Redis入门指南--五种类型及其基本指令
第一、二章 redis入门与准备
大概阐述一下五种基本类型,分别是散列,列表,集合,字符串,有序集合
redis-server 启动redis redis-server --port 3306 自定义端口
redis-cli shutdown 关闭redis,并且正常持久化
一些基本的配置信息,包括开机设置等值得参考一下。
redis数据库可以通过 select 1 这种方式来选择不同的数据库。然而这些数据库和我们理解的数据库有所不同,首先不支持定义名字,同时它也不支持为各自的数据库定义密码,所以不同的应用最好不要放在同一个redis下面,而且数据库之间是不完全隔离的,一个命令可能会影响多个数据库,一个空的redis只占1mb,所以理论上一个应用用一个redis就可以。
第三章入门
字符串类型
- 获得符合规则的简明键名列表 keys pattern ,pattern是符合glog的正则匹配,包括了四种,?表示匹配任意一个字符,*表示任意(0)个字符,[]字符范围,\x转义字符。keys指令需要遍历所有的键名所以效率比较低,数量多影响性能,不建议生产环境使用。
- 判断一个键是否存在 exists key ,存在返回1,否则返回0
- 删除键 del key [key ...] ,删除不支持正则表达式,所以可以利用管道还有xargs命令, redis-cli keys "user:*" | xargs redis-cli del 或者是 redis cli `redis keys "user:*"` 后者的效率更高
- 获取键值类型 type key ,返回值有五种类型 string,hash,list,set,zset
- 赋值与取值 set key value 和 get key
- 递增数字 incr key ,如果值是整数会增加一返回当前值,如果是空值默认是0也会自增一,如果不是整数会报错
- 键值的取值一般为 对象类型:对象ID:对象属性
- 增加指定整数 incrby key increment redis>incrby id 2
- 减少指定整数 decr key decrby key decrement
- 增加指定浮点数 incrbyfloat key increment ,可以递增一个双精度浮点例如2.7,5E+4等等
- 向尾部追加值 append key value ,如果是空值则如同是set key value
- 获取字符串长度 strlen key ,如果是空值返回的是0
- 同时获得或者设置多个键值 mget key [key ...] , mset key value [key value ...]
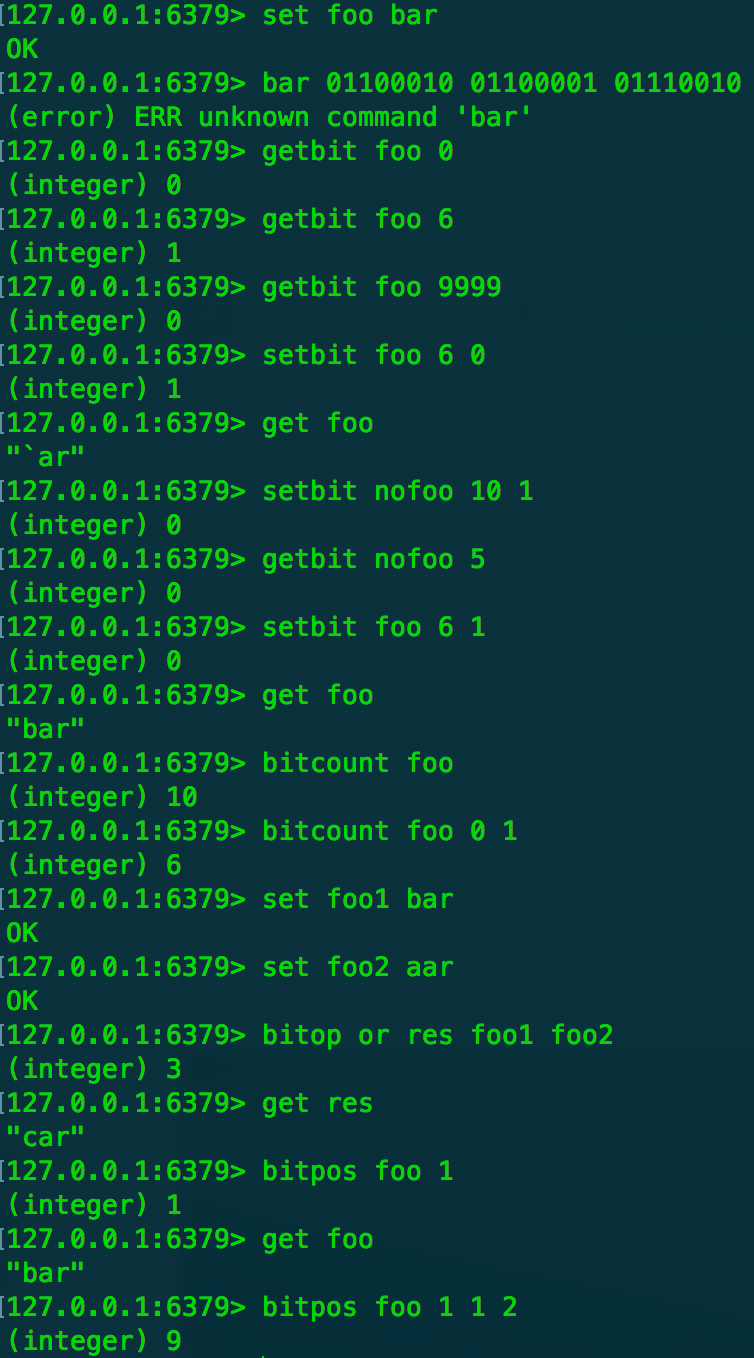
- 位操作 ,偏移量都是从0开始
- getbit key offset 获取键值在指定offset的位置,如果超出则为0
- setbit key offse value 设置键值指定offset,设置超过可到达长度会在中间补全0
- bitcount key [start] [end] 获取key中有多少个1,start和end的单位是字节,取值范围是闭区间
- bitop operation destkey key [key...] 对key值进行操作结果放在destkey中,有and or xor not
- bitpos key bit [start] [end] 获取第一个1的偏移量,start和end的单位是字节,取值范围是闭区间,此时偏移量从头开始和起始字节无关
- 如果键值所有二进制都为1,查询0的偏移位置会定位到该值的下一位,因为redis认为键值长度后面全是0
- setbit指令如果bit超出偏移量会自动分配内存,要考虑空间
散列类型
