推荐系统相关比赛-kaggle
from: 七月在线
电商推荐与销量预测相关案例
一、预测用户对哪个事件感兴趣(感兴趣不一定去参加)
用户历史参加事件、社交信息、浏览信息(app)、要预测的事件
recall:召回率
准确率:


协同过滤不考虑卖/买的东西是什么,只关心历史数据中哪两个用户的兴趣度一样。(1-2)
(2,3 -> 3)(视作分类模型:LR/SVM/GBDT/DNN/RF,除了预测感兴趣与不感兴趣,还想知道感兴趣的程度--概率)svm也会输出概率,但是用的不多。
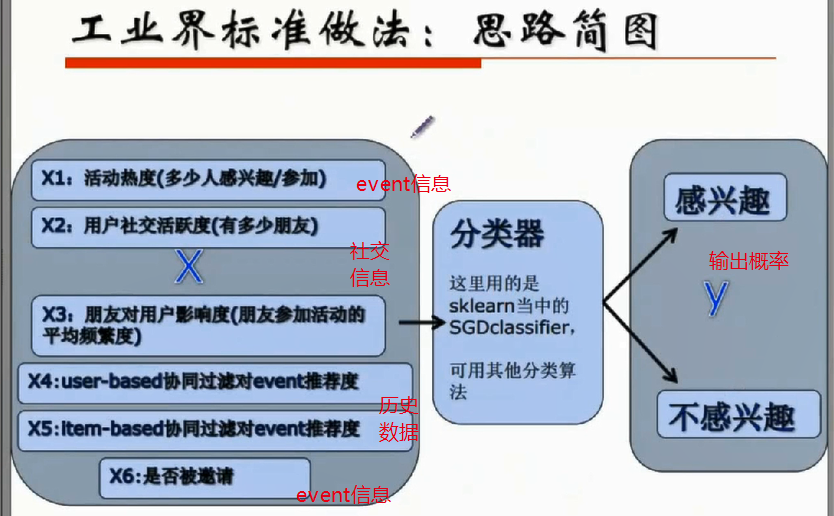
二、代码
1. import pickle (py3)内存不足的时候,可以保持原来的数据结构,Load到本地,是二进制的。Load很快,如果原来是字典,load内存后仍然是字典;如果原来是数组,load内存后仍然是数组。 (py2 import cPickle)
2. 处理关联数据:只处理有共同行为的关联信息

1)计算关联用户:
历史信息:计算cosine相似度
注册时的个人信息:计算cosine相似度
相似度可使用属性:位置、时区、注册时间(可能是小伙伴邀请注册)、国家id、性别等(在数据处理时全部转换成数值)用户维度处理信息
2)用户社交关系挖掘

朋友数量,朋友中每个朋友参加活动的频次
3)构造event和event相似度数据

4)活跃度/event热度 数据
![]()
处理上述特征的时候,归一化处理
5)组合上述数据,训练
mmwrite/mmread 处理时先存到本地,然后训练时,读取到内存。可以节省内存
协同过滤:ABCD有相似度,根据BCD的喜欢的东西,对A推荐东西,并给出推荐度。
便利店销量预测

1. 希望做的事情,提前六周知道未来的销量。但是每个国家的节日不同,销量不同。
2. 修改xgboost的loss函数(因为该竞赛的loss不是常用的loss,xgboost里没有该loss)

需要知道loss的一阶导数(grad)与二阶导数(hess)
![]()
2. 除了训练时修改了xgboost的导数,还要定义对应的loss,在训练时把loss作为参数传进去。
3. 与时间有很紧密的联系:促销、药店(流感期)
4. xgboost可以显示特征重要性
5. lightgbm比xgboost快一些
6. 交叉验证训练数据
数据与特征决定上限,模型只是逼近上限
对最终结果,数据与特征更重要一些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号