02 Redis的数据结构
-
Redis——“快”:μs速度找到KV并完成操作。依赖于
a. 内存
b. 数据结构 -
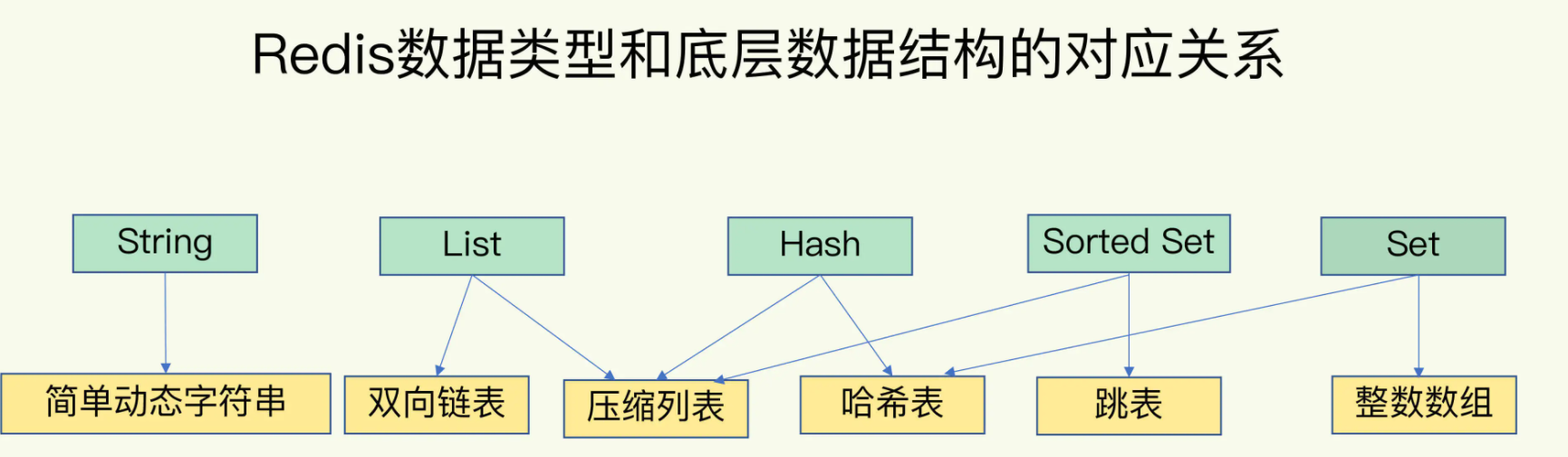
6种底层数据结构 & 5种Redis数据类型
- Redis的“快”中的“慢操作”
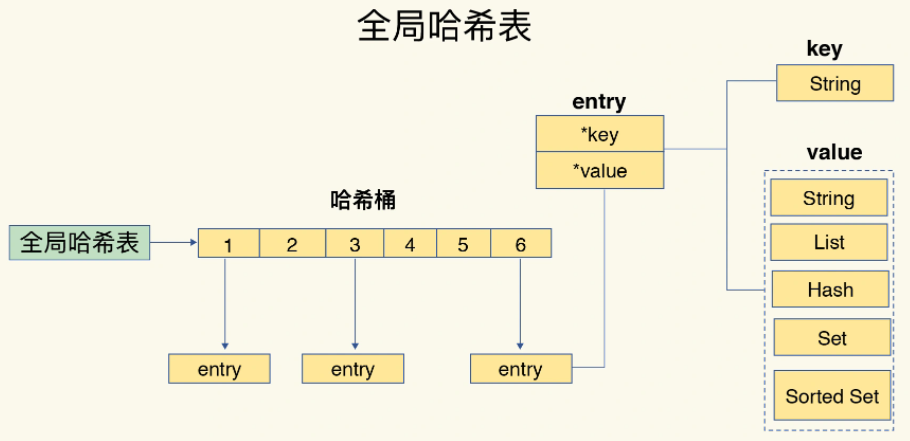
- KV用哈希表存储,哈希表结构=数组+哈希桶
哈希表是一个指针数组,每个元素是一个指向entry结构体的指针(哈希桶)
entry包含两个元素:
- *key——指向key的指针
- *value——指向value的指针
- 哈希表查找过程主要依赖于哈希计算,与数据量多少无直接关系
- 哈希表存储要解决的问题
哈希冲突——链式哈希
rehash可能带来的操作阻塞——渐进式rehash
- 哈希冲突
- 解决:链式哈希——同一个哈希桶中多个entry用链表连接
- entry结构体中增加
*next指针指向下一个entry 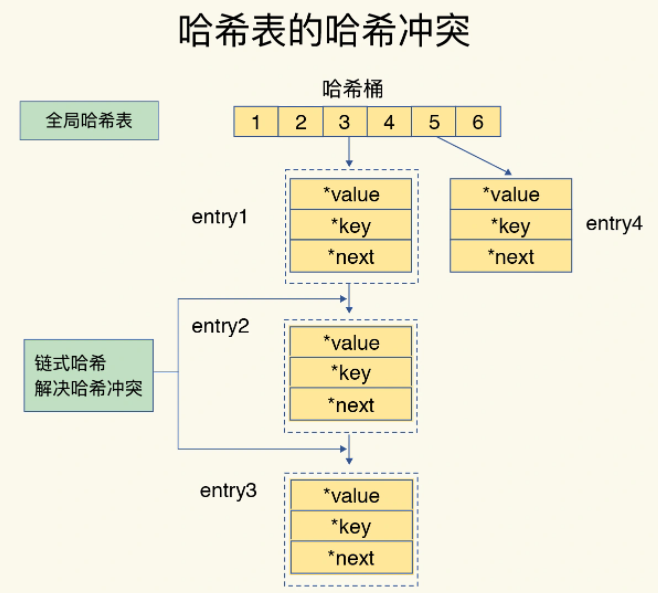
- rehash可能带来的操作阻塞
- 背景:链式哈希潜在问题——同一哈希桶内链接元素过多(同一桶内的冲突过多),导致查找KV时的时间消耗增加。
- 解决:rehash——增加现有哈希桶数量,对entries进行重排,以减少单个桶内的冲突
- rehash具体操作
Redis默认使用两个全局哈希表,表1rehash时
a. 给表2分配比表1更大的空间(比如表1的2倍大小)
