bs4模块之照片爬取
这次获取的是电脑壁纸
我们打开这个网址 传送门
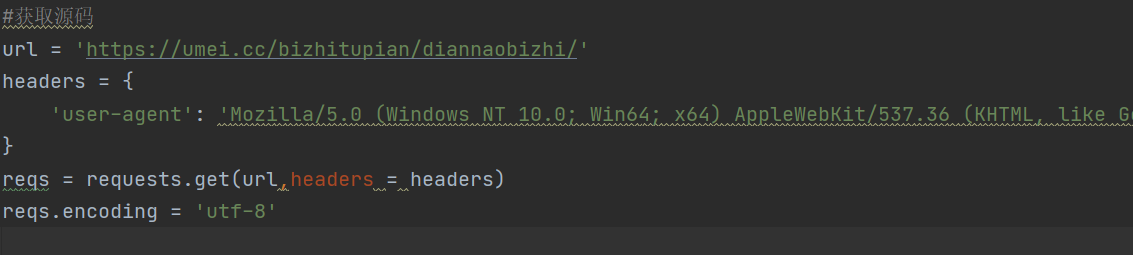
首先获取源码,三步走,url,user-agent,encoding编码方式,注意的是user-agent一个网站只获取一次就可以,它的子网页跟它一样

接下来将页面源码交给Beautifulsoup生成bs对象
bs 查找只有两个属性,find 和 find_all,格式是一样的,
如find('html标签',属性=值),可以只写标签,需要注意class是python关键字,这里写成class_
find只查找首个标签,find_all查找所有的标签,并返回一个列表
因此,find_all 之后就不能直接再加.find之类的操作
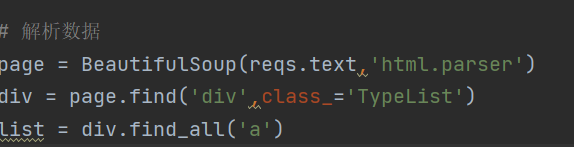
接下来解析数据,对于bs4 要用 'html.parser'解析数据
之后用find和find_all获取高清图片下载地址就可
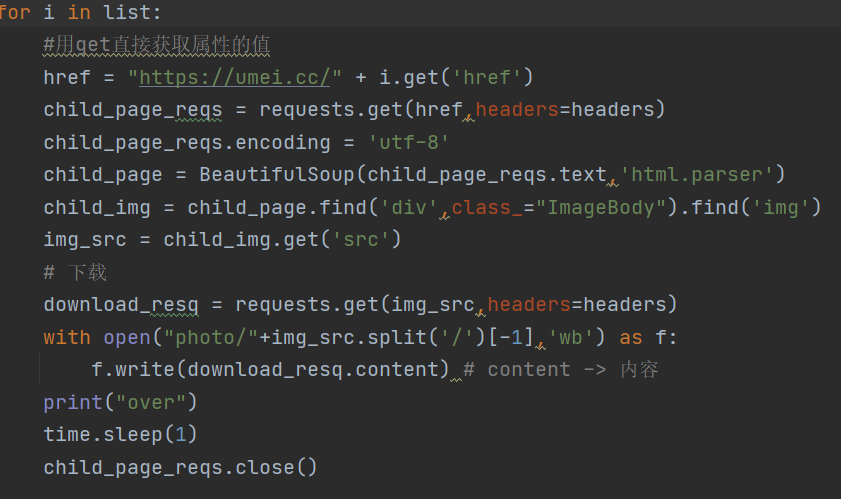
结尾一定一定要记得要有requests的close(),每请求一个页面都要close(),否则会一直访问,有概率会被封ip(就几分钟)
code:
import csv
import requests
import time
from bs4 import BeautifulSoup
k = 1
#获取源码
url = 'https://umei.cc/bizhitupian/diannaobizhi/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.40'
}
reqs = requests.get(url,headers=headers)
reqs.encoding = 'utf-8'
# 解析数据
page = BeautifulSoup(reqs.text,'html.parser')
div = page.find('div',class_='TypeList')
list = div.find_all('a')
for i in list:
#用get直接获取属性的值
href = "https://umei.cc/" + i.get('href')
child_page_reqs = requests.get(href,headers=headers)
child_page_reqs.encoding = 'utf-8'
child_page = BeautifulSoup(child_page_reqs.text,'html.parser')
child_img = child_page.find('div',class_="ImageBody").find('img')
img_src = child_img.get('src')
# 下载
download_resq = requests.get(img_src,headers=headers)
with open("photo/"+img_src.split('/')[-1],'wb') as f:
f.write(download_resq.content) # content -> 内容
print("over")
time.sleep(1)
child_page_reqs.close()
reqs.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号