循环核&循环层
1.卷积神经网络与循环神经网络简单对比
CNN: 借助卷积核(kernel)提取特征后,送入后续网络(如全连接网络 Dense)进行分类、目标检测等操作。 CNN 借助卷积核从空间维度提取信息,卷积核参数空间共享。
RNN: 借助循环核(cell)提取特征后, 送入后续网络(如全连接网络 Dense)进行预测等操作。 RNN 借助循环核从时间维度提取信息,循环核参数时间共享。
什么是卷积核参数空间共享?
给一张输入图片,用一个filter去扫这张图,filter里面的数就叫权重,这张图每个位置是被同样的filter扫的,所以权重是一样的,也就是共享。
2.循环核
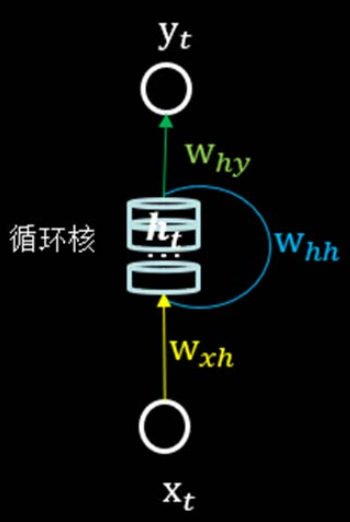
循环核具有记忆力,通过不同时刻的参数共享,实现了对时间序列的信息提取。每个循环核有多个记忆体,对应图中的多个小圆柱。记忆体内存储着每个时刻的状态信息ht,这里ht=tanh(xtwxh+ht-1whh+bh)。其中,wxh、whh为权重矩阵,bh为偏置,xt为当前时刻的输入特征,ht-1为记忆体上一时刻存储的状态信息,tanh为激活函数。
