

Day5 字符串(一)
简单字符串
T1 Codeforces 955D Scissors
给出一个字符串S(长度n),你有一把剪刀可以把字符串剪成两个不重复的长度为K的字符串,然后把两个拼起来
现在要你给出一种剪法使得拼接之后的字符串包含另一个新的字符串T(长度m)
字符串长度<=5*10^5
哈希。用哈希匹配字符串。
首先判断S串里有没有T串,只需双指针维护长度为m的S中的区间,顺序扫一遍维护hash值对比T的hash值即可。找到的话直接输出。
然后考虑S不包含T子串也即T被切开的情况也是要指针搞?
其实我一开始想的是正反两个KMP搞。
T2 ICPC2019 Shanghai Online G 字符串集合匹配
给了一个母串S, 每次循环给了一个模板串,问模板串在母串中“匹配”了多少次?“匹配”的意思就是首字母和尾字母一样, 中间字母顺序可以换。询问次数 20000保证询问的字符串总长度不超过 100000。S 长度不超过 100000
字符串不考虑顺序的话只需要考虑每个字符出现的次数,根据出现的次数计算哈希值。本题只需维护首尾两个指针,计算区间内的哈希值,然后与模式串的hash值匹配,如果hash值匹配并且首尾字符匹配的话,匹配次数加一。指针移动时修改hash值是O(1)的。单次复杂度即为O(|S|)。这个题离线做,所有长度相同的模式串一起跑双指针。这样复杂度就和模式串的长度种类有关。分析一下总长度为100000,最多只有\(\sqrt{100000}\)种长度。
T3 Codeforces 985F Isomorphic Strings 字符串同构
给定一个字符串
200000 次询问
每次询问两个子串是不是同构。
同构:要求对S中某一特定字母,总能找到在T中的某一字母与其字母出现个数相同,且每个出现字母对应的位置相同
例如 aaabb 和 cccdd 同构
对于每一个字符构造长度为n的01串,出现的位置置为1,其余为0。处理出26个01串然后排序。若两个字符串对应的排序之后的26个01串完全一样,则这两个字符串同构。复杂度O(qnlogn)。其中q是询问次数,n是字符串长度,nlogn是排序复杂度。
T4 BJOI Matrix(二维Hash)
给定一个M行N列的01矩阵,以及Q个A行B列的01矩阵,你需要求出这Q个矩阵哪些在原矩阵中出现过。
所谓01矩阵,就是矩阵中所有元素不是0就是1。
二维hash:
struct Hash2D{
ll px=131, py=233, mod=998244353;
ll pwx[maxn], pwy[maxn];
int a[maxn][maxn];
void init_xp(){
pwx[0]=pwy[0]=1;
for(int i=1;i<=N;++i){
pwx[i]=pwx[i-1]*px%mod;
pwy[i]=pwy[i-1]*py%mod;
}
}
void hash(int n, int m){
for(int i=1;i<=n+1;++i){
ll s=0;
for(int j=1;j<=m+1){
s=(s*py+a[i][j])%mod;
hv[i][j]=(hv[i-1][j]*px+s)%mod;
}
}
}
ll h(int x, int y, int dx, int dy){
--x; --y;
ll res=hv[x+dx][y+dy]+hv[x][y]*pwx[dx]%mod*pwy[dy]-hv[x][y+dy]*pwx[dx]-hv[x+dx][y]*pwy[dy];
return (res%mod+mod)%mod;
}
}
T5 LA3942 Remember the Word 字符串拆分
给定一字符串,以及一个字典(字符串的set)问将字符串拆成字典中的单词(不能相交)有多少种拆法字符串长度不超过 300000。字典单词不超过 4000个,每个单词长度不超过 100。
trie树上DP。f[x]表示到字符串的第i为有几种拆分方案。\(dp[x+1]+=dp[x]*overnum[s[x+1]]\)字符串的前x位的方案数为dp[x]。??
