C/C++ #define 宏定义
#define命令是C语言中的一个宏定义命令,它用来将一个标识符定义为一个字符串,该标识符被称为宏名,被定义的字符串称为替换文本。
定义宏的作用一般是用一个短的名字代表一个长的字符串。
主要参考与:https://www.cnblogs.com/fnlingnzb-learner/p/6903966.html
一、一般形式为:
1)#define 标识符 字符串
这就是已经介绍过的定义符号常量。
如:#define PI 3.1415926
2)还可以用#define命令定义带参数的宏定义。其定义的一般形式为:
#define 宏名(参数表) 字符串
如:#define S(a, b) a*b //定义宏S(矩形面积),a、b为宏的参数
使用的形式如下:
area=S(3, 2);
用3、2分别代替宏定义中的形式参数a和b,即用3*2代替S(3, 2)。因此赋值语句展开为:
area=3*2;
由于C++增加了内置函数(inline),比用带参数的宏定义更方便,因此在C++中基本上已不再用#define命令定义宏了,主要用于条件编译中。
二、带参数的宏替换最好加括号,否则可能会出错
需要注意的就是在涉及运算或着其他一些情况下,要加上括号来避免结合律影响运算结果
如:
#define add(x, y) (x + y)
5*add(2,3),你期望的结果是25,但是,在不加括号的情况下 5*2+3 结果是30.
三、一个标识符被宏定义后,该标识符便是一个宏名。这时,在程序中出现的是宏名,在该程序被编译前,先将宏名用被定义的字符串替换,这称为宏替换,替换后才进行编译,宏替换是简单的替换。
四、当需要换行时,需要在行尾加上\ 比如:
1 #define NULL_RETURN(varName) \
2 if(varName == nullptr) \
3 { \
4 return;\
5 } //程序的结束处,即最后不用加符号 \
五、宏替换发生的时机
为了能够真正理解#define的作用,让我们来了解一下对C语言源程序的处理过程。当我们在一个集成的开发环境如Turbo C中将编写好的源程序进行编译时,实际经过了预处理、编译、汇编和连接几个过程。其中预处理器产生编译器的输出,它实现以下的功能:
(1)文件包含
可以把源程序中的#include 扩展为文件正文,即把包含的.h文件找到并展开到#include 所在处。
(2)条件编译
预处理器根据#if和#ifdef等编译命令及其后的条件,将源程序中的某部分包含进来或排除在外,通常把排除在外的语句转换成空行。
(3)宏展开
预处理器将源程序文件中出现的对宏的引用展开成相应的宏 定义,即本文所说的#define的功能,由预处理器来完成。
经过预处理器处理的源程序与之前的源程序有所有不同,在这个阶段所进行的工作只是纯粹的替换与展开,没有任何计算功能,所以在学习#define命令时只要能真正理解这一点,这样才不会对此命令引起误解并误用。
六、#define使用中的常见问题解析
1. 简单宏定义使用中出现的问题
例1 #define N 2+2
void main()
{
int a=N*N;
printf(“%d”,a);
}
- /*将宏定义写成如下形式*/
- #define N (2+2)
- /*这样就可替换成(2+2)*(2+2)=16*/
2 带参数的宏定义出现的问题 (非常重要)
在带参数的宏定义的使用中,极易引起误解。例如我们需要做个宏替换能求任何数的平方,这就需要使用参数,以便在程序中用实际参数来替换宏定义中的参数。一般学生容易写成如下形式:
#define area(x) x*x
/*这在使用中是很容易出现问题的,看如下的程序*/
void main()
{
int y = area(2+2);
printf(“%d”,y);
}
按理说给的参数是2+2,所得的结果应该为4*4=16,但是错了,因为该程序的实际结果为8,仍然是没能遵循纯粹的简单替换的规则,又是先计算再替换 了。
