[2] day 02
1. df.memory_usage()将返回每列占用多少
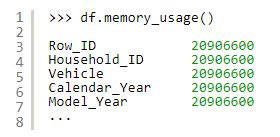
要包含索引,请传递index=True
所以要获得整体内存消耗:

2. numpy.iinfo


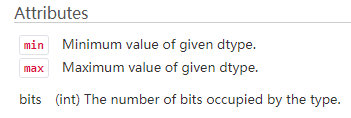
3. shift函数
https://blog.csdn.net/qq_18433441/article/details/56665931
axis=1,左右平移

4. np.where

5. expm1(x) := exp(x) - 1
6. df.isnull().values.any()
df.isnull().any() 按照每列判断,列中含有Ture则返回ture,列中全为False则返回False。即:会判断哪些”列”存在缺失值
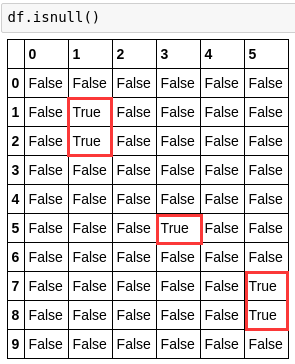


any()作用:对每列,取或操作。False|Ture=Ture
all()作用:对每列,取与操作。False|Ture=False
7. train_df[columns_to_use].values
type(train_df[columns_to_use]) 为pandas.core.frame.DataFrame
type(train_df[columns_to_use].values) 为numpy.ndarray
8. train_df[columns_to_use].values.flatten()
flatten() 返回一个折叠成 一维 的数组。但是该函数只能适用于numpy对象,即array或者mat,普通的list列表是不行的。
9. np.nonzero 返回非0值的下标

 浙公网安备 33010602011771号
浙公网安备 33010602011771号