当前时刻循环核的输出特征yt=softmax(htwhy+by),其中why为权重矩阵,by为偏置,softmax为激活函数,其实就相当于一层全连接层。我们可以设定记忆体的个数从而改变记忆容量,当记忆体的个数被指定,输入xt输出yt维度被指定,周围这些带训练参数的维度也就被限定了。
在前向传播时,记忆体内存储的状态信息ht在每个时刻都被刷新,而三个参数矩阵wxh、whh、why和两个偏置项bh和by自始至终都是固定不变的。
反向传播时,三个参数和偏置项有梯度下降法更新。
3.循环核按时间步展开
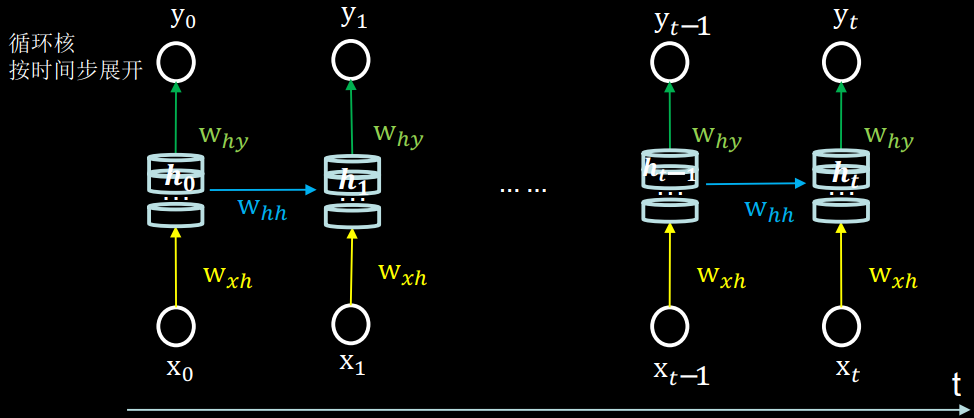
将循环核按时间步展开, 就是把循环核按照时间轴方向展开,可以得到如图的形式。 每个时刻记忆体状态信息h𝑡被刷新,记忆体周围的参数矩阵和两个偏置项是固定不变的,我们训练优化的就是这些参数矩阵。
训练完成后,使用效果最好的参数矩阵执行前向传播, 然后输出预测结果。
其实这和我们人类的预测是一致的:我们脑中的记忆体每个时刻都根据当前的输入而更新; 当前的预测推理是根据我们以往的知识积累用固化下来的“参数矩阵”进行的推理判断。