在这道程序里,2+2即为area宏中的参数,应该由它来替换宏定义中的x,即替换成2+2*2+2=8了。那如果遵循(1)中的解决办法,把2+2 括起来,即把宏体中的x括起来,是否可以呢?#define area(x) (x)*(x),对于area(2+2),替换为(2+2)*(2+2)=16,可以解决。
但是对于area(2+2)/area(2+2)又会怎么样呢,有的学生一看到这道题马上给出结果,因为分子分母一样,又错了,还是忘了遵循先替换再计算的规则了,这道题替换后会变为 (2+2)*(2+2)/(2+2)*(2+2)即4*4/4*4按照乘除运算规则,结果为16/4*4=4*4=16,那应该怎么呢?解决方法是在整个宏体上再加一个括号,即#define area(x) ((x)*(x)),不要觉得这没必要,没有它,是不行的。
如果是自己编程使用宏替换,则在使用简单宏定义时,当字符串中不只一个符号时,加上括号表现出优先级,如果是带参数的宏定义,则要给宏体中的每个参数加上括号,并在整个宏体上再加一个括号。
七、几个实例
1. 现在定义有以下一个计算 “乘法” 的宏
#include <stdio.h>
#define MUL(a) ((a)*(a)*(a))
int main(int argc,char *argv[])
{
int i = 10;
int sum = MUL(i);
printf("MUL(%d) = %d\n",i,sum);
return 0;
}
上面程序的这种做法对于非负数而言那就是没有问题的,比如,程序中的 变量 i=10,这个时候,调用宏得到的数据如下:
MUL(10)=1000
但是如何变量的数值是自加或者自减的操作的话,结果就不一样了。
1)int sum = MUL(i++);
得到的结果并不是 11 * 11 *11 = 1331这个数据,而是 1872。
当使用了 ++i 和 i++ 的时候,要特别注意在宏中是全部使用 ++i或者i++的,变成的格式如下
MUL(i++) ((i++)*(i++)*(i++))
MUL(++i) ((++i)*(++i)*(++i))
当 i = 10的时候,MUL(i++)就是为 (i++)*(i++)*(i++)的计算结果,考虑到C/C++的运算符结合性,先计算第一个 i++,这是一个先计算后赋值的自加方式,那么这是后第一个 (i++)的数值待定为 10 ,那么第二个的i是因为第一个数据的 (i++)起了作用而变化的,这时候第二个(i++)的数值为11,然后加1,这时候 根据结合性,先计算前面两个数据,就是(i++) * (i++)的数值了,即为:10 * 11了,这时候的i数值是 12;然后计算第三个 i++的数值,这时候第三个i++中的i数值为 12,计算后再加1,也就是说,10 * 11 * 12之后,i= 12 的数值在进行i++变为 13了。所以 MUL(i++) = 10 * 11 * 12 = 1320。
2)int sum = MUL(++i);
MUL(++i) ((++i)*(++i)*(++i))
当 i = 10的时候,MUL(++i)实际上也为 (++i)*(++i)*(++i)的方式,这时候先计算第一个 (++i),这是一个先计算后赋值的结合方式,那么 i = i+1 = 11;这时候准备计算第二个(++i)的时候,因为需要先计算后赋值,所以第二个 ++i 之后的数值为12,但是因为i属于同一个变量和属性,那么第一个i也会变成 12了,这时候结合性考虑应该是计算前两个(++i)的结果,再与第三个(++i)计算,即(++i)*(++i) = 12 * 12;然后,我们计算第三个(++i)的数值,由于前面第二个++i的i值,所以第三个++i即为 13,此时,12 * 12 * 13。
注意计算顺序:先计算前两个括号内的运算,然后再计算前两个括号的相乘结果。
