[翻译] 使用AST提升个人解析游戏
本文翻译来自谷歌翻译
在我开始尝试学习计算机科学的旅程之前,有一些术语和短语使我想朝另一个方向发展。
但是我没有奔波,而是装作知识,在交谈中点点头,假装我知道有人在指什么,尽管事实是我不知道并且实际上在我听到《 Super Scary Computer Science Term™》时就完全停止了收听。在本系列的整个过程中,我设法涵盖了很多领域,其中许多术语实际上已经变得不那么吓人了!
不过,有一个大的问题我已经避免了一段时间。直到现在,每当我听到这个词时,我都会感到瘫痪。它是在聚会时偶尔进行的交谈中出现的,有时是在会议中出现的。每一次,我都会想到机器在旋转,计算机吐出了难以理解的代码串,除了我周围的其他人实际上都可以解密它们之外,所以实际上只有我一个人不知道发生了什么(哇,这是怎么发生的?!)。
也许我不是唯一一个有这种感觉的人。但是,我想我应该告诉你这个词的实际含义,对吗?好吧,请做好准备,因为我指的是“难以捉摸的”和看似令人困惑的“抽象语法树”或简称“AST”。经过多年的恐吓,我很高兴终于不再害怕这个词,并真正了解它到底是什么。
现在是时候面对抽象语法树的根了,并升级我们的解析游戏!
从具体到抽象
每一个好的追求都必须有一个坚实的基础,而我们揭开这个结构神秘色彩的使命应该以完全相同的方式开始:当然要有一个定义!
抽象语法树(通常仅称为 AST )实际上只是解析树的简化形式。 在编译器设计的上下文中,术语 “AST”与“语法树” 可以互换使用。

与语法树对应的语法树相比,我们经常考虑语法树(以及语法树的构造方式),语法树[我们已经相当熟悉](https://medium.com/basecs/grammatically-rooting-oneself-with- parse-trees-ec9daeda7dad)。 我们知道“解析树”是包含我们代码的语法结构的树数据结构; 换句话说,它们包含出现在代码“句子”中的所有语法信息,并且直接从编程语言本身的语法中得出。
另一方面,“抽象语法树”忽略了分析树原本将包含的大量语法信息。
相比之下,AST仅包含与分析源文本有关的信息,并且跳过解析文本时使用的任何其他额外内容。
如果我们专注于AST的 “抽象性” ,那么这种区别将变得更加有意义。
我们会记得,“稀疏树” 是一个句子的语法结构的图解图示版本。 换句话说,我们可以说语法分析树准确地表示了表达式,句子或文本的外观。 它基本上是文本本身的直接翻译; 我们采用该句子,并将句子的每个小片段(从标点符号到表达式再到标记)都转换为树形数据结构。 它揭示了文本的具体语法,这就是为什么它也被称为 具体语法树 或 CST 的原因。 我们使用“ 具体 ”一词来描述此结构,因为它是我们的代码的语法副本,以树的形式逐个标记。
但是,是什么使具体的东西变得抽象呢? 好吧,抽象语法树并没有“确切地”向我们展示表达式的样子,即解析树的样子。

相反,抽象的语法树向我们展示了“重要”位,这是我们真正关心的事物,这些意义使我们的代码“句子”本身具有意义。 语法树向我们展示了表达式的重要部分,或我们的源文本的“抽象”语法。 因此,与具体的语法树相比,这些结构是我们代码的抽象表示(在某些方面,它的准确性较低),这正是它们的名称。
现在,我们了解了这两种数据结构之间的区别以及它们表示代码的不同方式,值得提出一个问题:抽象语法树在编译器中的位置如何? 首先,让我们想起到目前为止我们所知道的有关编译过程的所有信息。

假设我们有一个超短而甜美的源文本,看起来像是:5 +(1 x 12)。
我们会记得,在编译过程中发生的第一件事是对文本进行扫描,这是扫描程序执行的一项工作,这导致文本被分解成可能的最小部分,称为词素。 这部分将与语言无关,我们将获得原始文本的精简版。
接下来,将这些词素传递给词法分析器/令牌生成器,后者将源文本的那些小表示形式转换为** tokens **,这将特定于我们的语言。 我们的令牌看起来像这样:[[5,+,(,1,x,12,)]。 扫描程序和令牌生成器的共同努力构成了编译的 “词法分析”。
然后,在对输入进行标记后,将其生成的标记传递给解析器,解析器随后将获取源文本并从中构建一个解析树。 下图以解析树格式示例了标记化代码的外观。

将令牌转换为解析树的工作也称为解析,称为 语法分析 阶段。 语法分析阶段直接取决于词法分析阶段。 因此,词法分析必须始终在编译过程中排在首位,因为我们的编译器解析器只有在分词器完成工作后才能完成工作!