可以看出, 循环神经网络就是借助循环核实现时间特征提取后把提取到的信息送入全连接网络, 从而实现连续数据的预测。
4.循环层(向输出方向生长)
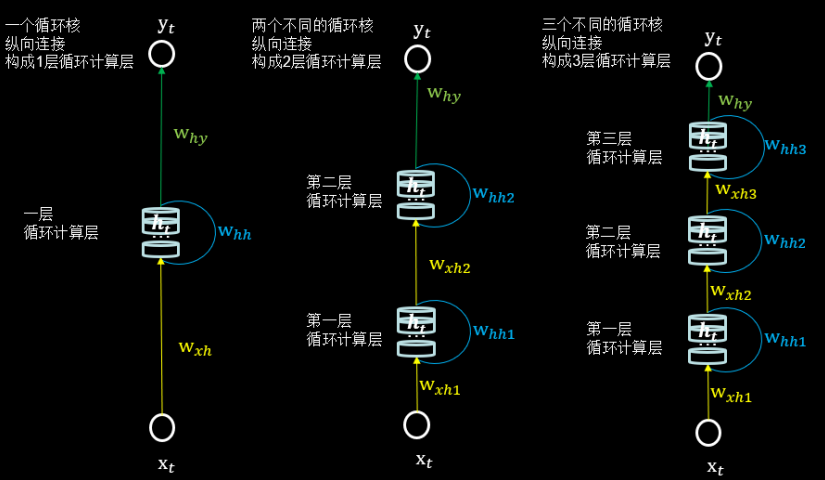
在 RNN 中, 每个循环核构成一层循环计算层, 循环计算层的层数是向输出方向增长的。
如下图所示,左图的网络有一个循环核,构成了一层循环计算层;中图的网络有两个循环核,构成了两层循环计算层;右图的网络有三个循环核,构成了三层循环计算层。其中,三个网络中每个循环核中记忆体的个数可以根据我们的需求任意指定。
5.RNN训练
6.TensorFlow2描述循环计算层


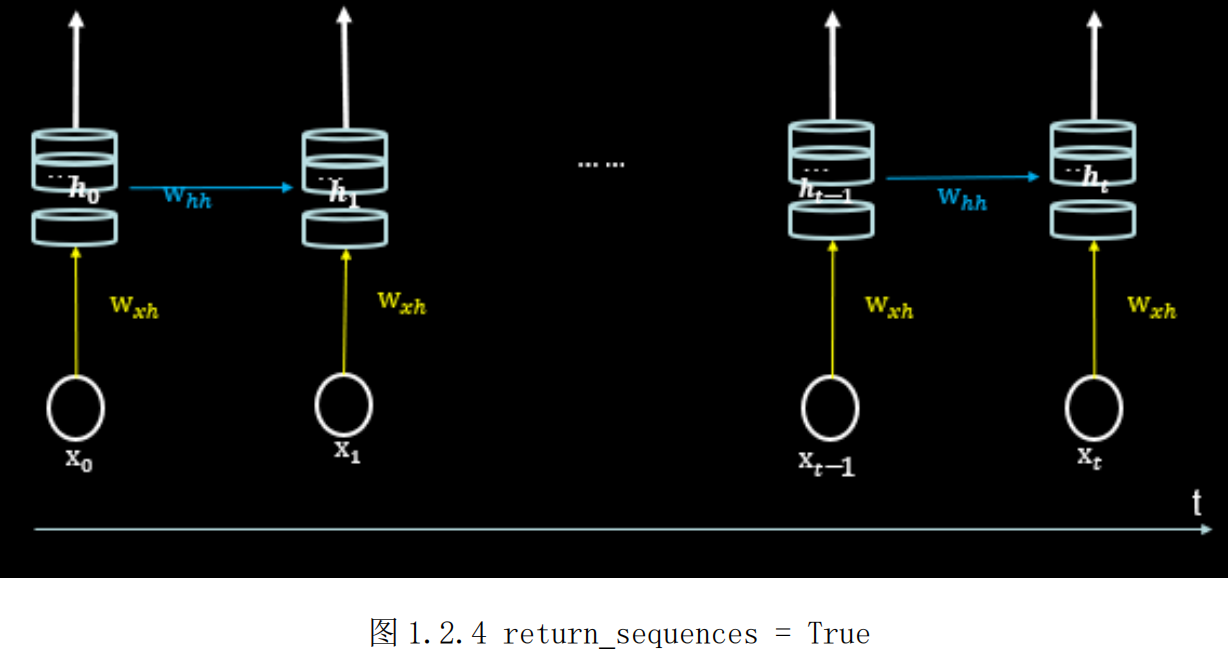
return_sequences=True,循环核仅在最后时刻把ht推送到下一层
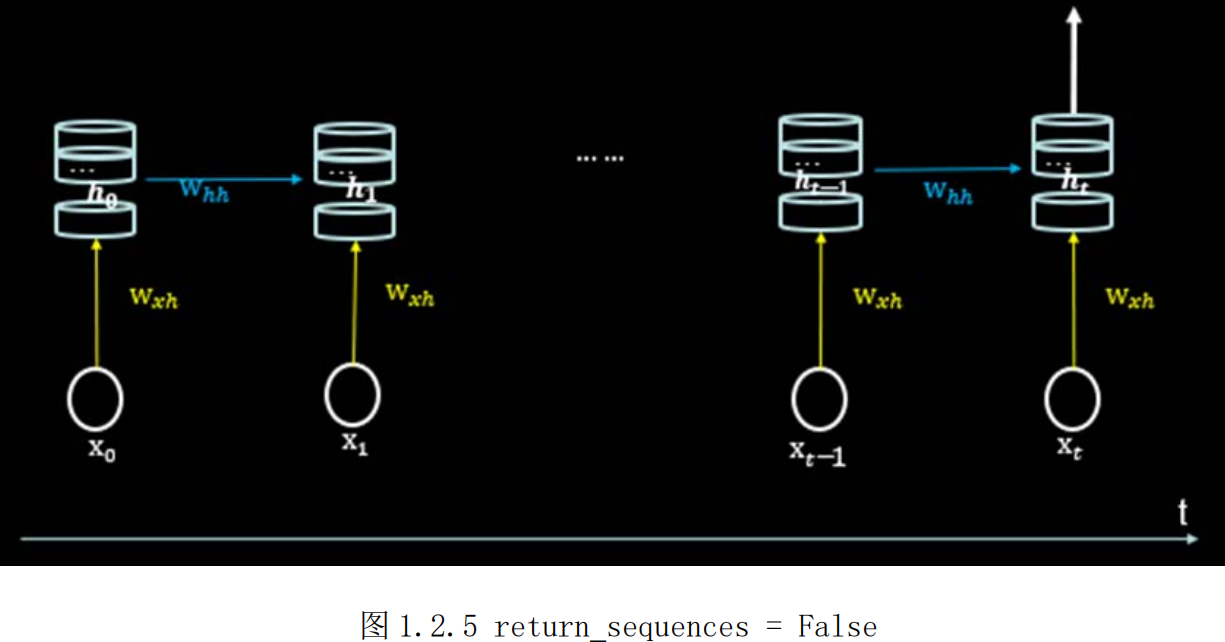
输入维度(入RNN,x_train维度)