b. 将表1数据重映射©到表2
c. 释放表1空间 - rehash中处理重映射©的时间会随着entries的增加而增加,涉及到了大量的数据copy操作,数据量大的情况下,极有可能阻塞Redis主线程,因此Redis采用渐进式rehash。
- 渐进式rehash
原理:将表1每个桶的“重映射©”分散到Redis的每次请求上
- 集合数据的操作效率
集合数据的操作效率取决于两个因素:集合类型的底层数据结构、具体的操作
-
集合类型的底层数据结构:整数数组、双向链表、哈希表、压缩列表、跳表
-
压缩列表:
有序数组
表头增加3个字段:zlbytes——列表长度、zltail——列表尾偏移、zllen——列表中的entry个数
表尾用zlend——列表结束标志

-
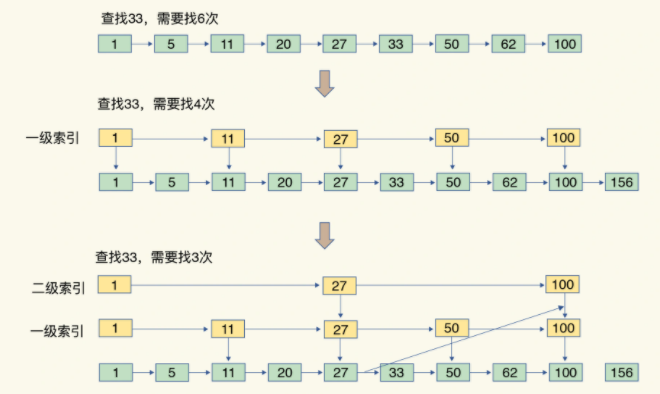
跳表:
有序链表上加多级序列
通过索引位置的跳转实现数据快速定位
索引通过链表连接
-
查找时,各个集合类型底层数据结构的时间复杂度表
底层数据结构 时间复杂度 哈希表 O(1) 跳表 O(logN) 双向链表 O(N) 压缩列表 O(N) 整数数组 O(N)
-
-
不同操作的复杂度
单元素操作是基础
范围操作非常耗时
统计操作通常g高效
例外情况只有几个- 范围操作: 集合类型中的遍历操作
- 统计操作:比如集合中元素个数的统计
图片来源于极客时间专栏《Redis核心技术与实战》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号