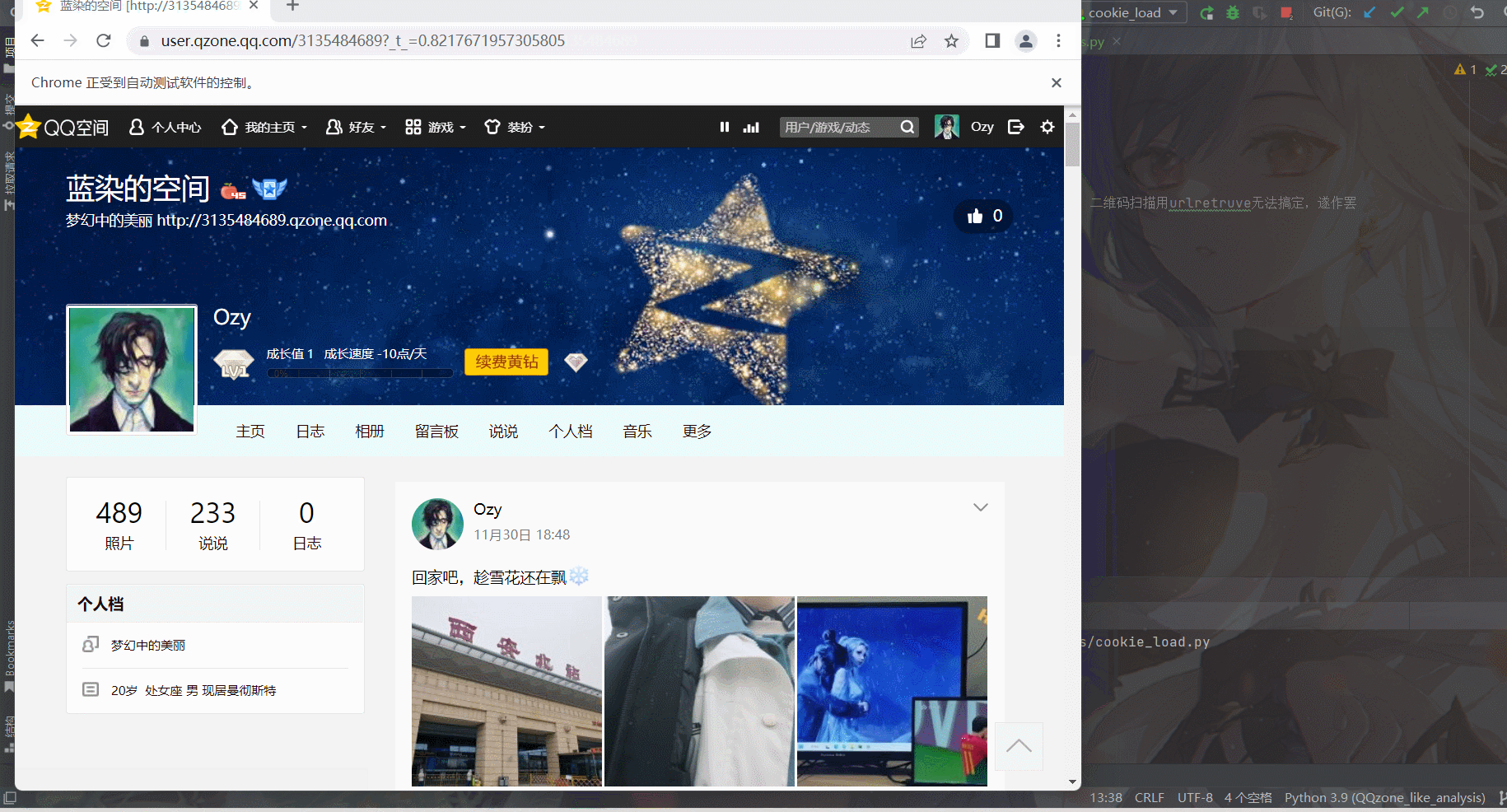
既然决定了要对QQ空间进行信息爬取,那么作为一个需要账号密码进入的私人网页,首先需要的就是请求里的cookie信息,这样我们在后续爬取的过程中才能跳过登录,直接获取信息。
原本想使用Chrome handless的方式无窗口登录,但传统的账号密码登录需要手机验证码,尝试扫描二维码的方式却又发现使用urlretrive下载的二维码图片会被刷新更新而不可使用。
最后选择了最基础的selenium方式,打开浏览器界面,只需要简单登录,等待5s后页面会自动关闭,而后也就获取到了cookie信息,简单明了而又方便。
![]()
这里使用的代码是第一个程序文件:cookie_load.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from time import sleep
import json
from selenium.webdriver.common.by import By
# 采用最基础的selenium有窗口式登录方法,原本想用handless,但发现账号密码登录要手机验证,二维码扫描用urlretruve无法搞定,遂作罢
# 这种方式简单直接且有效,何乐而不为
# 加载谷歌驱动
path = 'chromedriver.exe'