我们可以将编译器的各个部分视为好朋友,它们彼此依赖,以确保我们的代码正确地从文本或文件转换为解析树。
但是回到我们最初的问题:抽象语法树在这个朋友组中适合什么地方? 好吧,为了回答这个问题,首先可以帮助您了解AST的需求。
将一棵树压缩成另一棵
好吧,现在我们有两棵树可以直立在脑海中。 我们已经有了一个解析树,以及如何学习另一个数据结构! 显然,此AST数据结构只是一个简化的分析树。 那么,为什么我们需要它呢? 甚至有什么意义呢?
好吧,让我们看一下解析树,对吧?
我们已经知道解析树在程序的最不同部分代表了我们的程序。 的确,这就是扫描器和令牌生成器如此重要的工作,将我们的表达分解为最小的部分的原因!
真正由程序的最不同部分表示程序意味着什么?
事实证明,有时程序的所有不同部分实际上并不是一直对我们有用。
让我们看一下此处显示的插图,它以解析树格式表示了我们的原始表达式“ 5 +(1 x 12)”。 如果我们以挑剔的眼光仔细观察这棵树,就会发现在某些情况下,一个节点恰好有一个孩子,这也称为单后继节点, 因为它们只有一个子节点(或一个“继任者”)。
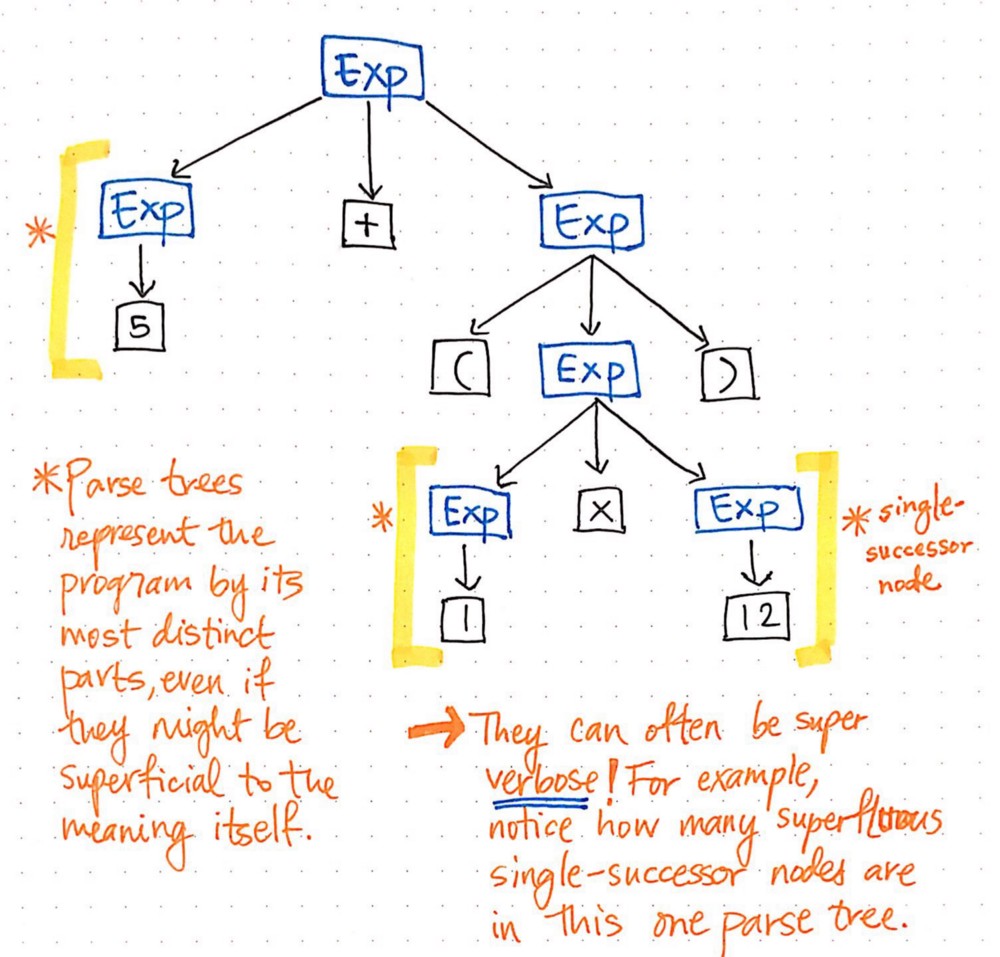
在我们的分析树示例的情况下,单个-后继节点具有一个“表达式”或“ Exp”的父节点,它们具有某个值的单个后继,例如 “5”,“1”或 “12“ 。但是,这里的 “Exp” 父节点实际上并没有为我们增加任何价值,是吗?我们可以看到它们包含令牌/终端子节点,但我们实际上并不关心“表达式”父节点;我们真正想知道的是表达式是什么?
