回归树与集成学习
1.引言
如果用一句话定义xgboost,很简单:Xgboost就是由很多CART树集成。但,什么是CART树?
数据挖掘或机器学习中使用的决策树有两种主要类型:
- 分类树分析是指预测结果是数据所属的类(比如某个电影去看还是不看)
- 回归树分析是指预测结果可以被认为是实数(例如房屋的价格,或患者在医院中的逗留时间)
而术语分类回归树(CART,Classification And Regression Tree)分析是用于指代上述两种树的总称,由Breiman等人首先提出。
2.回归树
事实上,分类与回归是两个很接近的问题,分类的目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类,它的结果是离散值。而回归的结果是连续的值。当然,本质是一样的,都是特征(feature)到结果/标签(label)之间的映射。
理清了什么是分类和回归之后,理解分类树和回归树就不难了。
分类树的样本输出(即响应值)是类的形式,比如判断这个救命药是真的还是假的,周末去看电影《风语咒》还是不去。而回归树的样本输出是数值的形式,比如给某人发放房屋贷款的数额就是具体的数值,可以是0到300万元之间的任意值。
所以,对于回归树,你没法再用分类树那套信息增益、信息增益率、基尼系数来判定树的节点分裂了,你需要采取新的方式评估效果,包括预测误差(常用的有均方误差、对数误差等)。而且节点不再是类别,是数值(预测值),那么怎么确定呢?有的是节点内样本均值,有的是最优化算出来的比如Xgboost。
CART回归树是假设树为二叉树,通过不断将特征进行分裂。比如当前树结点是基于第j个特征值进行分裂的,设该特征值小于s的样本划分为左子树,大于s的样本划分为右子树。
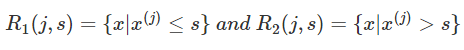
而CART回归树实质上就是在该特征维度对样本空间进行划分,而这种空间划分的优化是一种NP难问题,因此,在决策树模型中是使用启发式方法解决。典型CART回归树产生的目标函数为:
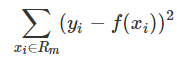
因此,当我们为了求解最优的切分特征j和最优的切分点s,就转化为求解这么一个目标函数:

所以我们只要遍历所有特征的的所有切分点,就能找到最优的切分特征和切分点。最终得到一棵回归树。
3.boosting集成学习
所谓集成学习,是指构建多个分类器(弱分类器)对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终预测结果。通俗比喻就是“三个臭皮匠赛过诸葛亮”,或一个公司董事会上的各董事投票决策,它要求每个弱分类器具备一定的“准确性”,分类器之间具备“差异性”。
集成学习根据各个弱分类器之间有无依赖关系,分为Boosting和Bagging两大流派:
- Boosting流派,各分类器之间有依赖关系,必须串行,比如Adaboost、GBDT(Gradient Boosting Decision Tree)、Xgboost
- Bagging流派,各分类器之间没有依赖关系,可各自并行,比如随机森林(Random Forest)
3.1 Adaboost
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
具体说来,整个Adaboost 迭代算法就3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
3.2 GBDT
另一种boosting方法GBDT(Gradient Boost Decision Tree),则与AdaBoost不同,GBDT每一次的计算是都为了减少上一次的残差,进而在残差减少(负梯度)的方向上建立一个新的模型。
boosting集成学习由多个相关联的决策树联合决策,什么叫相关联?举个例子
- 有一个样本[数据->标签]是:[(2,4,5)-> 4]
- 第一棵决策树用这个样本训练的预测为3.3
- 那么第二棵决策树训练时的输入,这个样本就变成了:[(2,4,5)-> 0.7]
- 也就是说,下一棵决策树输入样本会与前面决策树的训练和预测相关
很快你会意识到,Xgboost为何也是一个boosting的集成学习了。
而一个回归树形成的关键点在于:
- 分裂点依据什么来划分(如前面说的均方误差最小,loss);
- 分类后的节点预测值是多少(如前面说,有一种是将叶子节点下各样本实际值的均值作为叶子节点预测误差,或者计算所得)
至于另一类集成学习方法,比如Random Forest(随机森林)算法,各个决策树是独立的、每个决策树在样本堆里随机选一批样本,随机选一批特征进行独立训练,各个决策树之间没有啥关系。
参考文章:https://blog.csdn.net/v_JULY_v/article/details/81410574

 浙公网安备 33010602011771号
浙公网安备 33010602011771号