s = Service(executable_path=path)
browser = webdriver.Chrome(service=s)
# 进入自己的QQ空间主页
url = 'https://user.qzone.qq.com/你的QQ'
browser.get(url)
sleep(5)
# 保存本地的cookie
cookies = browser.get_cookies()
cookie_dic = {}
for cookie in cookies:
if 'name' in cookie and 'value' in cookie:
cookie_dic[cookie['name']] = cookie['value']
with open('cookie_dict.txt', 'w') as f:
json.dump(cookie_dic, f)
二, 进行数据爬取
1.寻找要爬取的点赞信息
首先我们进入空间,点击说说,进入说说模块 
![]()
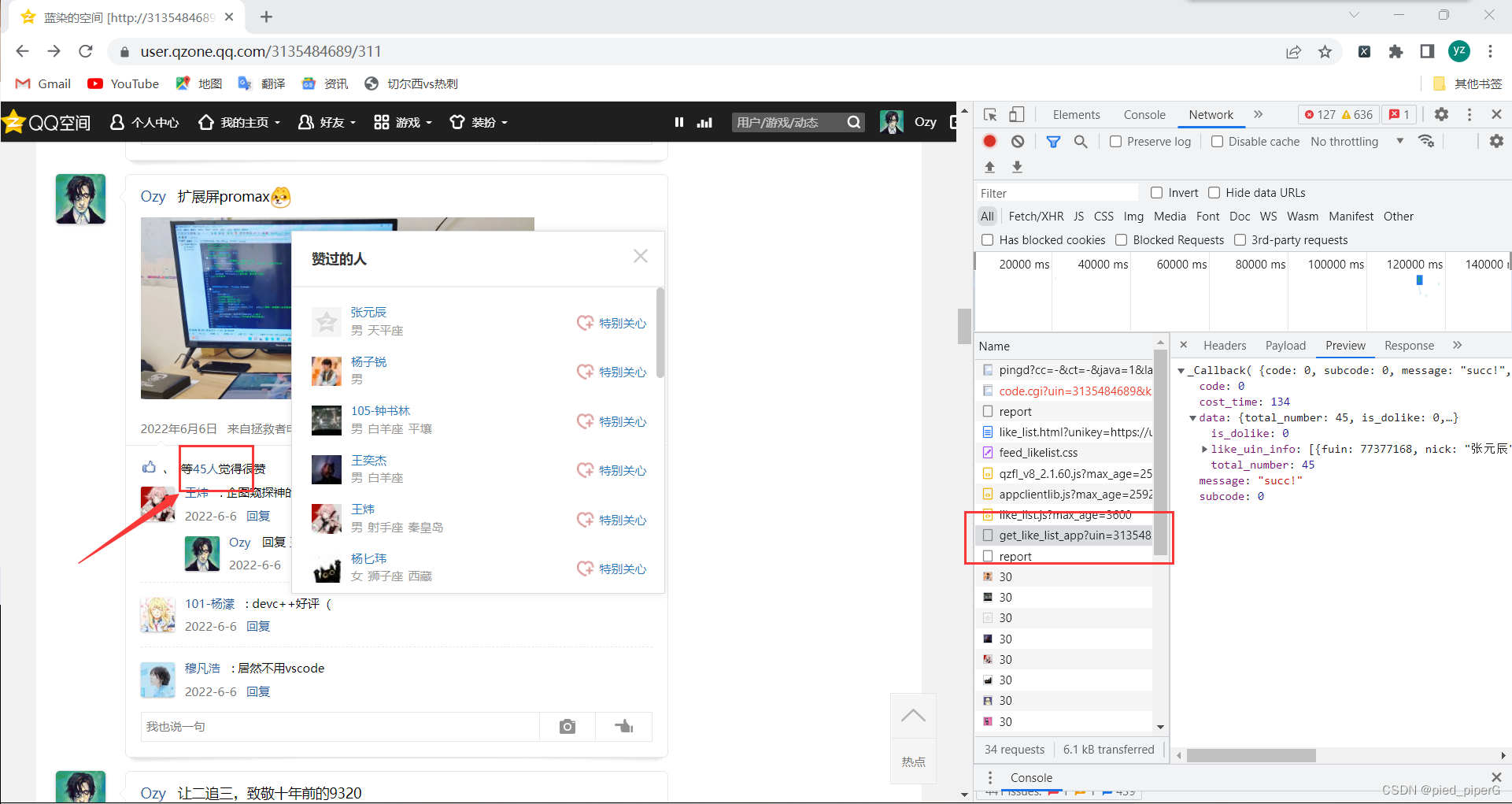
而后找到其中一条说说,点击“等45人”处,会弹出点赞的好友列表
