06 数据同步:主从库如何实现数据一致
本篇重点
主从库同步原理、如何应对主从库间网络断连风险
主从库同步:全量复制、基于长连接的命令传播、增量复制——应对主从库间的网络断连
背景
若Redis只有一个实例运行,当该实例服务宕机后,宕机这段时间内Redis无法为新来的数据请求提供服务。
Redis采取的解决方案是——增加副本冗余量,即将一份数据同时保存在多个实例上——Redis主从库模式
多实例保存同一份数据,需要考虑的问题:
- 副本间的数据如何保持一致?——数据同步
- 数据读写操作可以发给所有实例吗?——数据读写
前言
Redis高可靠性的保证
- 数据尽量少丢失——持久化存储(AOF/RDB)
- 服务尽量少中断——主从库(本质是增加副本冗余量)
Redis主从库模式
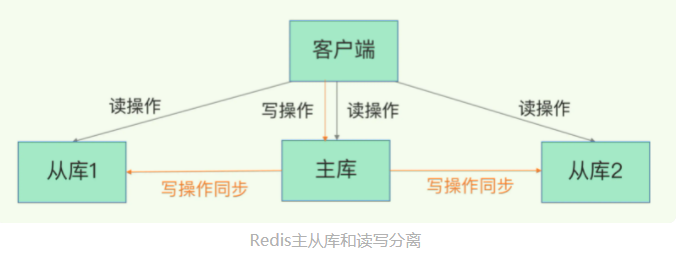
- Redis主从库模式:保证数据副本一致性,且主从库 “读写分离”
- 读写分离:
- 读操作:主从库都可接收
- 写操作:主库接收并执行,然后由主库将写操作同步给从库
- 主从库读写分离
- 主从库同步的三个问题:
- 实现原理——如何完成主从库
- 主库数据是一次性传给从库,还是分批同步?
- 主从库间网络断连了,数据还能保持一致吗?
1. 主从库第一次同步
replicaof命令——建立主从库关系[1]- 某Redis实例执行:
replicaof 主库IP 主库port - 该实例与主库建立主从库关系,成为主库的从库
- 某Redis实例执行:
- 主从库第一次同步的三个阶段(某实例第一次执行
replicaof与主库建立连接)- 建立连接,协商同步
- 从库->主库:psync
- 主库->从库:FULLRESYNC
- 从库->主库:psync
- 数据同步
- 主库->从库:RDB快照
- 从库:清楚旧有数据,加载RDB
- 主库在数据同步中,执行完RDB后,正常接收 & 执行的写操作会被写入 replication buffer 中
- 主库->从库:RDB快照
- 同步数据同步期间到来的写操作——replication buffer
- 主库->从库:replication buffer
- 从库:重新执行replication buffer中的操作
- 主库->从库:replication buffer
- 建立连接,协商同步
- Redis第一次主从同步流程

- 命令及参数解释:
psync命令形式:psync runID offsetrunID:Redis实例ID,首次连接主库ID未知,传?offset:复制进度,第一次复制传-1FULLRESYNC: 全量复制,第一次建立连接采用全量复制
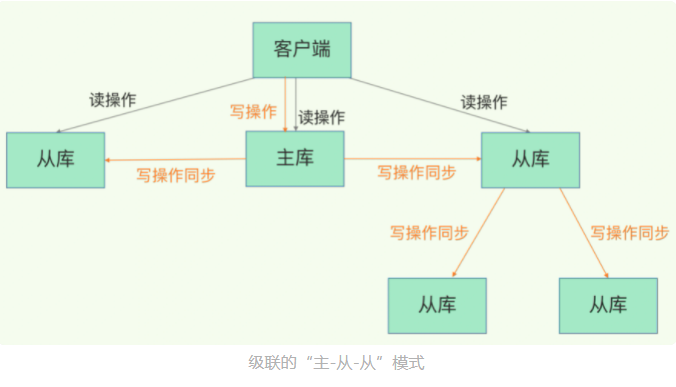
Q:主从库同步中,主库执行RDB快照时,需要fork bgsave子进程,若从库数量很多,则主库fork的压力就会增加,如何应对这种问题?缓解主库压力?
A:主从级联模式——“主—从—从”,在从库间建立“主从”关系,分担主库全量RDB的压力
2. 主从级联模式:分担全量复制时的主库压力
- “主—从—从”模式:选择一个从库(内存配置较高),级联其他从库(replicaof)
3. 基于长连接的命令传播——避免频繁建立连接
- 主从库建立网络连接后,此时主从库间已经完成了一次全量复制,后续Redis实例会维护这个网络连接,在这个网络连接上进行 “写操作同步”
- “主—从—从”模式
4. 增量复制——主从网络断连后的解决方案
增量复制——仅同步断连期间主库收到的命令
repl_backlog_buffer——环形缓冲区,存储主库收到的写命令——记录主/从的写/读进度,通过offset
- master_repl_offset:主库写offset,递增值
- slave_repl_offset: 从库读offset,递增值
- 主从库连接期间,master_repl_offset == slave_repl_offset
- 主从库断连后,master_repl_offset >= slave_repl_offset
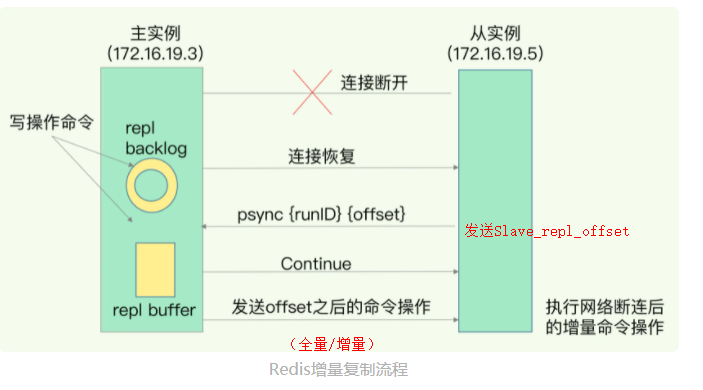
Redis增量复制流程
- 断连期间
- 主库->replication buffer: 存储写命令(用于写操作同步)
- 主库->repl_backlog_buffer: 存储写命令
- 主库:记录 master_repl_offset
- 连接恢复时
- 从库->主库:
psync 主库runID slave_repl_offset - 主库->从库:slave_repl_offset之后的写命令(全量/增量)
- 从库:执行这些写命令
- 从库->主库:
- Redis增量复制流程
Q: 主库写入速度快,从库读取慢,导致未读的命令被新写的命令覆盖,引起的主从库数据不一致问题如何预防?
A:
- 调整 repl_backlog_size 大小,通常 = 缓冲空间大小*2
- 或采用切片集群分担单个主库的请求压力(将写请求分散到集群中)
Q: 主从断连时间过长,导致slave_repl_offset上的未读数据已经被新写入操作覆盖(同上一个问题),如何数据同步?
A: 主库采用全量复制
- 主库判断被覆盖—— master_repl_offset - slave_repl_offset > repl_backlog_size (个人猜想)
- 若上式成立,则执行全量复制,否则增量复制
Q: 本篇讨论的都是“主库如何同步数据给从库”、“断连恢复后主库如何同步断连期间的数据给从库”的问题,那么当主库挂了,Redis如何对外提供服务?此时从库能起到什么样的作用?——主从库模式的重要功能——服务尽量少中断
A: Redis的哨兵机制
图片来源于极客时间专栏《Redis核心技术与实战》
Redis5.0前使用
slaveof命令 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号