torch中clone()与detach()操作
一、 函数解释
clone()- 返回一个新的tensor,这个tensor与原始tensor的数据不共享一个内存(也就是说, 两者不是同一个数据,修改一个另一个不会变)。
- requires_grad属性与原始tensor相同,若requires_grad=True,计算梯度,但不会保留梯度,梯度会与原始tensor的梯度相加。
detach()- 返回一个新的tensor,这个tensor与原始tensor的数据共享一个内存(也就是说,两者是同一个数据,修改原始tensor,new tensor也会变; 修改new tensor,原始tensor也会变)。
- require_grad设置为False(也就是网上说的从计算图中剥除,不计算梯度)。
- 在下图的detach()中 \(X \ne False\) 画的也不是很准确,应该是不完全等于。其中\(X\)的取值有两种可能(\(False\) or \(True\)),但new Tensor 只有一种可能,也就是False.
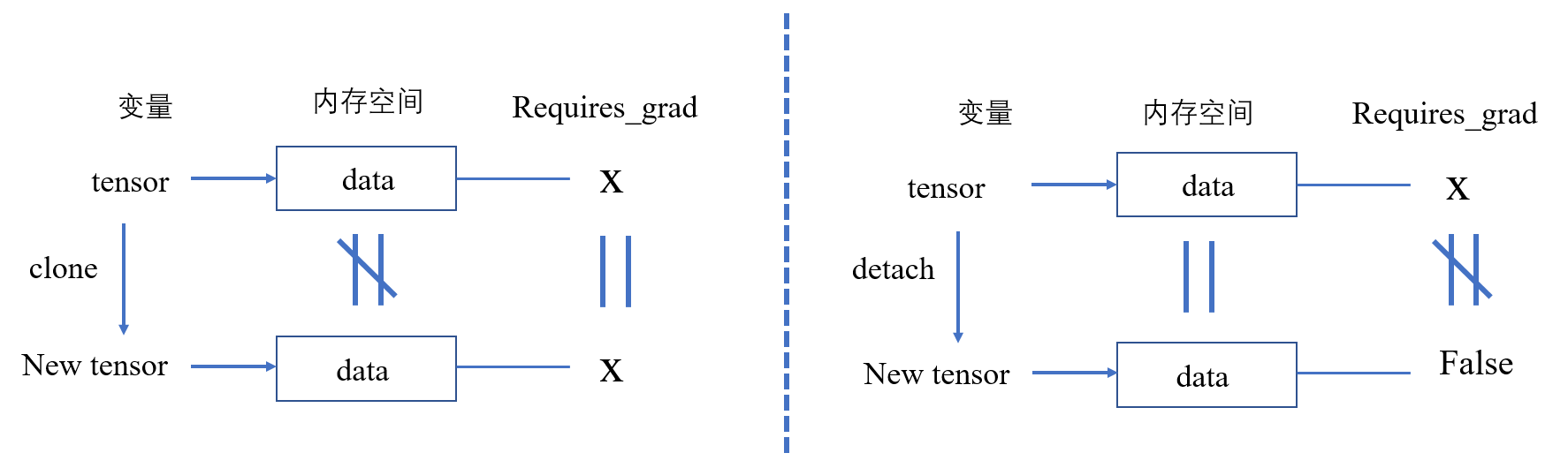
有一张表解释的很清楚:

二、 实验
# 对应clone的观点1
a = torch.tensor([1.], dtype=torch.float32, requires_grad=True)
b = a.clone()
a.data *= 3
print("Tensor:", a)
print("New Tensor:", b)
Tensor: tensor([3.], requires_grad=True)
New Tensor: tensor([1.], grad_fn=<CloneBackward>)
# 对应clone的观点二
a = torch.tensor([1.], dtype=torch.float32, requires_grad=True)
b = a.clone()
z = a**2 + b*2
z.backward()
print("Tensor requires_grad:", a.requires_grad)
print("Tensor requires_grad:", a.grad)
print("NewTensor requires_grad:", b.requires_grad)
print("NewTensor requires_grad:", b.grad)
输出:
Tensor requires_grad: True
Tensor requires_grad: tensor([4.])
NewTensor requires_grad: True
NewTensor requires_grad: None
# 对应detach的观点1
a = torch.tensor([1.], dtype=torch.float32, requires_grad=True)
b = a.detach()
a.data *= 3
print("Tensor", a)
print("New Tensor", b)
输出:
Tensor: tensor([3.], requires_grad=True)
New Tensor: tensor([3.])
# 对应detach观点2
a = torch.tensor([1.], dtype=torch.float32, requires_grad=True)
b = a.detach()
z = a**2 + b*2
z.backward()
print("Tensor requires_grad:", a.requires_grad)
print("Tensor requires_grad:", a.grad)
print("NewTensor requires_grad:", b.requires_grad)
print("NewTensor requires_grad:", b.grad)
输出:
Tensor requires_grad: True
Tensor requires_grad: tensor([2.])
NewTensor requires_grad: False
NewTensor requires_grad: None
参考链接:
