
数据结构之跳表
定义
跳表,,是一个随机化的数据结构,实质是一种支持类似“二分查找"进行改造的有序链表;使用二分查询时,底层依赖的是数组的随机访问特性,但是链表也可以实现类似的算法,在原有的有序链表上增加了多级索引,通过索引来实现快速查询。这就是跳表。
使用场景
- Redis 中的有序集合(Sorted Set)
- 集群节点内部数据结构
详解
对于一个单链表来说,即使链表也是有序的,我们想在这个链表中查找某个数据,也只能从头到尾进行遍历,时间复杂度是O(n)。如果像书的目录一样,在加一层索引呢?这里的第一级索引的down指针指向的原始链表对应的结点。
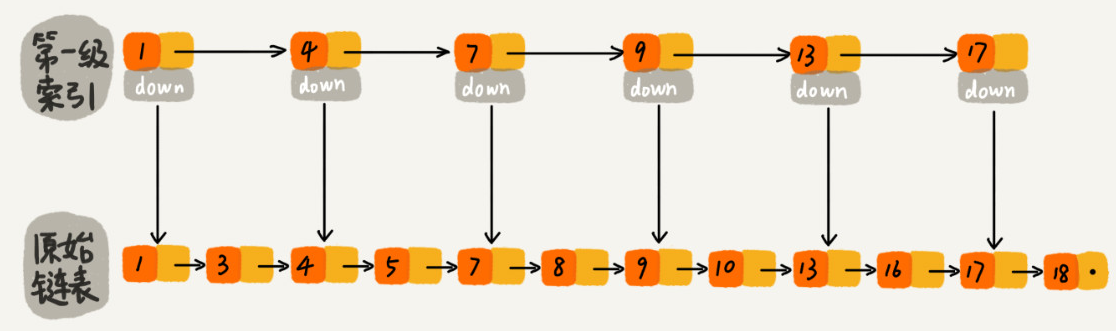
那么这样我们查找数据的时候,可以像书籍一样,先查找目录缩小范围后再查找了,减少了需要遍历的结点,提高了查找效率;
栗子:在64个结点的有序链表中,找到62这个数据;如果在没加索引的有序链表中,我们需要一步步遍历,遍历到第62个,但是如果我们加了多级索引,如图,我们只需要遍历11个结点。
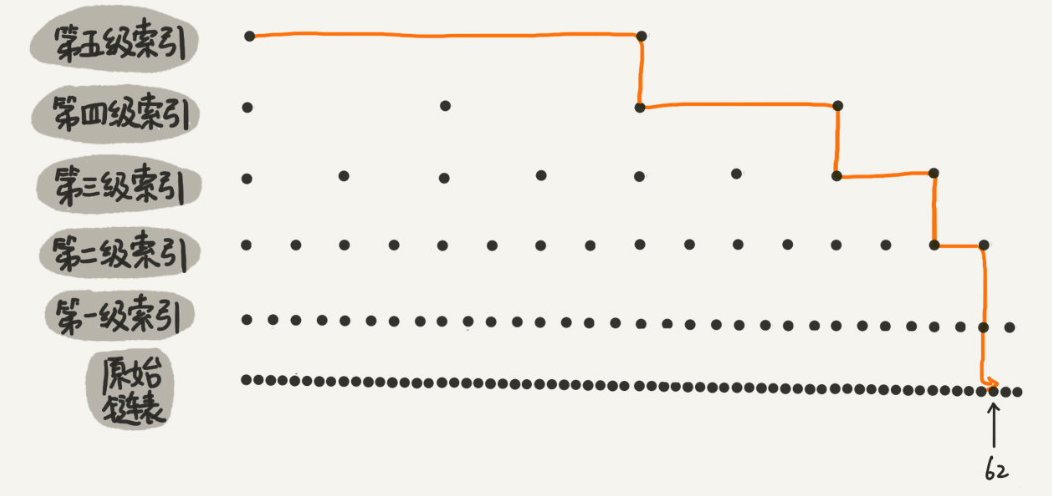
所以,当链表的长度 n 比较大时,比如 1000、10000 的时候,在构建索引之后,查找效率的提升就会非常明显。
复杂度
时间复杂度
如果链表里有n个结点,每两个结点都会抽出一个结点作为上一级索引的结点。那么第一级索引的个数大约就是n/2,第二级的索引大约就是n/4,第三级的索引就是n/8,依次类推,也就是说,第k级索引的结点个数是第k-1级索引的结点个数的1/2,那么第k级的索引结点个数为:。
假设索引有h级,最高级的索引有2个结点,通过上面的公式,我们可以得到,从而可得:h =
。如果包含原始链表这一层,整个跳表的高度就是
。我们在跳表中查找某个数据的时候,如果每一层都要遍历m个结点,那么在跳表中查询一个数据的时间复杂度就为:O(m*logn)。
基于上面的假设,我们是每两个结点都会抽出一个结点作为上一级索引的结点,所以每一级的索引都最多只需要遍历3个结点,也就是m<=3。假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
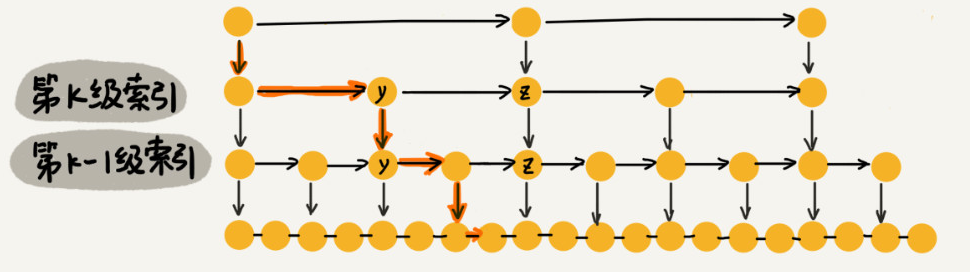
所以,去掉系数,在跳表中查询任意数据的时间复杂度就是 O(logn)
空间复杂度
这里的思路是空间换思路,维护这么多层索引,需要额外的存储空间。然后基于上面的的假设,我们是每两个结点都会抽出一个结点作为上一级索引的结点,如果我们原始链表的大小为n,那么第一级索引的个数大约就是n/2,第二级的索引大约就是n/4,第三级的索引就是n/8,依次类推,知道最后剩下2个节点。这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。