观察右侧Network响应,会发现有一个get_like_list_app,通过preview可以看出其中包含了所有点赞好友的信息,可以说是很详细了,昵称,QQ号,性别,星座,地区都有。
这时我们可以确定,它就是我们要爬取的信息辣
![]()
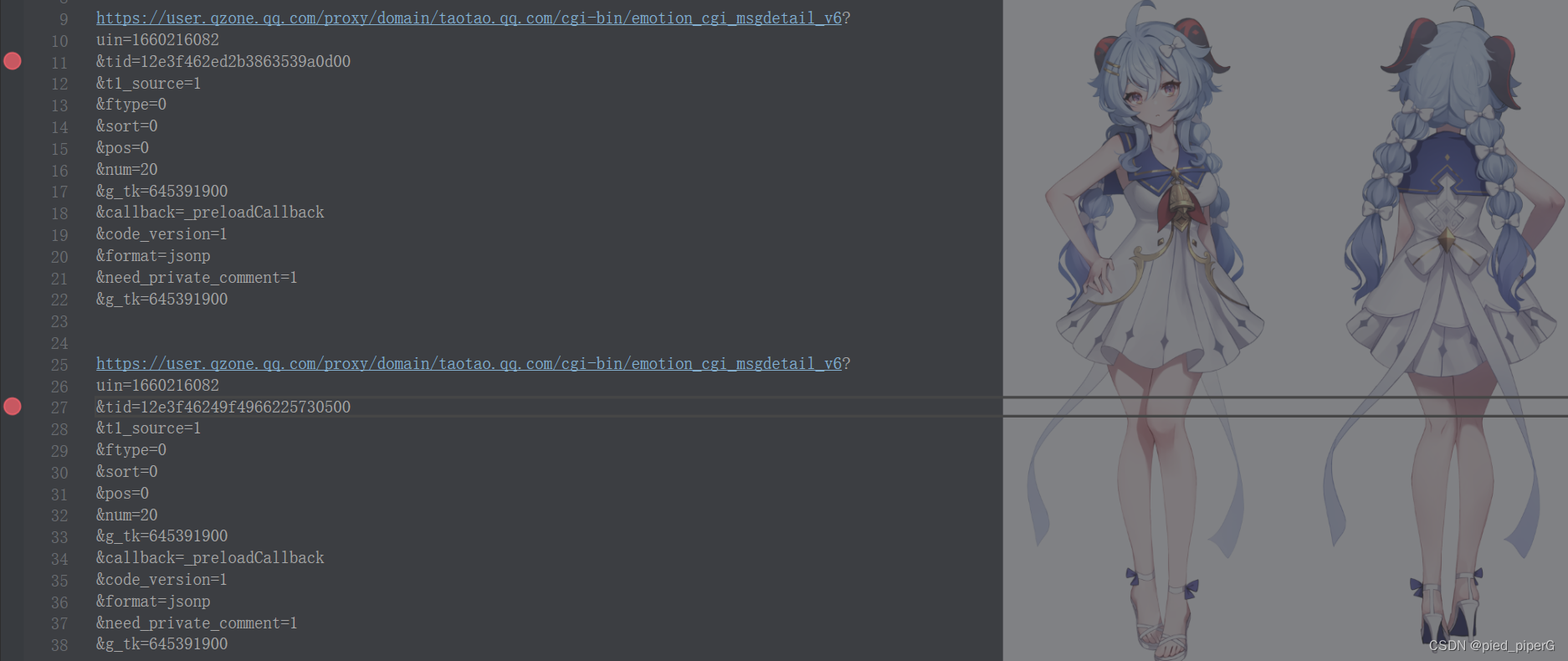
此时就要找每一条说说的get_like_list的url之间的规律,观察相邻几条说说的get_like_list的url,可以发现,只有参数tid是不同的,每一条说说,对应唯一的tid
![]()
之后我们的任务就是寻找每一个说说所对应的tid,也就是定位每一个说说的信息了,让我们回到说说主页,刷新界面,继续寻找包含了整页说说信息的端口
实现这部分功能爬取的代码如下,其中的参数m是下一个部分获得的说说信息
# 获取点赞信息数据(从说说“等人”处发现)
def get_like(self, m, qq, name):
g_tk = self.get_gtk()
uin = self.get_uin()
tid = m['tid']
# 原始链接
url_like = 'https://user.qzone.qq.com/proxy/domain/users.qzone.qq.com/cgi-bin/likes/get_like_list_app?'