有人可能顾虑,为什么最后不是13 * 13 * 13的呢?那不是最后都是13吗?? ------》其实这种想法是错误的,这必须先理解运算符的结合性。我们知道,当计算中遇到了括号的时候,我们先计算括号的内容,这是我们在数学中的惯性思维。但是对于计算机而言,计算机必须 有计算的优先级,也就是运算符的优先级问题。首先我们计算前面两个括号的内容,因为两个括号之间有乘号(*),所以计算前面两个(++i)之后,必须进行乘法计算,这就是优先级中的乘法计算,自左向右计算。所以结果变为了 12 * 12的最终结果在和第三个括号的(++i)计算,就是144 * (++ i) = 144 * 13;所以MUL(++i)的结果如下:
MUL(++i)=12*12*13=1872
慎用宏在计算方面的,但是宏的有点还是很多的,对于C语言来说,宏可以减少运行的时间。在C++中,宏由于不会对类型进行检查,安全性不够,所以建议使用const来进行使用,这样可以保证类型一致。
2. 求输出结果
#include <iostream.h>
#define product(x) x*x
int main()
{
int i=3;
int j,k;
j = product(i++);
cout<<"j="<<j<<endl;
cout<<"i="<<i<<endl;
k = product(++i);
cout<<"k="<<k<<endl;
cout<<"i="<<i<<endl;
return 0;
}
八、宏定义的优点
使用简单宏定义可用宏代替一个在程序中经常使用的常量,这样在将该常量改变时,不用对整个程序进行修改,只修改宏定义的字符串即可,而且当常量比较长时, 我们可以用较短的有意义的标识符来写程序,这样更方便一些。我们所说的常量改变不是在程序运行期间改变,而是在编程期间的修改,举一个大家比较熟悉的例子,圆周率π是在数学上常用的一个值,有时我们会用3.14来表示,有时也会用3.1415926等,这要看计算所需要的精度,如果我们编制的一个程序中 要多次使用它,那么需要确定一个数值,在本次运行中不改变,但也许后来发现程序所表现的精度有变化,需要改变它的值, 这就需要修改程序中所有的相关数值,这会给我们带来一定的不便,但如果使用宏定义,使用一个标识符来代替,则在修改时只修改宏定义即可,还可以减少输入 3.1415926这样长的数值多次的情况,我们可以如此定义 #define pi 3.1415926,既减少了输入又便于修改,何乐而不为呢?
(2) 提高程序的运行效率
使用带参数的宏定义可完成函数调用的功能,又能减少系统开销,提高运行效率。正如C语言中所讲,函数的使用可以使程序更加模块化,便于组织,而且可重复利用,但在发生函数调用时,需要保留调用函数的现场,以便子 函数执行结束后能返回继续执行,同样在子函数执行完后要恢复调用函数的现场,这都需要一定的时间,如果子函数执行的操作比较多,这种转换时间开销可以忽略,但如果子函数完成的功能比较少,甚至于只完成一点操作,如一个乘法语句的操作,则这部分转换开销就相对较大了,但使用带参数的宏定义就不会出现这个问题,因为它是在预处理阶段即进行了宏展开,在执行时不需要转换,即在当地执行。宏定义可完成简单的操作,但复杂的操作还是要由函数调用来完成,而且宏定义所占用的目标代码空间相对较大。所以在使用时要依据具体情况来决定是否使用宏定义。
九、对于宏定义还要说明以下几点:
-
宏定义是用宏名来表示一个字符串,在宏展开时又以该字符串取代宏名,这只是一种简单的代换,字符串中可以含任何字符,可以是常数,也可以是表达式,预处理程序对它不作任何检查。如有错误,只能在编译已被宏展开后的源程序时发现。
-
宏定义不是说明或语句,在行末不必加分号,如加上分号则连分号也一起置换。
- 宏定义必须写在函数之外,其作用域为宏定义命令起到源程序结束。如要终止其作用域可使用# undef命令。
- 宏名在源程序中若用引号括起来,则预处理程序不对其作宏代换。