如果想进一步节省存储空间,可以将索引的结点抽取增加,上面都是每两个结点都会抽出一个结点作为上一级索引的结点,将每三个或每五个结点抽取一层,所需的存储空间又降低了
实现和操作
删除和插入
在无序的单链表中,插入和删除操作都是O(1),但如果在有序的单链表中,插入和删除操作比较耗时,因为你需要查找定位插入和删除的结点在哪里,所以时间复杂度是O(1)。这个时间耗费都出现在查找结点上。那么对于跳表来说,它的插入和删除操作,和它查找的时间一直都是O(logn)。
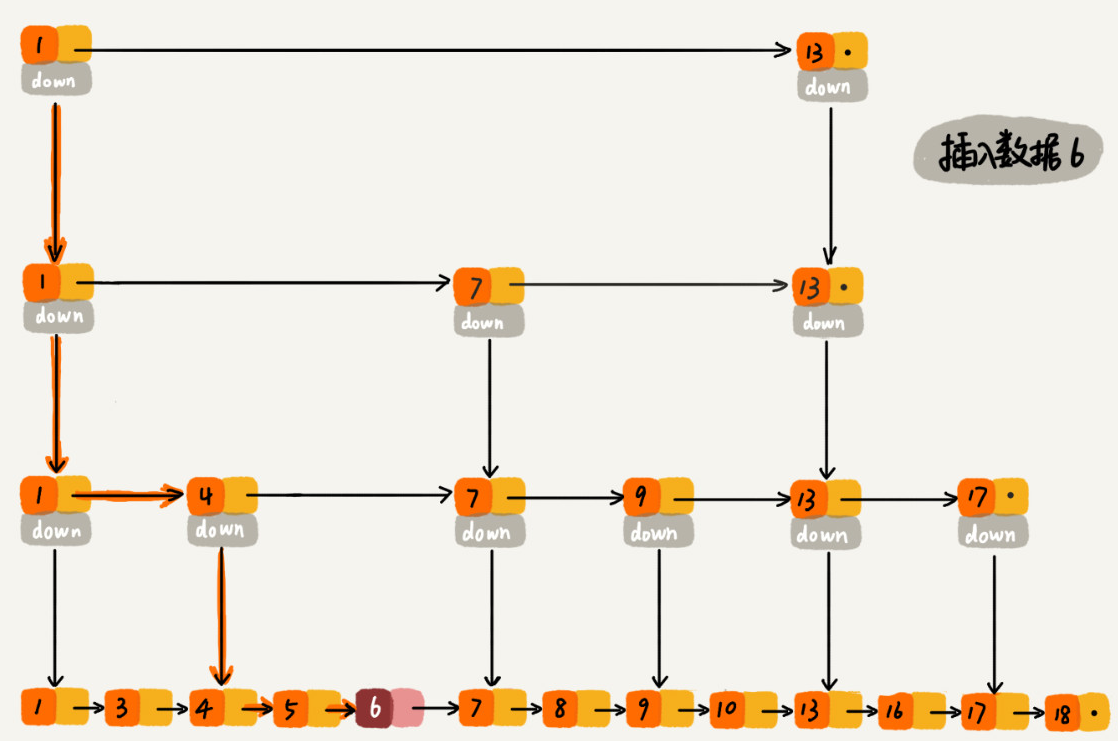
跳表的动态更新
当我们数据不断更新的时候,索引也需要对应的进行维护更新,如果维护更新,跳表会逐渐退化成单链表。跳表通过随机函数来维护”平衡性“。通过一个随机函数,来决定将这个结点插入到哪几级索引中,比如随机函数生成了值 K,那我们就将这个结点添加到第一级到第 K 级这 K 级索引中。随机函数的选择很有讲究,从概率上来讲,能够保证跳表的索引大小和数据大小平衡性,不至于性能过度退化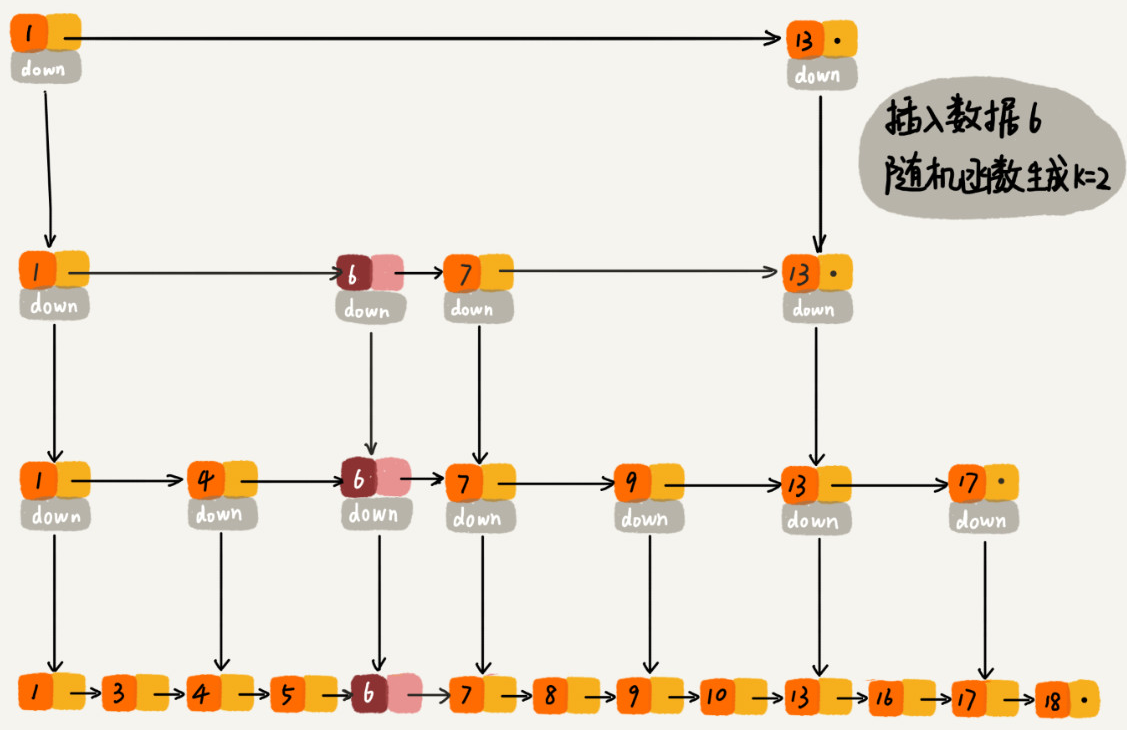
我们也可以让新插入的节点随机“晋升”,新节点晋升的成功的几率是50%,每层索引晋升级率一致,直到晋升到最顶层或在顶层新增一层。删除操作的时候,把对应的节点以及对应的索引进行删除,如果索引所在一层只有那一个索引,那么直接把整层删除。
在java程序中,实现又是有区别的:
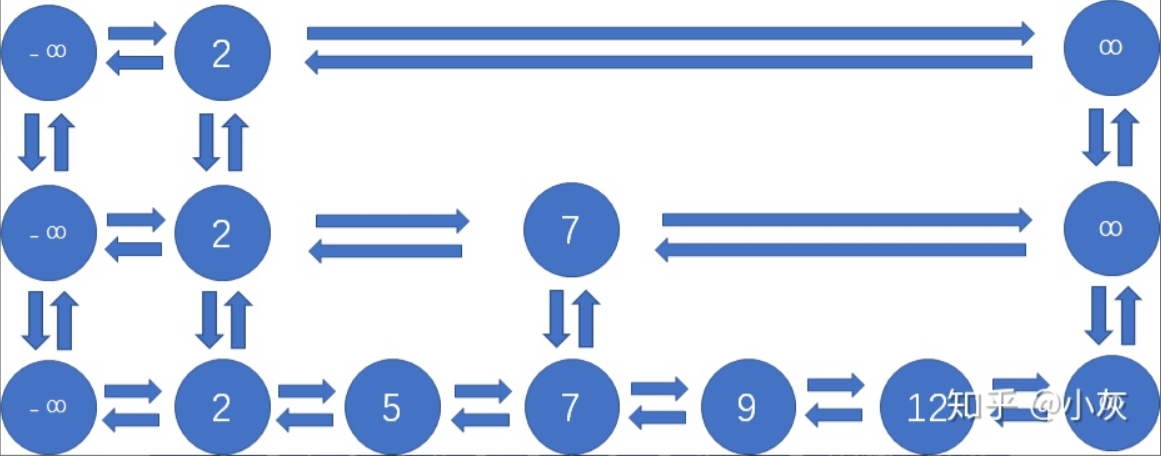
- 程序中跳表采用的是双向链表,无论前后结点还是上下结点,都各有两个指针相互指向彼此。
- 程序中跳表的每一层首位各有一个空结点,左侧的空节点是负无穷大,右侧的空节点是正无穷大。
程序清单


public class SkipList{ //结点“晋升”的概率 private static final double PROMOTE_RATE = 0.5; private Node head,tail; private int maxLevel; public SkipList() { head = new Node(Integer.MIN_VALUE); tail = new Node(Integer.MAX_VALUE); head.right = tail; tail.left = head; } //查找结点 public Node search(int data){ Node p= findNode(data); if(p.data == data){ System.out.println("找到结点:" + data); return p; } System.out.println("未找到结点:" + data); return null; } //找到值对应的前置结点 private Node findNode(int data){ Node node = head; while(true){ while (node.right.data!=Integer.MAX_VALUE && node.right.data<=data) { node = node.right; } if (node.down == null) { break; } node = node.down; } return node; } //插入结点 public void insert(int data){ Node preNode= findNode(data); //如果data相同,直接返回 if (preNode.data == data) { return; } Node node=new Node(data); appendNode(preNode, node); int currentLevel=0; //随机决定结点是否“晋升” Random random = new Random(); while (random.nextDouble() < PROMOTE_RATE) { //如果当前层已经是最高层,需要增加一层 if (currentLevel == maxLevel) { addLevel(); } //找到上一层的前置节点 while (preNode.up==null) { preNode=preNode.left; } preNode=preNode.up; //把“晋升”的新结点插入到上一层 Node upperNode = new Node(data); appendNode(preNode, upperNode); upperNode.down = node; node.up = upperNode; node = upperNode; currentLevel++; } } //在前置结点后面添加新结点 private void appendNode(Node preNode, Node newNode){ newNode.left=preNode; newNode.right=preNode.right; preNode.right.left=newNode; preNode.right=newNode; } //增加一层 private void addLevel(){ maxLevel++; Node p1=new Node(Integer.MIN_VALUE); Node p2=new Node(Integer.MAX_VALUE); p1.right=p2; p2.left=p1; p1.down=head; head.up=p1; p2.down=tail; tail.up=p2; head=p1; tail=p2; } //删除结点 public boolean remove(int data){ Node removedNode = search(data); if(removedNode == null){ return false; } int currentLevel=0; while (removedNode != null){ removedNode.right.left = removedNode.left; removedNode.left.right = removedNode.right; //如果不是最底层,且只有无穷小和无穷大结点,删除该层 if(currentLevel != 0 && removedNode.left.data == Integer.MIN_VALUE && removedNode.right.data == Integer.MAX_VALUE){ removeLevel(removedNode.left); }else { currentLevel ++; } removedNode = removedNode.up; } return true; } //删除一层 private void removeLevel(Node leftNode){ Node rightNode = leftNode.right; //如果删除层是最高层 if(leftNode.up == null){ leftNode.down.up = null; rightNode.down.up = null; }else { leftNode.up.down = leftNode.down; leftNode.down.up = leftNode.up; rightNode.up.down = rightNode.down; rightNode.down.up = rightNode.up; } maxLevel --; } //输出底层链表 public void printList() { Node node=head; while (node.down != null) { node = node.down; } while (node.right.data != Integer.MAX_VALUE) { System.out.print(node.right.data + " "); node = node.right; } System.out.println(); } //链表结点类 public class Node { public int data; //跳表结点的前后和上下都有指针 public Node up, down, left, right; public Node(int data) { this.data = data; } } public static void main(String[] args) { SkipList list=new SkipList(); list.insert(50); list.insert(15); list.insert(13); list.insert(20); list.insert(100); list.insert(75); list.insert(99); list.insert(76); list.insert(83); list.insert(65); list.printList(); list.search(50); list.remove(50); list.search(50); } }
那 Redis 为什么会选择用跳表来实现有序集合呢? 为什么不用红黑树呢?
Redis 中的有序集合支持的核心操作主要有下面这几个:
- 插入一个数据;
- 删除一个数据;
- 查找一个数据;
- 按照区间查找数据(比如查找值在[100, 356]之间的数据);
- 迭代输出有序序列。
其中,插入、删除、查找以及迭代输出有序序列这几个操作,红黑树也可以完成,时间复杂度跟跳表是一样的。但是,按照区间来查找数据这个操作,红黑树的效率没有跳表高。对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。这样做非常高效。
Redis 之所以用跳表来实现有序集合,还有其他原因,比如,跳表更容易代码实现。虽然跳表的实现也不简单,但比起红黑树来说还是好懂、好写多了,而简单就意味着可读性好,不容易出错。还有,跳表更加灵活,它可以通过改变索引构建策略,有效平衡执行效率和内存消耗。不过,跳表也不能完全替代红黑树。因为红黑树比跳表的出现要早一些,很多编程语言中的 Map 类型都是通过红黑树来实现的。我们做业务开发的时候,直接拿来用就可以了,不用费劲自己去实现一个红黑树,但是跳表并没有一个现成的实现,所以在开发中,如果你想使用跳表,必须要自己实现。
参考:极客时间的《数据结构与算法之美》 程序员小灰《漫画:什么是 “跳表” ?》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号