解析树后,父节点根本不会向我们提供任何其他信息。相反,我们真正关心的是单后继节点。确实,这是向我们提供重要信息的节点,对我们而言很重要的部分:数量和价值本身!考虑到这些父节点对我们来说是不必要的事实,很明显,该解析树是一种冗长的结构。
所有这些单后继节点对我们来说都是多余的,根本对我们没有帮助。所以,让我们摆脱它们!
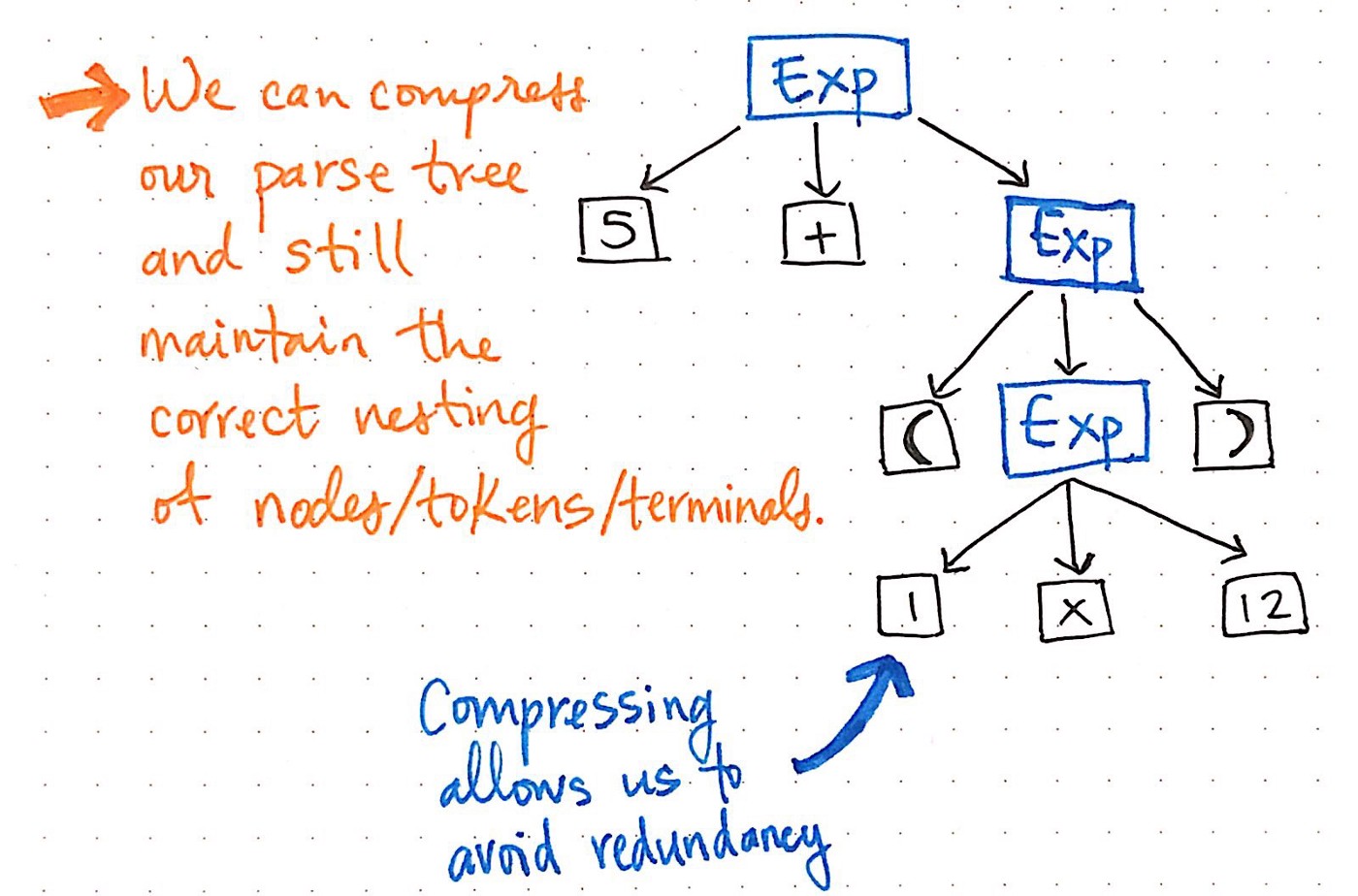
如果我们在解析树中压缩单后继节点,则最终将得到具有相同精确结构的压缩版本。 查看上图,我们会发现我们仍然保持与以前完全相同的嵌套,并且节点/令牌/终端仍然出现在树中的正确位置。 但是,我们设法将其缩小了一点。
我们也可以修剪更多的树。 例如,如果我们看一下当前的解析树,就会发现其中有一个镜像结构。 (1 x 12)的子表达式嵌套在括号()中,括号本身就是令牌。