- 赋值与取值 hset key field value [field value ...] hget key field [field ...] hgetall key ,对于set来说如果是插入操作返回1,如果是更新操作返回0。hgetall返回的形式是列表样式
- 判断字段是否存在 hexists key field 存在返回1,否则返回0
- 当字段不存在时赋值 hsetnx key field value 原子操作,成功返回1,否则返回0
- 增加数字 hincrby key field increment
- 删除字段 hdel key field [field...]
- 只获取字段名或者字段值 hkeys key hvas key
- 获取字段的数量 hlen key
列表类型
- 向列表两端插入值 lpush key value [value ...] rpush key value [value ...]
- 从列表两端弹出值 lpop key rpop key
- 获取列表的个数 llen key时间复杂度是O(1),有现成存储值
- 获取列表的片段 lrange key start stop ,索引从0开始,最末尾的值可以是-1,如果start超过了stop返回空列表,如果stop超过了边界返回到边界位置,取值范围是[start,stop]
- 删除列表指定的值 lrem key count value ,从左开始删除count个value,如果是正数从左边开始删,如果是负数从右边开始删,如果是0删除所有是value的值

- 获取或设置指定索引的值 lindex key index lset key index value
- 只保留列表的指定片段 ltrim key start end 保留的位置为[start end]
- 向列表的指定值左右插入新值 linsert key before|after pivot value 从左到右查找第一个值为pivot的,根据before或者after来控制插入value的位置
- rpoplpush source destination 一般用于循环处理中
集合类型
在redis内部是是使值为空的散列表来实现的,所以集合内所有的元素都不会相同
- 增加/删除元素 sadd key member [member ...] srem key member [member ...] ,返回值是成功操作的值
- 获取所有的元素的值 smembers key
- 是否存在该元素 sismember key member
- 集合间的运算
- 差集运算sdiff key [key ...] 多个key的时候运算顺序从左到右 (key1-key2)-key3...其中key1-key2=key1 - key1Ukey2
- 交集运算sinter key [key ...]
- 并集运算sunion key [key ...]
- 获取集合内元素的个数 scard key
- 进行集合运算另存为 sdiffstore distination key [key ...]
- 随机获取集合内的某一个元素 srandmember key [count] 如果count是正数,则取出count个不重复的的元素,同时这个count大于能取出的就取出最多的,如果count是负数,则取出count个可能重复的的元素,取出的规则是随机hash到哪个桶再随机从hash冲突链中获取。所以如果桶中只有一个元素那么概率比桶中有多个元素高
- 随机的从集合中删除一个元素 spop key
有序集合
是在集合的基础上加上了分数,存储结构有散列类型或者跳跃表
- 增加元素 zadd key score member [score member ...] 返回的是新加入集合内的个数,分数可以是双精度浮点数17E+307,1.5,+inf或者-inf表示正负无穷
- 删除元素 zrem key member [member ...]
