
通过HtmlCleaner与xpath解析html内容时出现的问题
使用 HtmlCleaner 和xpath结合起来解析html内容时,按理来说,只要给TagNode的 evaluateXPath方法传入要解析的元素的xpath(xpath的获取直接在控制台右键复制即可),就可以得到一个Object数组。
但是,我获得的数组长度为0。
我自己做的时候遇到结果为0的情况有以下的两种
1. 查看HTML对应元素的xpath时,并没有留意到该元素其实是通过js或者xhr的方法后续加载的,也即是传说中的异步加载?
2. 其次,不同的浏览器获取到的xpath是不同的,如下有个对比
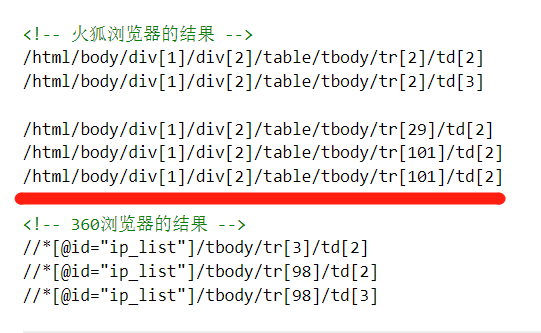
给evaluateXPath方法传入火狐浏览器获取到的xpath时并没有得到预期的结果,360浏览器获取到的xpath可以获取正确结果
后面这一点的原因还有待深究,如果你知道原因,麻烦在评论下留下您的见解,谢谢~