# 进行拼接
data_like = {
'uin': uin,
'unikey': 'http://user.qzone.qq.com/' + str(qq) + '/mood/' + str(tid) + '.1',
'begin_uin': 0,
'query_count': 60,
'if_first_page': 1,
'g_tk': g_tk
}
data_like_encode = urllib.parse.urlencode(data_like)
url_like = url_like + data_like_encode
res = requests.get(url_like, headers=header, cookies=cookie)
res.encoding = 'UTF-8'
like_data = re.findall('\((.*)\)', res.text, re.S)[0]
like_message = json.loads(like_data)
# 数据量太大,请求繁忙导致部分页码可能无法请求到,错误跳出
try:
for l in like_message['data']['like_uin_info']:
file_like.write(name + '<-' + str(l['nick']) + '\n')
except KeyError:
print(name)
print(like_message)2.定位每一条说说
回到说说主页,刷新界面,观察右侧端口,发现其中emotion_cgi_msglist_v6
点开发现,它包含了一整页说说的详细信息

![]()
通过爬取它的内容,我们就可以定位到当页的每一条说说
而后和上一步一样,观察每一页说说的url,寻找规律,发现不同页码的 emotion_cgi_msglist_v6的url,只有参数pos发生了变化,第一页的pos=0,第二页的pos=20,以此类推。
这样一来,我们就能够通过拼接url来批量爬取所有页码的说说了
通过函数locate来实现这个功能,代码如下:
'''
通过此函数对每一个人的QQ空间进行爬取
先爬取说说每一页整页数据,通过对比发现,一页有二十个说说,不同页的说说url受参数pos控制
然后根据每一页的信息对每一个说说进行定位
'''
def locate(self, qq, name):
g_tk = self.get_gtk()
uin = self.get_uin()
# 标记第几页
page = 1
pos = 0
# 循环爬取每一页的内容
while True:
# 初始url
emotion_url = 'https://user.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6?'
# 对url进行拼接
emotion_data = {
'uin': qq,
'pos': pos,
'num': 20,
'hostUin': qq,
'replynum': 100,
'callback': '_preloadCallback',
'code_version': 1,
'format': 'jsonp',
'need_private_comment': 1,
'g_tk': g_tk,
}
emotion_url = emotion_url + urllib.parse.urlencode(emotion_data)
# 对内容进行读取
res = requests.get(emotion_url, headers=header, cookies=cookie)
r = re.findall('\((.*)\)', res.text)[0]
with open(f'find/testfind{name}_{page}.json', 'w', encoding='utf-8') as fp:
fp.write(r)
message = json.loads(r)
print(f'成功读取{name}的第{page}页说说')
# 进行翻页操作
pos += 20
page += 1
# 判断是否结束操作
# 没有说说
if 'msglist' not in message:
break
# 爬取完毕
if message['msglist'] == None:
print(f'{name}的空间爬取结束')
break
# 对每一个说说进行处理
for m in message['msglist']:
# 获取点赞信息数据
self.get_like(m, qq, name)3.获取所有QQ好友信息
我们希望能够得到一个比较大的数据量——即爬取所有好友的说说信息,而后展开数据分析。
因此在上述步骤我们已经拥有爬取一个好友的所有说说信息之后,我们需要获得所有好友的信息(昵称+QQ号),从而循环爬取所有好友的信息。
获得所有好友信息的端口仍然从QQ空间找到。
点开我的说说,点击“@”按键,系统将弹出所有的好友供你选择@谁,同时观察右侧的network端口,出现了friend_show_qqfriends.cgi,一个从名称上看起来就很像我们要寻找的端口,进入发现,果然包含了所有好友的信息。

![]()
之后仍然和之前的步骤一样,不过这次省去了寻找url规律的过程,通过requests方法获得数据并处理,就得到了我们所有的好友数据。
这部分的功能通过函数get_friend实现,代码如下:
# 获取好友信息,并将其存在一个列表中
# 获取所有的好友{姓名,备注,QQ号,头像}
def get_friend(self):
# @按键的原始url,自己的url需要进行参数拼接
at_url = 'https://user.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend_show_qqfriends.cgi?'