T6 Leetcoder421 Maximum XOR of Two Numbers in an Array
给出 n 个数,找到一对数,他们的 xor 是最大的。
个数 <=10^5。
数 <2^32。
01trie最大异或模板。O(n)把所有的数字都放进trie里面。O(nlena)挨个跑最大异或。的最大值。
T7 Dictionary Size 前后缀单词
给出完整的字典单词列表
新词的构词规则:认可的词必须是字典词或由两部分组成,其中第一部分必须是字典词或其非空前缀,第二部分是字典词或其非空后缀。
求有多少本质不同的单词。
字典单词<=10000。
单词长度<=40。
建立前缀树和后缀树(bushi)。为了防止重复,用尽可能长的前缀和后缀拼接。对于特殊情况:某一个单词的前缀的后缀也在字典当中,如{"abcd","c"}可以生成新单词"ab"+"c"="abc",但是我们会找极长的前缀"abc",就会发现后缀为空,这个单词就会被漏下,所以这种情况要特殊处理。
有关AC自动机
KMP可视为降维的AC自动机。
fail边的作用是,当当前字符x失配时,尝试去掉当前串的第一个字符、第二个字符...直到剩下的串在trie树上有,便连fail边。
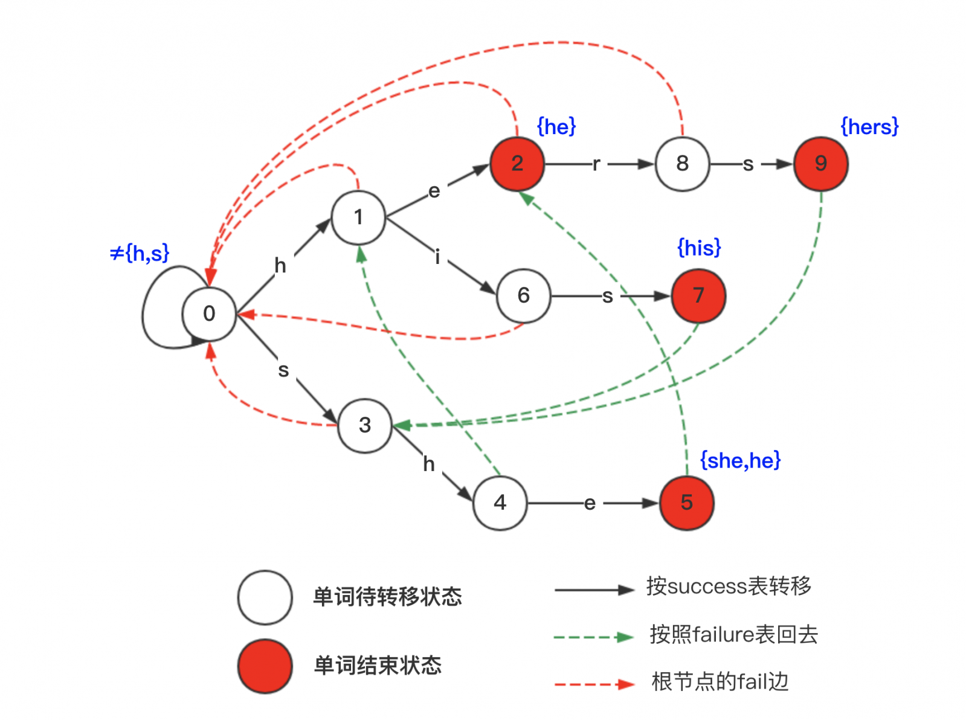
寻找fail:
-当前trie树上节点x(字符temp)失配时,找到父亲的失配边fail[fa[x]]。
--如果fail[fa[x]]存在值为temp的子节点,那么fail[x]=trie[fail[fa[x]]][temp]。
--否则找到父亲的失配边的失配边fail[fail[fa[x]]]。
---如果fail[fail[fa[x]]]存在值为temp的子节点,那么fail[x]=trie[fail[fail[fa[x]]]][temp]。
---否则云云...
fail:字符串的通信
fail[x]代表后缀链接(suffix link)
应用
AC自动机的题围绕计数问题,即在AC自动机fail树上做各种DP。
y结点的fail指向x说明x是y的极大后缀。
fail树:所有的父亲都是孩子的后缀,深度越浅单词长度越短。
void ins(int i){
int k=0;
for(int j=0;j<word[i].size();++j){
if(!trie[k][word[i][j]]) trie[k][word[i][j]]=++cnt;
k=trie[k][word[i][j]];
}
end[k]=1;
}
queue<int> q;
void Build_Fail(){
for(int i=1;i<=26;++i){
if(son[0][i]) q.push(son[0][i]);
}
while(q.size()){
int u = q.front(); q.pop();
for(int i=1;i<=26;++i){
if(!trie[u][i]){
trie[u][i]=trie[fail[u]][i];
}
else{
fail[trie[u][i]]=trie[fail[u]][i];
q.push(trie[u][i]);
}
}
}
}
void find(int pos, int x){
if(x>n) return;
if(end[pos]) ans++;
if(trie[pos][x]) find(trie[pos][x], x+1);
else find(fail[pos], x);
}
int main(){
for(int i=1;i<=m;++i){
ins(i);
}
getfail();
find();
}
JSOI2007 文本生成器
如果一篇文章中至少包含使用者们了解的一个单词,那么我们说这篇文章是可读的(我们称文章a包含单词b,当且仅当单词b是文章a的子串)。
可读的单词是一个字典。
需要指出GW文本生成器 v6生成的所有文本中可读文本的数量。
单词总数<=60。
单词长度<=100。
文章字母只允许有大写字母。
求出一个单词都不包含的方案数求出来,再用总的方案数去减。
在AC自动机上DP。f[i][j]表示字符串处理到第i位,此时AC自动机上对应的是结点j时一个单词都不包含的方案数。
2018ACM-ICPC Beijing Onsite H
给你一个n和m,之后给你一个长度为n的01串T。
问有多少个长度为m的01串S满足,T在最多修改一位的情况下可以成为S的子串。
T修改一位将产生一个新串,所以一共m个可能的串。把这m个串扔进一个AC自动机。再让S匹配一次AC自动机即可。
HEOI 2012 旅行问题
给一堆字符串。
每次询问两个字符串i,k,求第i个字符串长度为j的前缀(si[1..j])和第k个字符串长度为l的前缀(sk[1..l])的最长公共后缀。
而且这个后缀必须是字符串集合中某个字符串的前缀。
而且这个后缀必须是字符串集合中某个字符串的前缀。说明是AC自动机上的节点。前缀的最长公共后缀是fail树上他们的LCA。倍增求LCA会被卡,可以用更快的树链剖分。这里采用轻重链剖分。
轻重链剖分求LCA
两个点,每次把所在链链顶的深度浅的点跳到链顶的父亲。直到两个点在同一条链上,这时深度浅的点就是要求的LCA。
本文来自博客园,作者:咕咕坤,转载请注明原文链接:https://www.cnblogs.com/GuguKun/p/15042177.html