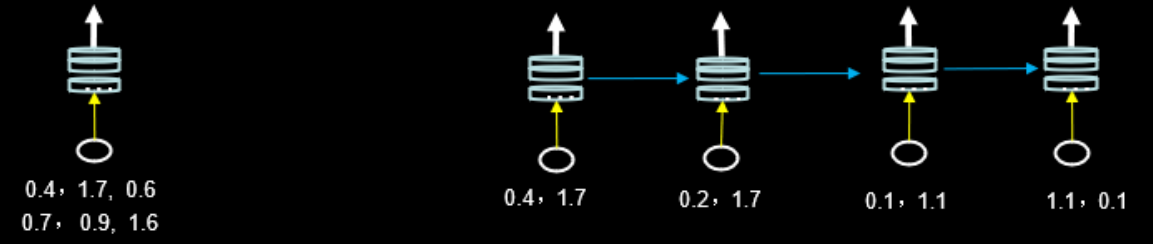
7.RNN-Semantic Meaning
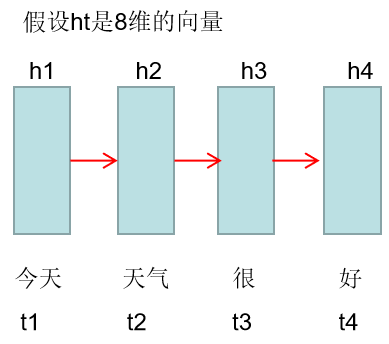
h1代表今天这个单词的含义(semantic meaning)
h2代表今天 天气这两个单词含义,即这两个单词的含义包含在h2向量里面
h3代表今天 天气 很三个单词的含义
h4代表今天 天气 很 好这句话的含义,即这句话的意思包含着了h4这个向量里面了
这就是RNN应用在文本领域时候,每个时间节点上隐含层的表达方式
8.RNN-Exploding/Vanishing Gradient
RNN是一个很难训练的模型, 原因是存在梯度爆炸、梯度消失的现象
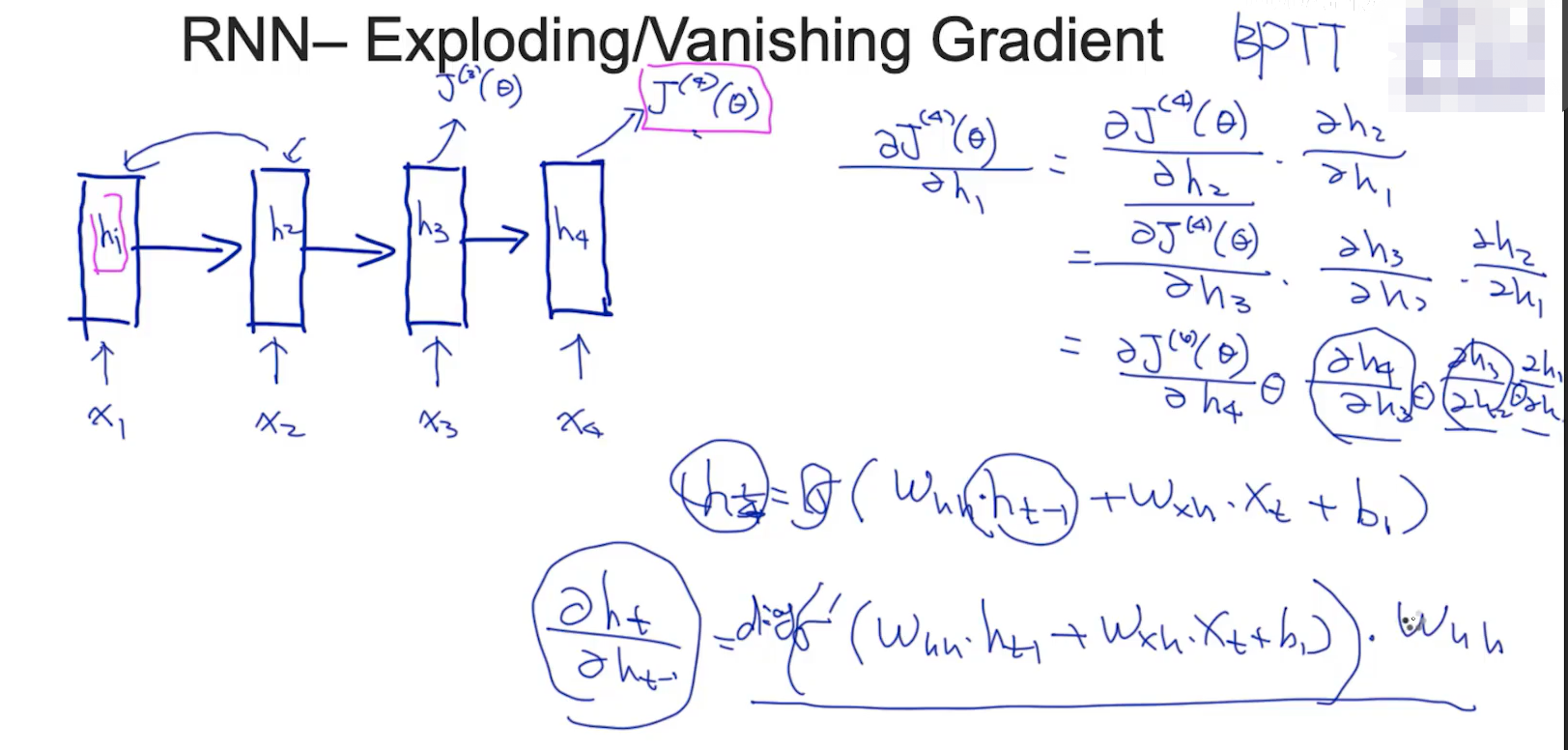
当那些偏导数在0-1之间,则会梯度消失;大于1则会梯度爆炸
这样就需要LSTM模型,LSTM的cell可以部分避免梯度消失和梯度下降

 浙公网安备 33010602011771号
浙公网安备 33010602011771号