
python OrderedDict类&LRU缓存机制练习题
1.collections.OrderedDict类中的方法概述
import collections
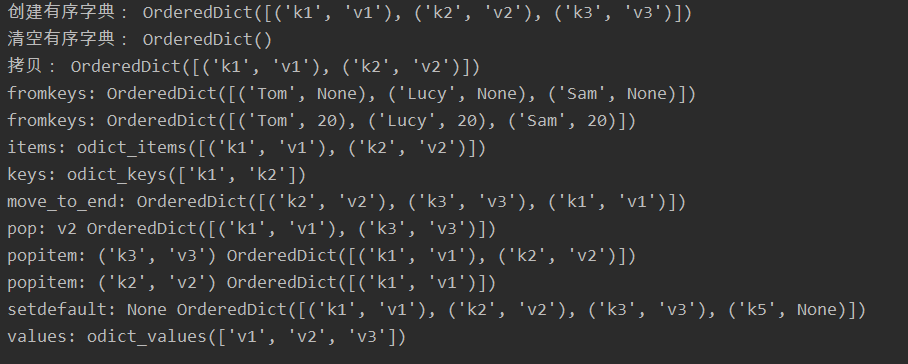
# 创建有序字典
dic = collections.OrderedDict()
dic['k1'] = 'v1'
dic['k2'] = 'v2'
dic['k3'] = 'v3'
print('创建有序字典:', dic)
# 清空有序字典 clear
dic1 = collections.OrderedDict()
dic1['k1'] = 'v1'
dic1['k2'] = 'v2'
dic1.clear()
print('清空有序字典:', dic1)
# copy - 拷贝
dic3 = collections.OrderedDict()
dic3['k1'] = 'v1'
dic3['k2'] = 'v2'
new_dic = dic3.copy()
print('拷贝:', new_dic)
# fromkeys(指定一个列表,把列表中的值作为字典的key,生成一个字典)
dic4 = collections.OrderedDict()
name = ['Tom', 'Lucy', 'Sam']
print('fromkeys:', dic4.fromkeys(name))
print('fromkeys:', dic4.fromkeys(name, 20))
# items(返回由'键值对组成元素'的列表)
dic5 = collections.OrderedDict()
dic5['k1'] = 'v1'
dic5['k2'] = 'v2'
print('items:', dic5.items())
# keys(获取字典所有的key)
dic6 = collections.OrderedDict()
dic6['k1'] = 'v1'
dic6['k2'] = 'v2'
print('keys:', dic6.keys())
# move_to_end(指定一个key,把对应的key-value移到最后)
dic7 = collections.OrderedDict()
dic7['k1'] = 'v1'
dic7['k2'] = 'v2'
dic7['k3'] = 'v3'
dic7.move_to_end('k1')
print('move_to_end:', dic7)
# pop(获取指定key的value,并在字典中删除)
dic8 = collections.OrderedDict()
dic8['k1'] = 'v1'
dic8['k2'] = 'v2'
dic8['k3'] = 'v3'
k = dic8.pop('k2')
print('pop:', k, dic8)
# popitem(按照后进先出的原则, 删除最后加入的元素,返回key-value)
dic9 = collections.OrderedDict()
dic9['k1'] = 'v1'
dic9['k2'] = 'v2'
dic9['k3'] = 'v3'
print('popitem:', dic9.popitem(), dic9)
print('popitem:', dic9.popitem(), dic9)
# setdefault(获取指定key的value, 如果key不存在, 则创建)
dic10 = collections.OrderedDict()
dic10['k1'] = 'v1'
dic10['k2'] = 'v2'
dic10['k3'] = 'v3'
val = dic10.setdefault('k5')
print('setdefault:', val, dic10)
# values(获取字典所有的value, 返回一个列表)
dic11 = collections.OrderedDict()
dic11['k1'] = 'v1'
dic11['k2'] = 'v2'
dic11['k3'] = 'v3'
print('values:', dic11.values())
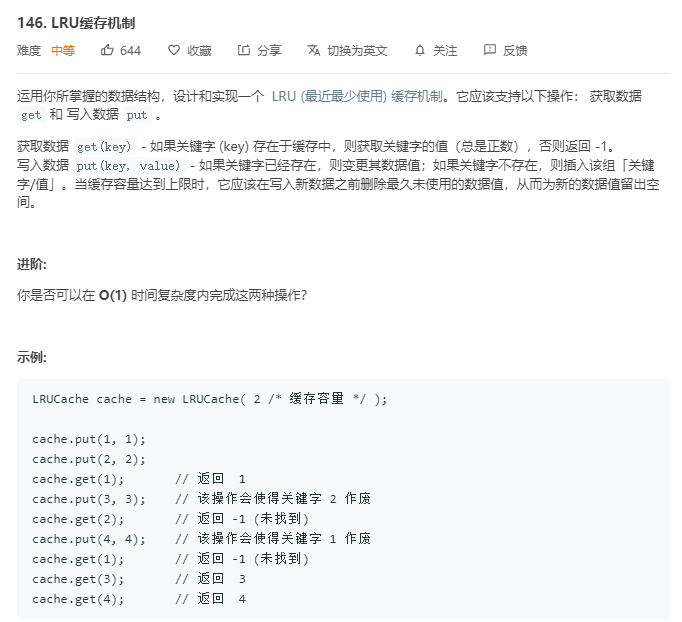
2.力扣146题LRU缓存机制
方法一:哈希表 + 双向链表
算法
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1)O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 -1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
class DLinkedNode:
def __init__(self, key=0, value=0):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
# cache是哈希表,键为缓存数据的键,值为在双向链表中的位置
self.cache = dict()
# 使用伪头部和伪尾部节点
self.head = DLinkedNode()
self.tail = DLinkedNode()
self.head.next = self.tail
self.tail.prev = self.head
self.capacity = capacity
self.size = 0
def get(self, key: int) -> int:
if key not in self.cache:
return -1
# 如果key存在,先通过哈希表定位,再移到头部
node = self.cache[key]
self.moveToHead(node)
return node.value
def put(self, key: int, value: int) -> None:
if key not in self.cache:
# 如果key不存在,创建一个新的节点
node = DLinkedNode(key, value)
# 添加进哈希表
self.cache[key] = node
# 添加至双向链表的头部
self.addToHead(node)
self.size += 1
if self.size > self.capacity:
# 如果超出容量,删除双向链表的尾部节点
removed = self.removeTail()
# 删除哈希表中对应的项
self.cache.pop(removed.key)
self.size -= 1
else:
# 如果key存在,先通过哈希定位,再修改value,并移到头部
node = self.cache[key]
node.value = value
self.moveToHead(node)
def addToHead(self, node):
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def removeNode(self, node):
node.prev.next = node.next
node.next.prev = node.prev
def moveToHead(self, node):
self.removeNode(node)
self.addToHead(node)
def removeTail(self):
node = self.tail.prev
self.removeNode(node)
return node
方法二,使用collections.OrderedDict()类
class LRUCache(collections.OrderedDict):
def __init__(self, capacity: int):
super().__init__()
self.capacity = capacity
def get(self, key: int) -> int:
if key not in self:
return -1
self.move_to_end(key)
return self[key]
def put(self, key: int, value: int) -> None:
if key in self:
self.move_to_end(key)
self[key] = value
if len(self) > self.capacity:
# popitem如果last=True则最后加入的最先出来,如果last=False则最先加入的最先出来
self.popitem(last=False)