- 宏定义允许嵌套,在宏定义的字符串中可以使用已经定义的宏名。在宏展开时由预处理程序层层代换。
- 习惯上宏名用大写字母表示,以便于与变量区别。但也允许用小写字母。
- 可用宏定义表示数据类型,使书写方便。如:#define STU struct stu 在程序中可用STU作变量说明:STU body[5],*p;
- 对“输出格式”作宏定义,可以减少书写麻烦。
#define P printf
#define D "%d\n"
#define F "%f\n"
main(){
int a=5, c=8, e=11;
float b=3.8, d=9.7, f=21.08;
P(D F,a,b);
P(D F,c,d);
P(D F,e,f);
}
注意用宏定义表示数据类型和用typedef定义数据说明符的区别:
宏定义只是简单的字符串代换,是在预处理完成的,而typedef是在编译时处理的,它不是作简单的代换,而是对类型说明符重新命名。被命名的标识符具有类型定义说明的功能。
#define PIN1 int * typedef (int *) PIN2;
从形式上看这两者相似, 但在实际使用中却不相同。
下面用PIN1,PIN2说明变量时就可以看出它们的区别:
PIN1 a,b;在宏代换后变成:
int *a,b;
表示a是指向整型的指针变量,而b是整型变量。
PIN2 a,b;
表示a,b都是指向整型的指针变量。因为PIN2是一个类型说明符。
由这个例子可见,宏定义虽然也可表示数据类型, 但毕竟是作字符代换。在使用时要分外小心,以避出错。
十、对于带参的宏定义有以下问题需要说明:
1. 带参宏定义中,宏名和形参表之间不能有空格出现。
例如把: #define MAX(a,b) (a>b)?a:b 写为: #define MAX (a,b) (a>b)?a:b 将被认为是无参宏定义,宏名MAX代表字符串 (a,b) (a>b)?a:b。宏展开时,宏调用语句: max=MAX(x,y); 将变为: max=(a,b)(a>b)?a:b(x,y);
2. 在带参宏定义中,形式参数不分配内存单元,因此不必作类型定义。而宏调用中的实参有具体的值。要用它们去代换形参,因此必须作类型说明。这是与函数中的情况不同的。在函数中,形参和实参是两个不同的量,各有自己的作用域,调用时要把实参值赋予形参,进行“值传递”。而在带参宏中,只是符号代换,不存在值传递的问题。
3. 在宏定义中的形参是标识符,而宏调用中的实参可以是表达式。
#define SQ(y) (y)*(y)
main(){
int a,sq;
printf("input a number: ");
scanf("%d",&a);
sq=SQ(a+1);
printf("sq=%d\n",sq);
}
上例中第一行为宏定义,形参为y。程序第七行宏调用中实参为a+1,是一个表达式,在宏展开时,用a+1代换y,再用(y)*(y) 代换SQ,得到如下语句:sq=(a+1)*(a+1);
这与函数的调用是不同的,函数调用时要把实参表达式的值求出来再赋予形参。而宏代换中对实参表达式不作计算直接地照原样代换。
4. 在宏定义中,字符串内的形参通常要用括号括起来以避免出错。
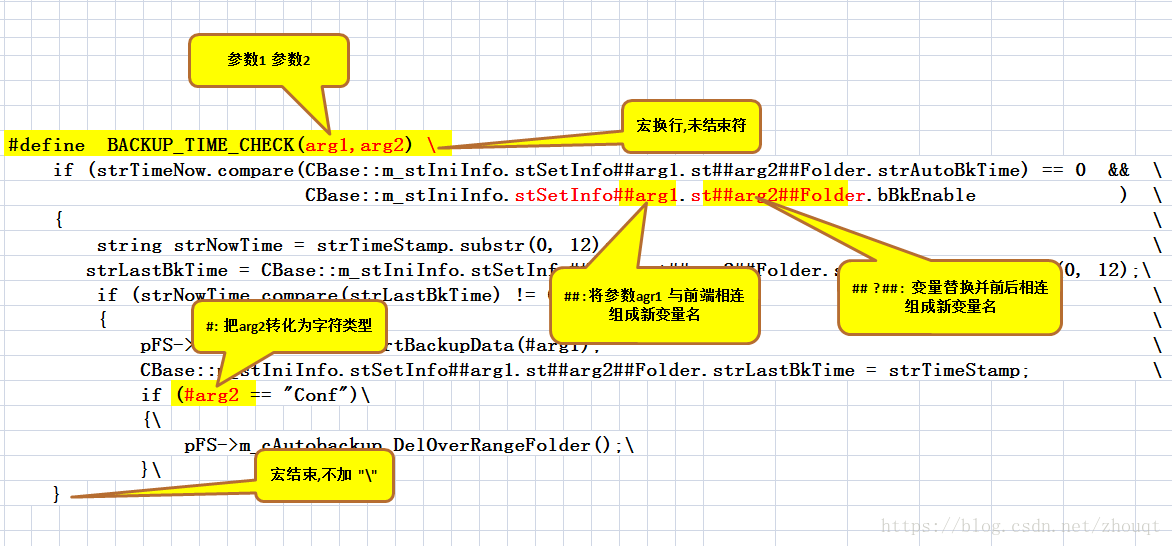
十一、define中的三个特殊符号:#,##,#@
- #define Conn(x,y) x##y
- #define ToChar(x) #@x
- #define ToString(x) #x
- int n = Conn(123,456); /* 结果就是n=123456;*/
- char* str = Conn("asdf", "adf"); /*结果就是 str = "asdfadf";*/
做个越界试验char a = ToChar(123);结果就错了;
但是如果你的参数超过四个字符,编译器就给给你报错了!
(3)#x,给x加双引号
char* str = ToString(123132);就成了str="123132";
十二、常用的一些宏定义
#ifndef BODYDEF_H #define BODYDEF_H //头文件内容 #endif
2 得到指定地址上的一个字节或字
#define MEM_B( x ) ( *( (byte *) (x) ) ) #define MEM_W( x ) ( *( (word *) (x) ) )
如
#include <iostream>
#include <windows.h>
#define MEM_B(x) (*((byte*)(x)))
#define MEM_W(x) (*((WORD*)(x)))
int main()
{
int bTest = 0x123456;
byte m = MEM_B((&bTest));/*m=0x56*/
int n = MEM_W((&bTest));/*n=0x3456*/
return 0;
}
3 得到一个field在结构体(struct)中的偏移量
#define OFFSETOF( type, field ) ( (size_t) &(( type *) 0)-> field )
请参考文章:详解写宏定义:得到一个field在结构体(struct type)中的偏移量
(type *)0:把0地址当成type类型的指针。 ((type *)0)->field:对应域的变量。 &((type *)0)->field:取该变量的地址,其实就等于该域相对于0地址的偏移量。 (size_t)&(((type *)0)->field):将该地址(偏移量)转化为size_t型数据。
ANSI C标准允许任何值为0的常量被强制转换成任何一种类型的指针,并且转换结果是一个NULL指针,因此((s*)0)的结果就是一个类型为s*的NULL指针。如果利用这个NULL指针来访问s的成员当然是非法的,但&(((s*)0)->m)的意图并非想存取s字段内容,而仅仅是计算当结构体实例的首址为((s*)0)时m字段的地址。聪明的编译器根本就不生成访问m的代码,而仅仅是根据s的内存布局和结构体实例首址在编译期计算这个(常量)地址,这样就完全避免了通过NULL指针访问内存的问题。
https://www.cnblogs.com/zhangjianlaoda/p/4356835.html
4 得到一个结构体中field所占用的字节数
#define FSIZ( type, field ) sizeof( ((type *) 0)->field )
5 得到一个变量的地址(word宽度)
#define B_PTR( var ) ( (byte *) (void *) &(var) ) #define W_PTR( var ) ( (word *) (void *) &(var) )
6 将一个字母转换为大写
#define UPCASE( c ) ( ((c) >= ''a'' && (c) <= ''z'') ? ((c) - 0x20) : (c) )
7 判断字符是不是10进值的数字
#define DECCHK( c ) ((c) >= ''0'' && (c) <= ''9'')
8 判断字符是不是16进值的数字
#define HEXCHK( c ) ( ((c) >= ''0'' && (c) <= ''9'') ||((c) >= ''A'' && (c) <= ''F'') ||((c) >= ''a'' && (c) <= ''f'') )
9 防止溢出的一个方法
#define INC_SAT( val ) (val = ((val)+1 > (val)) ? (val)+1 : (val))
10 返回数组元素的个数
#define ARR_SIZE( a ) ( sizeof( (a) ) / sizeof( (a[0]) ) )
注意:变量a要单独括起来,即使sizeof调用时有括号。
11 使用一些宏跟踪调试
ANSI标准说明了五个预定义的宏名。它们是: _LINE_ /*(两个下划线),对应%d*/ _FILE_ /*对应%s*/ _DATE_ /*对应%s*/ _TIME_ /*对应%s*/
参考链接:
https://blog.csdn.net/zhouqt/article/details/82718409
https://www.jb51.net/article/105807.htm
http://c.biancheng.net/cpp/biancheng/view/147.html
https://www.linuxidc.com/Linux/2017-02/140697.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号