第一次个人编程作业
| 这个作业属于哪个课程 | 班级的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 学习如何作为软件工程师开发项目 |
计算模块接口的设计与实现过程
此程序主要用jieba库来实现中文的分词,再通过re库的正则表达式来删除计算文章相似度不相关的元素,最后通过计算词频来算出余弦相似度。
jieba
特点
- 支持四种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
- paddle模式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词。
更多详细内容见 README.md
在此程序中采用的是jieba的精确模式,因为使用精确模式可以得到更准确的分词结果,这对于文章相似度计算来说非常重要,它可以减少错误分词对相似度计算的影响。
re
特点
- 强大的文本处理能力:正则表达式提供了一种简洁而强大的方式来匹配、查找和替换字符串中的特定模式。这使得re库非常适合处理复杂的文本数据。
- 灵活性:正则表达式可以用来匹配几乎任何类型的文本模式,包括电子邮件地址、电话号码、日期、URL等,以及更复杂的模式。
- 高效性:尽管正则表达式的语法可能看起来复杂,但它们可以非常高效地处理大量的文本数据。一旦正则表达式被编译,它可以快速地应用于多个字符串。
re库是Python中处理字符串和文本数据的强大工具,可以帮助预处理文本数据,从而提高相似度计算的准确性和效率。
NumPy
特点
- 性能高效:NumPy是基于C语言开发的,对于数值计算进行了优化,因此在执行大规模数值计算时,比纯Python代码要快得多。
- 强大的数组操作:文章相似度的计算通常涉及到矩阵操作,余弦相似度就需要计算词频矩阵的点积和范数。NumPy提供了丰富和高效的数组操作,非常适合进行此类计算。
NumPy库为此程序提供了向量的点积和欧几里得范数的计算方法。
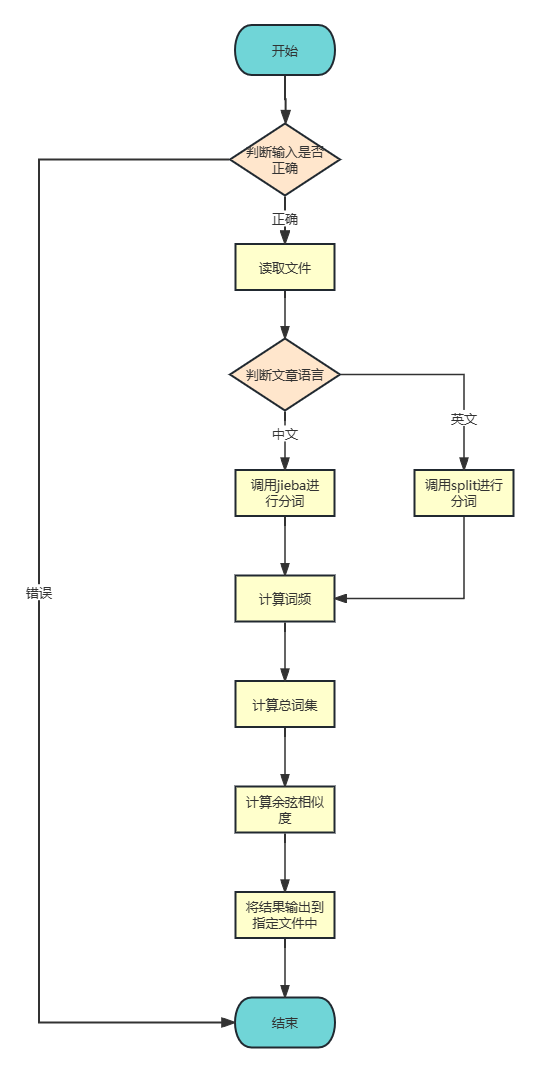
主要流程图:
计算模块接口部分的性能改进
VizTracer
使用VizTracer来进行性能分析
计算余弦相似度的性能改进
改进前使用的是math库中的sqrt和pow函数来计算余弦相似度,所用时为1ms 386us 387ns。

改进后使用的是numpy库中的dot和norm函数来分别计算向量的点积和欧几里得范数,用时为780us 386ns。
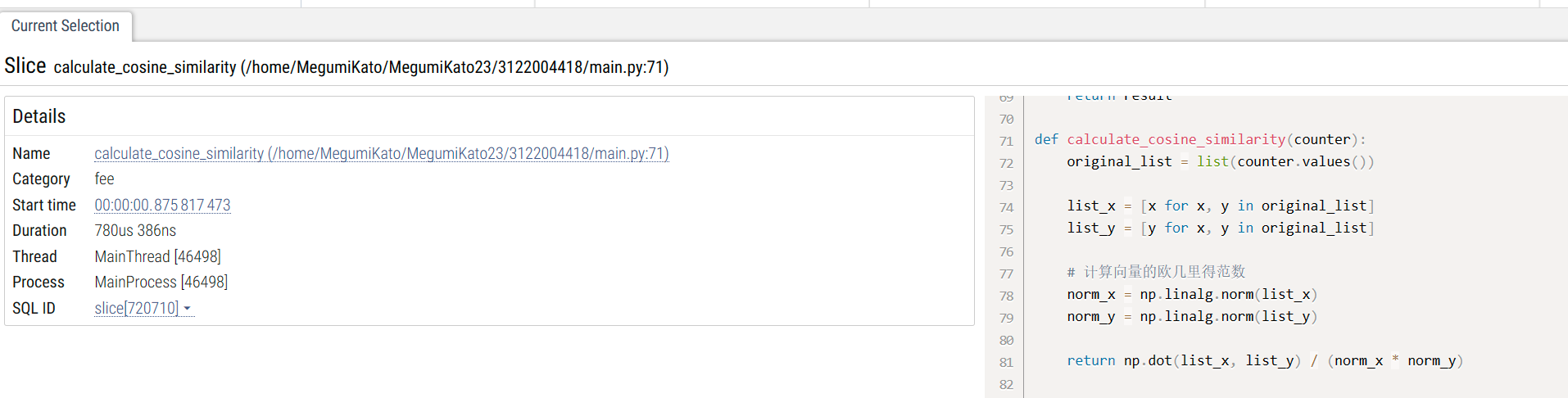
性能分析图:
耗时最大的函数为jieba_tokenize()

计算模块部分单元测试展示
对main()函数的单元测试代码:
class TestMainWithArgs(unittest.TestCase):
@patch('sys.argv', ['script.py', 'original.txt', 'plagiarized.txt', 'output.txt'])
def test_main_with_args(self):
with patch('sys.argv', new=['main.py', 'orig.txt', 'orig_0.8_add.txt', 'output.txt']):
main()
self.assertEqual(sys.argv[1], 'orig.txt')
self.assertEqual(sys.argv[2], 'orig_0.8_add.txt')
self.assertEqual(sys.argv[3], 'output.txt')
def test_main_without_args(self):
with patch('sys.argv', new=['main.py']):