- 获得元素的分数 zscore key member
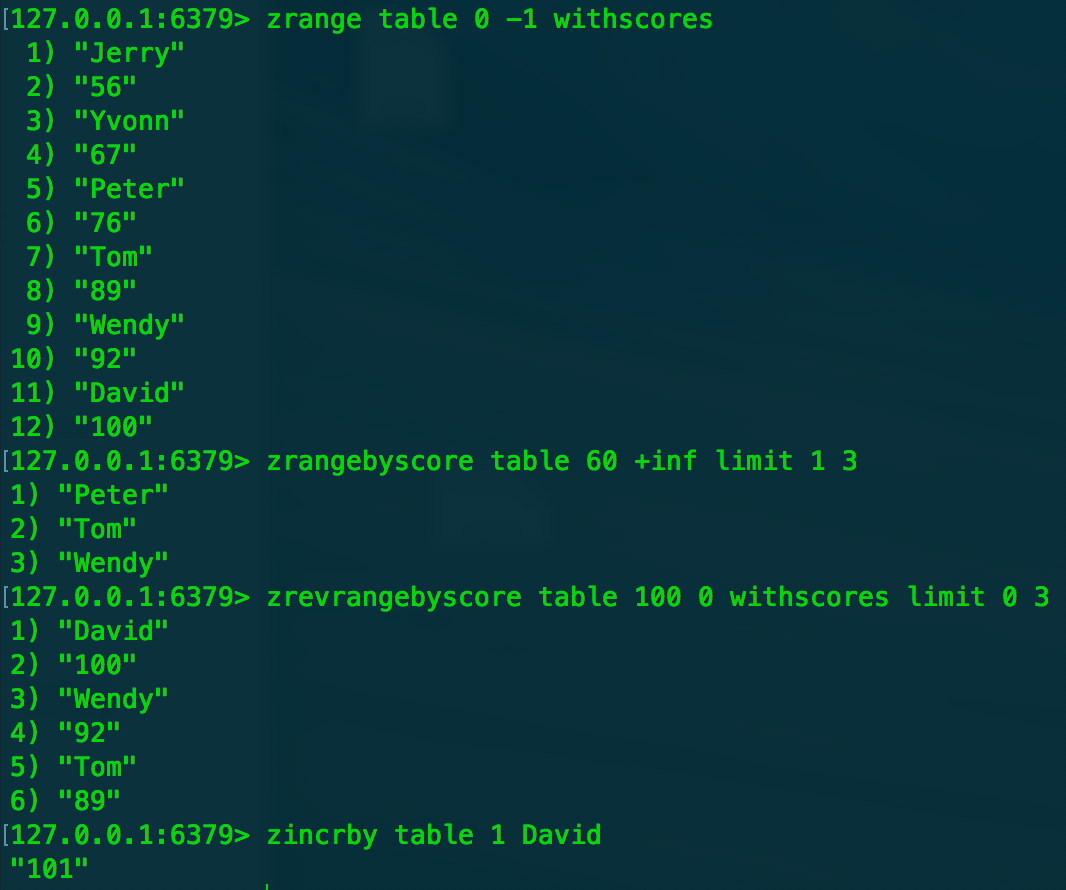
- 获得排名在某个范围内的元素列表 srange key start end [withscores] srevrange key start end [withscores] ,取出按score排名[start end]的元素的值,后面可选参数表示顺便返回score,如果score值一样则按照字典序排名字
- 获得指定分数范围的元素 zrangebyscore key min max [withscores] [limit offset count]
- 增加某个元素的分数 zincrby key increment member
- 获取集合内元素个数 zcard key
- 获取指定分数范围元素个数 zcount key min max
- 按照排名删除元素 zremrangebyrank key start end 返回删除的个数
- 按照分数删除元素 zremrangebyscore key min max 返回删除的个数
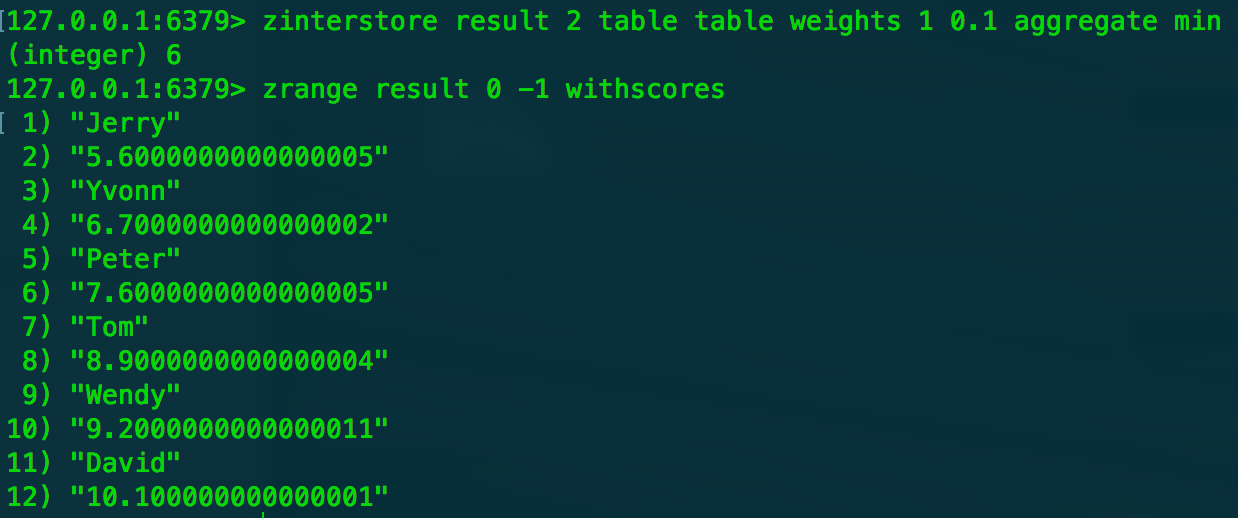
- 计算有序集合的交集 zinterstore destination numkeys key [key ...] [weights weight ...] [aggregate sum|min|max] 参数分别表示key的个数,参与计算的比重,计算方式(默认是sum)