

AC自动机---个人总结
比较好的 AC自动机算法详解..
【转】http://www.cppblog.com/mythit/archive/2009/04/21/80633.html
个人总结:【图是盗用的..】
ac自动机是用来求出:给出n个单词,和一篇文章arr[],问arr中出现了多少个单词..
第一步:根据给出的n个单词构造一棵字典树
第二步:根据字典树完成失配指针
第三步:枚举文章中的每个字符,并根据拥有了失配指针的字典树 查找 出现的单词个数
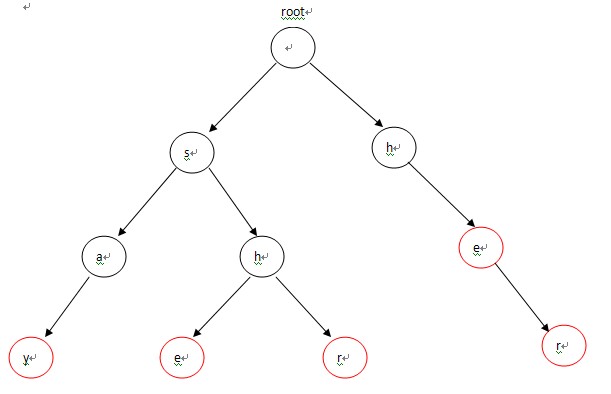
以单词:say she shr he her 文章:yasherhs 举例:
第一步:根据给出的n个单词构造一棵字典树


1 const int kind = 26; 2 struct node{ 3 node *fail; //失败指针 4 node *next[kind]; //Tire每个节点的个子节点(最多个字母) 5 int count; //是否为该单词的最后一个节点 6 node(){ //构造函数初始化 7 fail=NULL; 8 count=0; 9 memset(next,NULL,sizeof(next)); 10 } 11 }*q[500001]; //队列,方便用于bfs构造失败指针 12 char keyword[51]; //输入的单词 13 char str[1000001]; //模式串 14 int head,tail; //队列的头尾指针
1 void insert(char *str,node *root){ 2 node *p=root; 3 int i=0,index; 4 while(str[i]){ 5 index=str[i]-'a'; 6 if(p->next[index]==NULL) p->next[index]=new node(); 7 p=p->next[index]; 8 i++; 9 } 10 p->count++; //在单词的最后一个节点count+1,代表一个单词 11 }
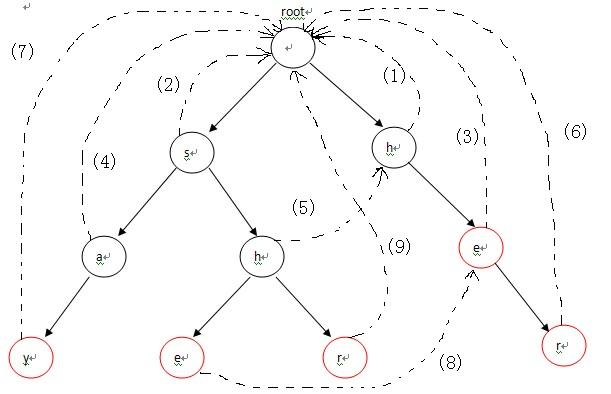
第二步:根据字典树完成失配指针
<结果是 (she)每一个字符(s,h,e)都会指向自己上一个字符(root,s,h)的失配指针(root,root,root->h)后的和当前字符匹配((如果没有则指向root)root, root->h, root->h->e)的字符>
即结果是保证树中的节点(node)会指向拥有相同字符串(parents->..->node = root->..->node',parents表示某个祖先节点,node'表示相同字符节点)的枝桠(没有则指向root)
1 void build_ac_automation(node *root){ 2 int i; 3 root->fail=NULL; 4 q[head++]=root; 5 while(head!=tail){ 6 node *temp=q[tail++]; 7 node *p=NULL; 8 for(i=0;i<26;i++){ 9 if(temp->next[i]!=NULL){ 10 if(temp==root) temp->next[i]->fail=root; 11 else{ 12 p=temp->fail; 13 while(p!=NULL){ 14 if(p->next[i]!=NULL){ 15 temp->next[i]->fail=p->next[i]; 16 break; 17 } 18 p=p->fail; 19 } 20 if(p==NULL) temp->next[i]->fail=root; 21 } 22 q[head++]=temp->next[i]; 23 } 24 } 25 } 26 }
第三步:枚举文章中的每个字符,并根据拥有了失配指针的字典树 查找 出现的单词个数 <cnt += node.cnt>
1 int query(node *root){ 2 int i=0,cnt=0,index,len=strlen(str); 3 node *p=root; 4 while(str[i]){ 5 index=str[i]-'a'; 6 while(p->next[index]==NULL && p!=root) p=p->fail; 7 p=p->next[index]; 8 p=(p==NULL)?root:p; 9 node *temp=p; 10 while(temp!=root && temp->count!=-1){ 11 cnt+=temp->count; 12 temp->count=-1; 13 temp=temp->fail; 14 } 15 i++; 16 } 17 return cnt; 18 }
查找方法是如果上一个字符的下一个字符和当前字符匹配,则加上node.cnt,并不断按照失配指针查找出现的单词,不断加上node.cnt
失配,则根据失配指针去找可能匹配的出现的单词,找到则加上node.cnt