with self.assertRaises(SystemExit):
main()
main()函数如下:
def main():
# 确保命令行参数数量正确
if len(sys.argv) != 4:
print("使用方法:python main.py <原文路径> <抄袭文路径> <输出路径>")
sys.exit(1)
# 从命令行参数获取文件路径
original_path = sys.argv[1]
plagiarized_path = sys.argv[2]
output_path = sys.argv[3]
# 读取文件内容
original_text = read_file(original_path)
plagiarized_text = read_file(plagiarized_path)
# 计算相似度
similarity = calculate_similarity_tf(original_text, plagiarized_text)
# 输出结果到文件
with open(output_path, 'w', encoding='utf-8') as output_file:
output_file.write(f"Similarity: {similarity:.2%}")
测试的函数使用了@patch装饰器来模拟sys.argv,并传递了预期的参数。然后,我们调用main函数并验证sys.argv的值是否符合预期。
单元测试覆盖率截图:
使用coverage工具进行检验
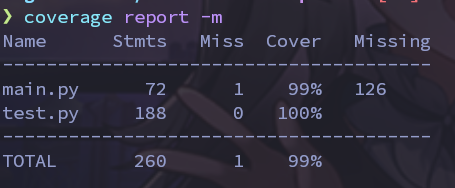
可见代码覆盖率基本100%
计算模块部分异常处理说明
在函数开始时的命令行输入时,如果用户输入不符合要求,则会退出程序,并打印“使用方法:python main.py <原文路径> <抄袭文路径> <输出路径>”
在单元测试中有如下代码:
class TestMainWithArgs(unittest.TestCase):
@patch('sys.argv', ['script.py', 'original.txt', 'plagiarized.txt', 'output.txt'])
def test_main_without_args(self):
with patch('sys.argv', new=['main.py']):
with self.assertRaises(SystemExit):
main()
该代码模拟了用户输入未满足要求时的场景。
PSP
| PSP2.1 | 阶段 | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 30 |
| Estimate | 估计这个任务需要多少时间 | 120 | 160 |
| Development | 开发 | 120 | 100 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 50 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 120 | 150 |
| Code Review | 代码复审 | 30 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 30 | 50 |
| Test Report | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 15 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 815 | 960 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号