g_tk = self.get_gtk()
uin = self.get_uin()
data = {
'uin': uin,
'do': 1,
'g_tk': g_tk
}
# urlencode方法,进行url拼接
new_data = urllib.parse.urlencode(data)
at_url = at_url + new_data
# requests方法,获取网页数据
res = requests.get(at_url, headers=header, cookies=cookie)
# 获取好友信息的数据
friend_json = re.findall('\((.*)\)', res.text, re.S)[0]
with open('friend_list.json', 'w', encoding='utf-8') as fp:
fp.write(friend_json)
# 将数据转换为python中的字典形式
friend_dict = json.loads(friend_json)
friend_result_list = []
# 循环将好友的姓名qq号存入列表中(需要观察上面的friend_list.json文件)
for friend in friend_dict['items']:
friend_result_list.append([friend['name'], friend['remark'], friend['uin'], friend['img']])
# 得到的好友字典是{name:remark:uin:img}格式的
# print(friend_result_list)
return friend_result_list
# 裁剪好友列表函数
def refine(self):
r_list = []
for friend in self.get_friend():
r_list.append([friend[2], friend[0]])
return r_list
# 判断是否为共同好友的函数,返回一个QQ号组成的列表
def uinlist(self):
uin_list = []
for friend in self.get_friend():
uin_list.append(friend[2])
return uin_list4.Threadpool多线程处理
在完成了上述的工作后,我们已经具备了爬取所有好友说说点赞信息的能力。但实际操作起来爬取一个好友的一页说说就需要2~3秒的时间,爬取所有好友的所有说说时间不可估计。
因此我们需要提高爬虫的速度,采用threadpool多线程处理的方法,有一个固定的模板,因此操作起来相对简单,套用即可,使用后效果甚佳,速度大大提升。
通过函数start实现,代码如下:
# 开始运行端口
# 使用多线程threadpool进行实现,提升效率
def start(self):
r_list = self.refine()
# 开启15个线程
pool = threadpool.ThreadPool(10)
# 提交任务到线程池
requests = threadpool.makeRequests(self.get, r_list)
# 开始执行任务
for req in requests:
pool.putRequest(req) # 提交
pool.wait()5.参数获得与文件处理
这里回顾一下第二部分数据爬取的两个细节问题。
参数获得,在进行url的parse.urlencode拼接时,需要两个关键的参数:uin和gtk,其中uin就是自己的qq号码,通过cookie信息可以得到,gtk是一个重要的参数,几乎所有url拼接中都要用到它,它的获得方式我们在网上可以查到,是通过函数计算而得 的。
通过get_uin和get_gtk两个函数可以获得两个参数,代码如下:
# 得到uin,即自己的QQ账号,需要进行一下裁剪
def get_uin(self):
uin = cookie['uin'][1:]
return uin
# 获取gtk参数,计算方法从网上可查的(重要参数)
def get_gtk(self):
p_skey = cookie['p_skey']
h = 5381
for i in p_skey:
h += (h << 5) + ord(i)
g_tk = h & 2147483647
return g_tk第二部分获得的数据如何为之后的数据分析所用呢,我们这里采取的是存为一个like.txt的方式,供后续读取。
6.第二部分代码
第二部分整体由文件data_collect.py实现
代码如下: