
Web_XCTF_WriteUp | Training-WWW-Robots
题目
分析
标题大致翻译:
训练 WWW 网络爬虫。
场景内部文段大致翻译:
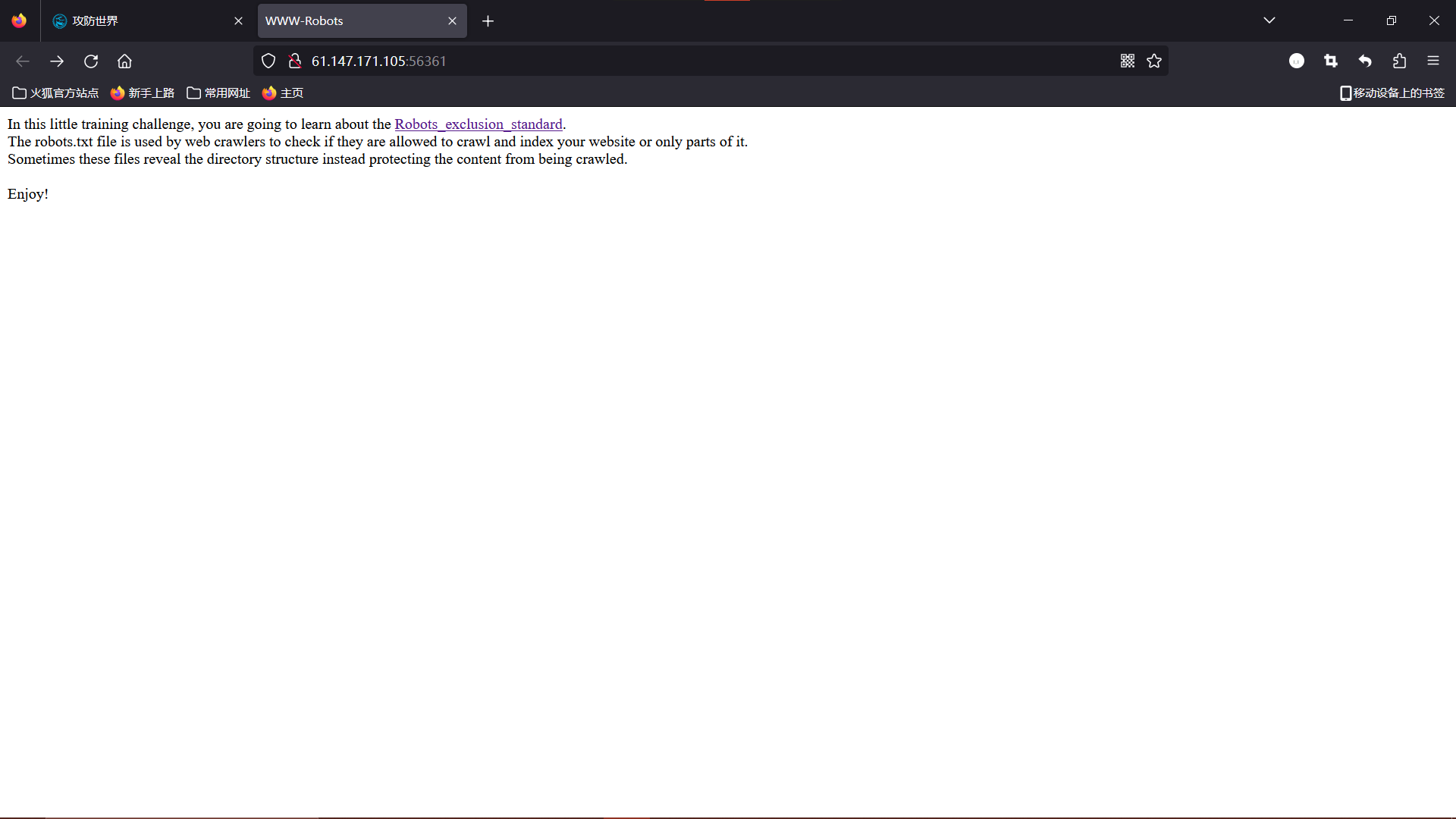
在这个小小的训练挑战中,您将学习 Robots_exclusion_standard(网络爬虫排除标准)。
robots.txt 文件用于网络爬虫检查它们是否被允许抓取和索引您的网站或仅部分网站。
有时,这些文件揭示了目录结构,而不是保护内容不被抓取。享受吧!
根据指引,我们来看看场景的 robot.txt。在 url 后接上 /robot.txt:
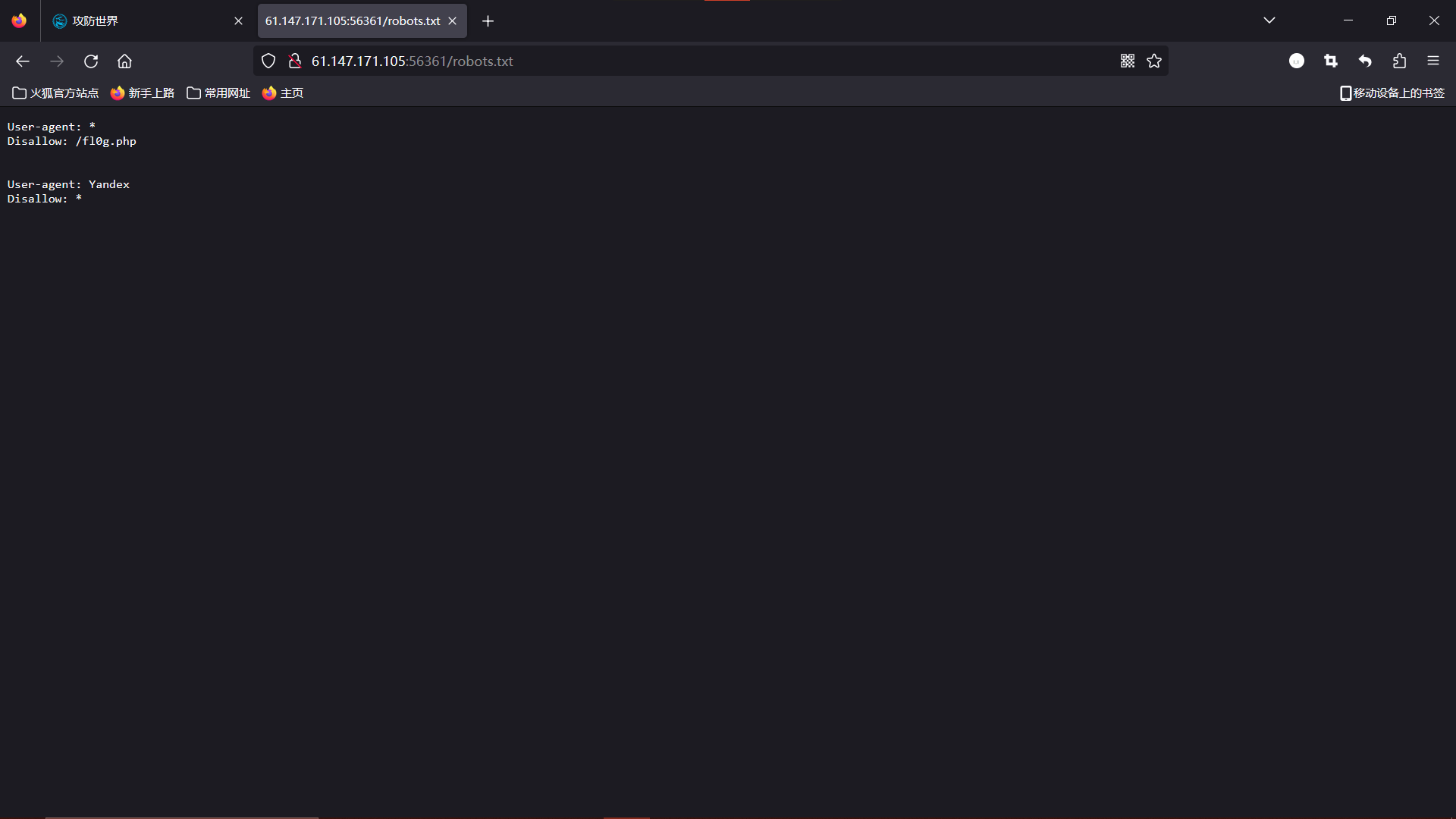
看到第一条限制中爬虫不允许访问 /fl0g.php,这文件名字看着像 flag,打开看看。在 url 后接上 /fl0g.php:
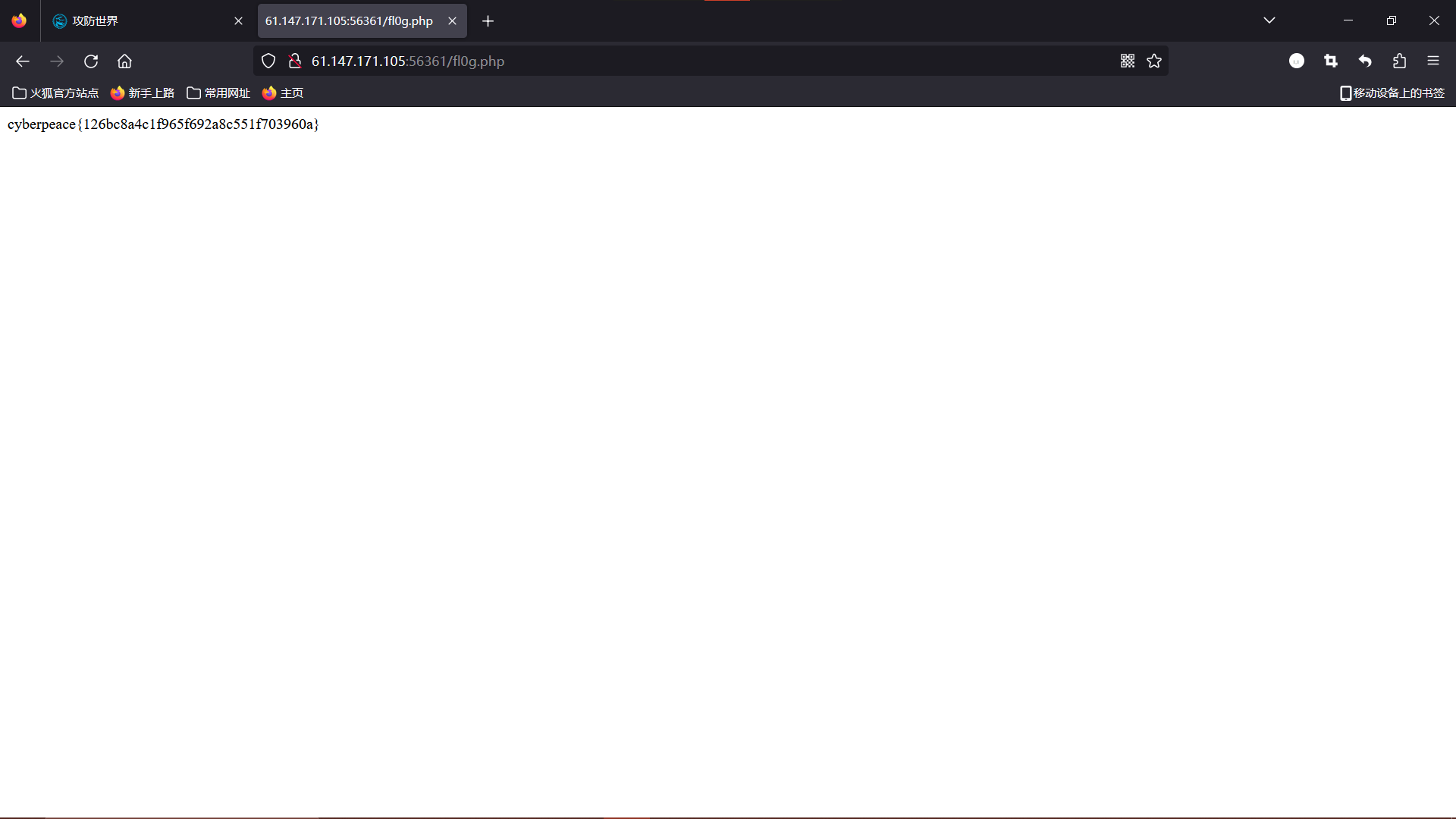
得到 flag。
Flag
cyberpeace{126bc8a4c1f965f692a8c551f703960a}
参考
Robots协议 :Robots Exclusion Standard(网络爬虫排除标准)-Amber.Li-CSDN
爬虫第一步:查看robots.txt-宋小雅-知乎
本文作者:Guanz
本文链接:https://www.cnblogs.com/Guanz/p/17857297.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。
分类:
标签:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步