生成模型与判别模型
1.生成模型与判别模型的定义
在机器学习中,模型可以分为两种:判别模型和生成模型。两者的区别在于找到决策边界的过程不同:

(1)生成模型(Generative model)
用来生成一些数据的,如,生成一个句子
训练时用一些联合概率的方式去训练
(2)判别模型(Dicriminative model)
用来做一些判别的
用条件概率去训练
(3)从数学的角度看
生成模型最大化的目标函数是P(x)或P(x, y)
判别模型是P(y|x) 条件模型
在机器学习中任务是从属性X预测标记Y,判别模型求的是P(Y|X),即后验概率;而生成模型最后求的是P(X,Y),即联合概率。从本质上来说:
判别模型之所以称为“判别”模型,是因为其根据X“判别”Y;
而生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为“生成”(X,Y)样本的概率分布(或称为 依据);具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),实际数据是如何“生成”的依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧~

2.有监督学习(supervised learning)
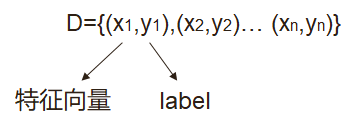
线性回归
逻辑回归
朴素贝叶斯
SVM
随机森林
Adaboost
神经网络
CNN
3.无监督学习(unsupervised learning)
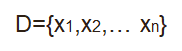
学不出X-->y的映射关系f,因为本身不存在label y
映射到低维空间(PCA,ICA降维方法)
聚类(观察哪些样本存在共性)
K-means 90%的聚类算法用K-means
PCA(principal component analysis)降维 ,如可以将一百维的特征降低到一维、二维、五维这样的
ICA(Independent Component Analysis)也是降维
MF(Matrix Factorization)矩阵分解 应用场景:推荐系统
LSA(Latent Semantic Analysis)潜在的语义分析
LDA(Latent Dirichlet Analysis)
链接:https://www.zhihu.com/question/20446337/answer/256466823

 浙公网安备 33010602011771号
浙公网安备 33010602011771号