[1] first day
一、几个工具包
【1】pandas(数据分析工具)
https://zhuanlan.zhihu.com/p/33230331
https://zhuanlan.zhihu.com/p/25013519
【2】lightbgm(梯度boosting框架,使用基于学习算法的决策树)
XGBOOST与LightGBM的区别: https://zhuanlan.zhihu.com/p/25308051 https://www.msra.cn/zh-cn/news/features/lightgbm-20170105
XGBOOST/LightGBM/CatBoost: https://www.jiqizhixin.com/articles/2018-03-18-4
二、遇到的问题
1. ['nunique'] 表示有多少个种类
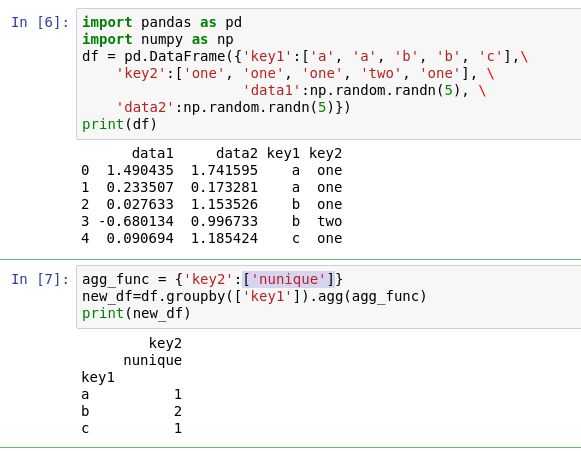
对a来说只有一个种类one,对b来说有两个种类one/two,对c来说有一个种类one。
2. ('_'.join(col))

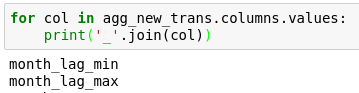
在两个字符串之间添加连接符 _
3. agg_new_trans.columns.values与agg_new_trans.columns
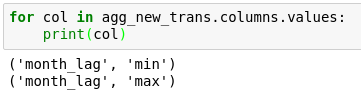

两者在for迭代取值的时候一样
4. groupby+agg(np.ptp) 群体中最大值和最小值之间的差异
结合 pd.DatetimeIndex
5. 日期相关的类型区别
df['first_active_month'] = pd.to_datetime(df['first_active_month']) #经过函数 pd.to_datetime,dtype: datetime64[ns]
df['year'] = df['first_active_month'].dt.year (或者.dt.month/.dt.days)int64类型
df['first_active_month'].dt.date #dtype: object date可以做减法,获取两个日期之间有多少days
6. pandas中.value_counts()的用法
value_counts()是一种查看表格某列中有多少个不同值的快捷方法,并计算每个不同值有在该列中有多少重复值。(返回两个结果)
value_counts()是Series拥有的方法,一般在DataFrame中使用时,需要指定对哪一列或行使用

7. LabelEncoder 将Label标准化,用来对分类型特征值进行编码,即对不连续的数值或文本进行编码。
https://blog.csdn.net/u010412858/article/details/78386407
https://blog.csdn.net/quintind/article/details/79850455
8. pd.concat: 使用pd.concat[train,test]时,当train与test有相同的列名称的时候,如feature,会自动区分两个feature,并命名为feature_1与feature_2。
9. set(df['class label']) python中set表示集合,元素只出现一次
list:链表,有序的项目, 通过索引进行查找,使用方括号”[]”;
tuple:元组,元组将多样的对象集合到一起,不能修改,通过索引进行查找, 使用括号”()”;
dict:字典,字典是一组键(key)和值(value)的组合,通过键(key)进行查找,没有顺序, 使用大括号”{}”;
set:集合,无序,元素只出现一次, 自动去重,使用”set([])”
10. pandas使用get_dummies进行one-hot编码
离散特征的编码分为两种情况:
1]、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2]、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
https://blog.csdn.net/lujiandong1/article/details/52836051
11. KFold Stratified k-fold:实现了分层交叉切分
https://blog.csdn.net/FontThrone/article/details/79220127
K折交叉验证:sklearn.model_selection.KFold(n_splits=3, shuffle=False, random_state=None)
思路:将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个作为训练集,进行n_splits次训练和测试,得到n_splits个结果 https://blog.csdn.net/kancy110/article/details/74910185
使用:
FOLDs = KFold(n_splits=5, shuffle=True, random_state=1989)
for fold_, (trn_idx, val_idx) in enumerate(FOLDs.split(train)):
其中: fold_为第几个n_splits的索引,从0开始

 浙公网安备 33010602011771号
浙公网安备 33010602011771号