
Misc_XCTF_WriteUp | base64stego
题目
提示:
菜狗经过几天的学习,终于发现了如来十三掌最后一步的精髓
题目:

分析
尝试打开压缩包,发现需要密码。但准备爆破的时候被提示 zip 未被加密:
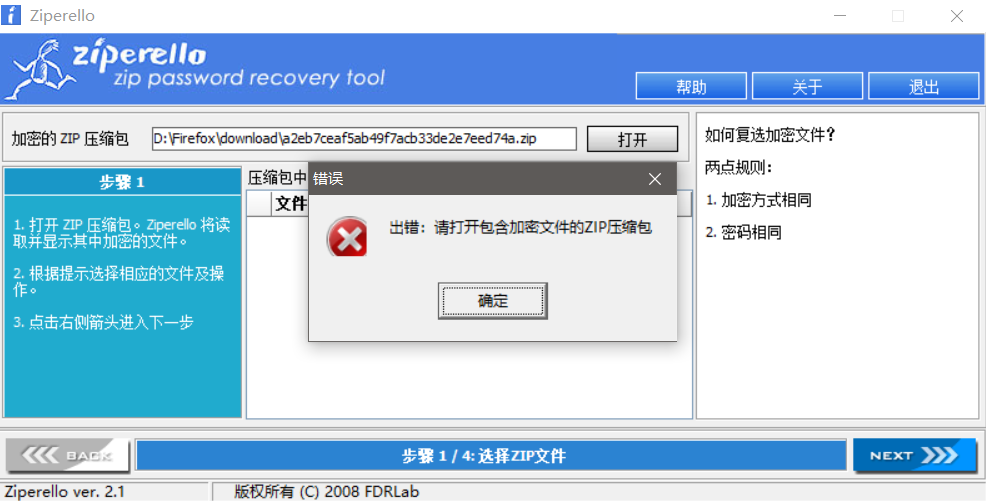
猜测是 zip 伪加密,打开十六进制文件,发现数据区的全局方式位标记第 2/4 个数是偶数 0,而目录区的第 2/4 是奇数 9:


将 9 改为偶数 0 保存,打开压缩包,是一个 base64 编码的文件:
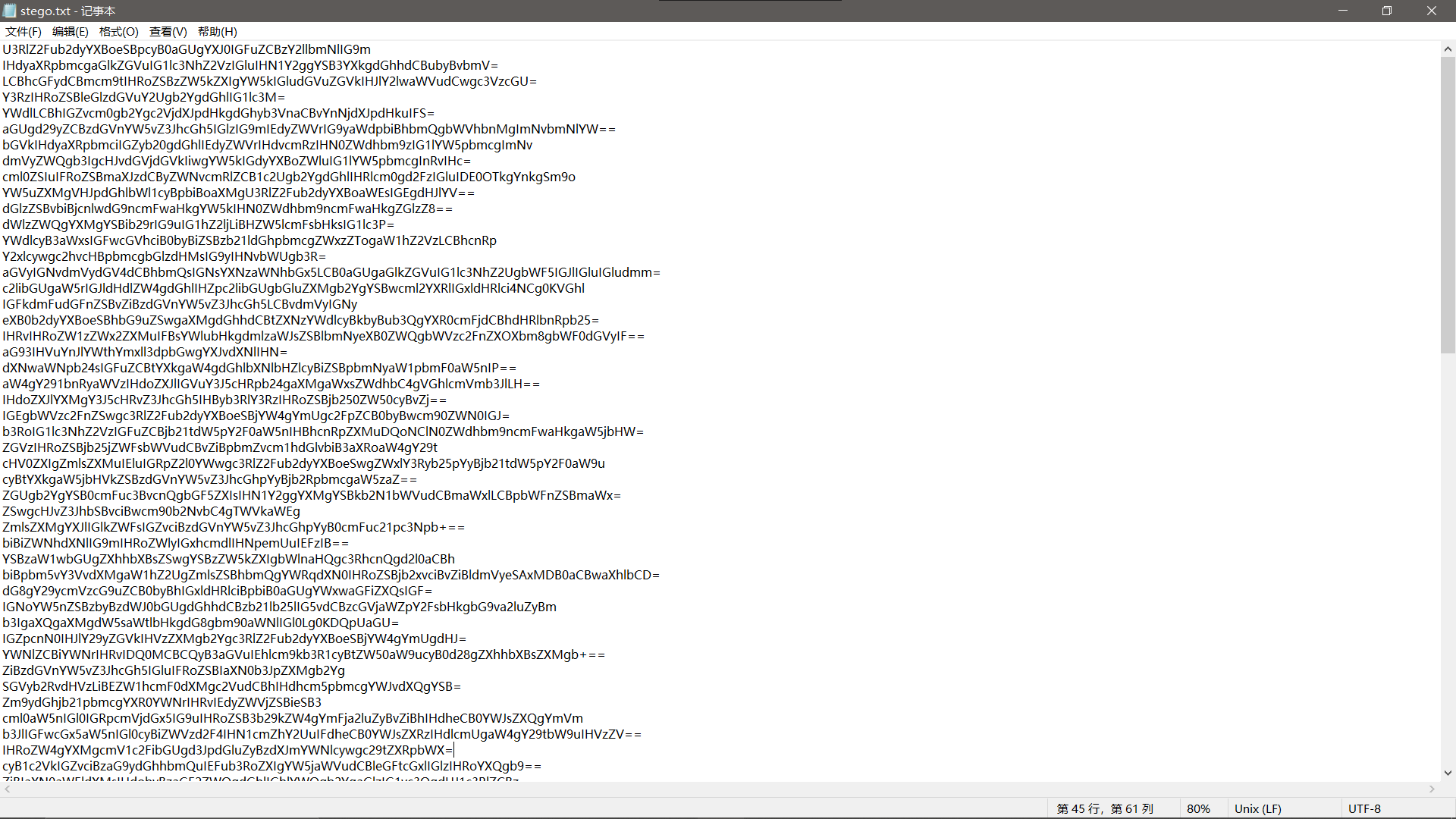
将文件内容 base64 解码:
import base64 stego = open("D:/Firefox/download/unlock/stego.txt", 'r', encoding='utf-8') stego_decode = open("D:/Firefox/download/unlock/stego_decode.txt", 'w') for line in stego.readlines(): line = line.strip() stego_decode.write(base64.b64decode(line.encode("gb18030")).decode("gb18030"))
得到隐写术的 wiki 内容:

找了一圈没找到 flag,难道是…… base64 隐写?
编辑文件名的时候翻译了“隐写”一词,得到 “steganography”。
base64 加密是将文本每个字节 8 比特的数据按每 6 比特分组,当最后一个分组字节数不足 6 比特时用 0 补充,同时每补充 2 个 0 就在编码后的 base64 文本末尾补充一个 =。因为 6 和 8 的最大公约数为 2,因此最后一个分组缺少的字节只有可能为 2 或 4 比特,即编码后的 base64 字节末尾最多可能补充 2 个 =。
在此基础上,base64 隐写是利用加密过程中最后一个分组补充 0 的位置写入隐藏信息。因为 base64 解码是根据编码结果末尾的 = 符号数判断填充的比特数,故更改原文最后一个分组的补充字节不会影响解码。
根据隐写原理,更改 python3 代码如下:
stego = open("D:/Firefox/download/unlock/stego.txt", 'r', encoding='utf-8') # 以读方式打开文件stego.txt def base64_index(c): # base64解码为二进制数对照表 base64_table = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/' for i in range(len(base64_table)): if c == base64_table[i]: return i def steganography(): binary = '' # 存储二进制串 for line in stego.readlines(): # 按行读取 line = line.strip() # 去掉末尾\n if line[-1] == '=': if line[-2] == '=': # 如果末尾有俩= # 对倒数第3个base64字符(填充了0的字符)查表 # ->转为二进制 # ->将开头的'0b'换成'0000',否则取的末尾比特数可能不足,如0101会被输出为101 # ->join()将list转为str # ->输出最后4比特 binary += ''.join([bin(base64_index(c)).replace('0b', '0000') for c in line[-3]])[-4:] else: # 如果末尾只有一个= # 对倒数第2个base64字符(填充了0的字符)查表 # ->转为二进制 # ->将开头的'0b'换成'0000',否则取的末尾比特数可能不足,如0101会被输出为101 # ->join()将list转为str # ->输出最后2比特 binary += ''.join([bin(base64_index(c)).replace('0b', '0000') for c in line[-2]])[-2:] for i in range(len(binary) // 8): # 步长8遍历binary字符串 print(chr(int(binary[i * 8:(i + 1) * 8], 2)), end='') # 每8字节从二进制字符串转十进制值->转字符串->无换行打印 if __name__ == '__main__': steganography()
得到 flag,将可打印字符按格式提交即可。
Flag
flag{Base_sixty_four_point_five}
参考
成功解决UnicodeDecodeError: 'utf-8' codec can't decode-【评论区-第1条-知一】-知乎
Base64原理以及隐写术-棒棒鸡不棒-腾讯云开发者社区
Python File(文件) 方法-菜鸟教程
Python读取txt文本三种方式-年少纵马且长歌-知乎
Python strip()方法-菜鸟教程
Python3 join()方法-菜鸟教程
Python 基础教程 _ 菜鸟教程
本文作者:Guanz
本文链接:https://www.cnblogs.com/Guanz/p/17874825.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步