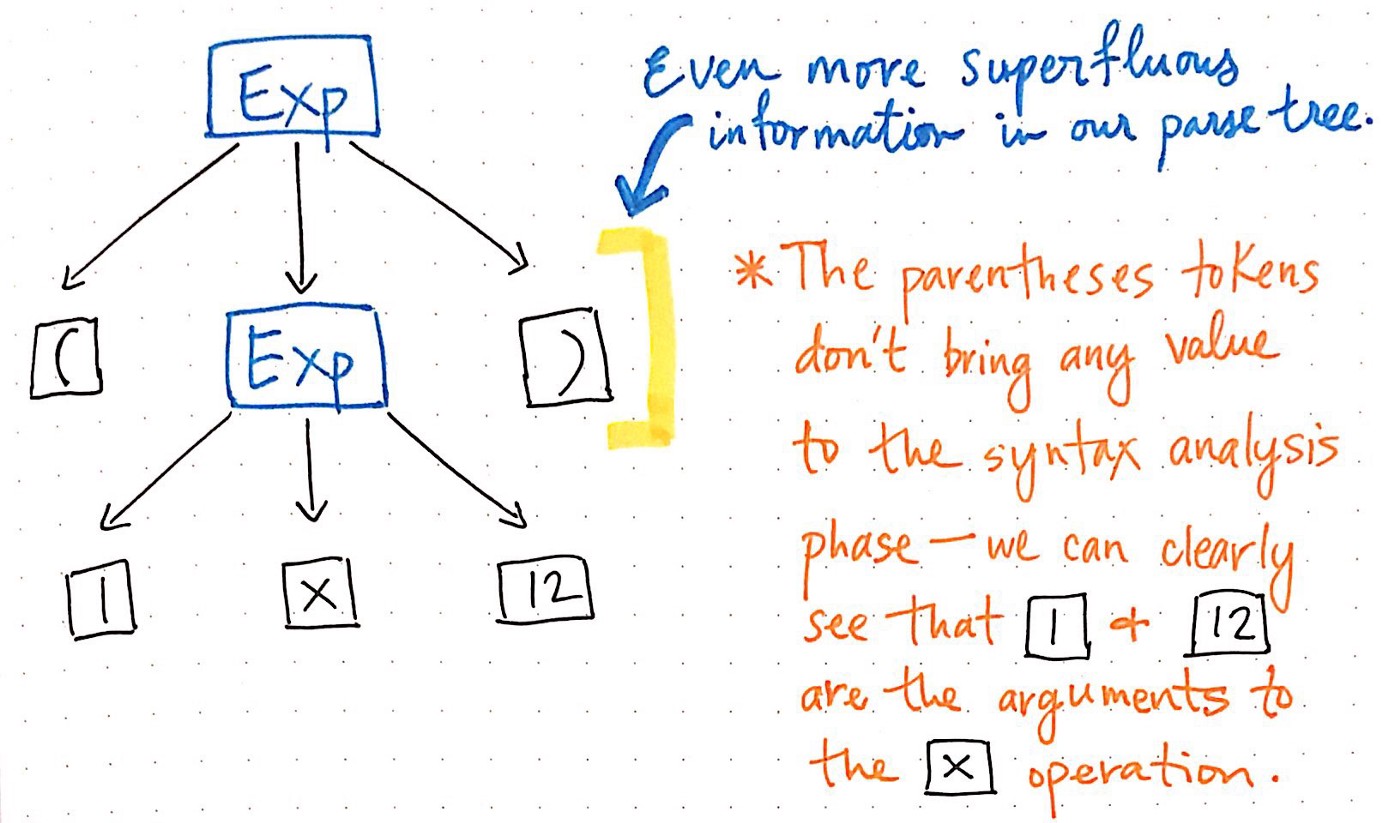
但是,一旦我们将树固定好,这些括号并没有真正帮助我们。 我们已经知道1和12是将传递给乘法x操作的参数,因此括号在这一点上告诉我们的不多。 实际上,我们可以进一步压缩解析树,并摆脱这些多余的叶节点。
一旦我们压缩并简化了语法分析树并摆脱了多余的语法“尘埃”,我们最终将获得一个看起来明显不同的结构。 实际上,该结构是我们新的和备受期待的朋友:抽象语法树。
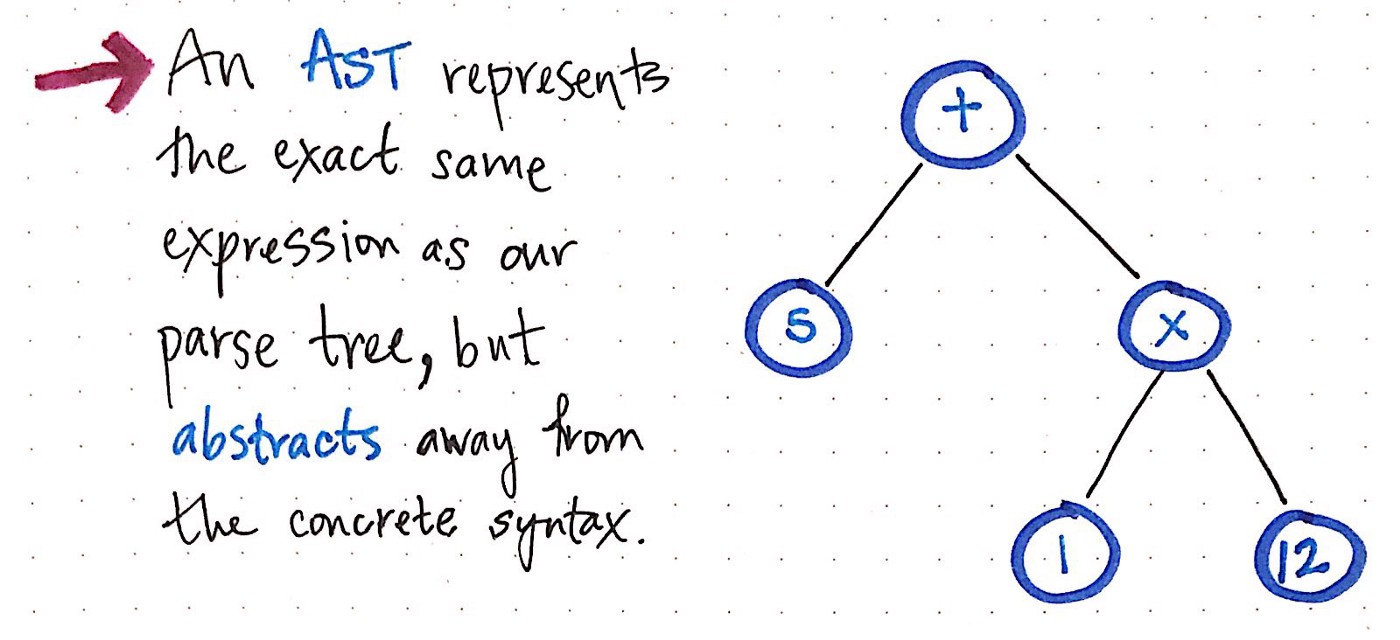
上图显示了与解析树完全相同的表达式:“5 +(1 x 12”。 不同之处在于,它已将表达式从具体语法中抽象出来。 由于没有必要,因此我们在此树中看不到任何括号()。 同样,我们也没有看到像Exp这样的非终端,因为我们已经弄清楚了“表达式”是什么,并且我们能够提取出对我们真正重要的* value *,例如, 数字“ 5”。
这恰好是AST和CST之间的区别因素。 我们知道,抽象语法树会忽略语法分析树包含的大量语法信息,并会跳过语法分析中使用的“额外内容”。 但是现在我们可以确切地看到如何发生!

现在,我们已经压缩了自己的解析树,我们将更好地掌握将AST与CST区别开来的某些模式。
有几种方法可以使抽象语法树与解析树在视觉上有所不同:
- AST绝不会包含语法细节,例如逗号,括号和分号(当然取决于语言)。
- AST将具有折叠的版本,否则将显示为单个\后继节点。 它永远不会包含带有单个子节点的“链”节点。
3.最后,所有运算符(例如+,-,x和/)将成为树中的内部(父)节点,而不是终止于解析树中的叶子。
从外观上看,AST总是比解析树更紧凑,因为按定义,它是解析树的压缩版本,语法细节较少。
那么,如果AST是解析树的压缩版本,那是有道理的,只有当我们有足够的东西来构建解析树时,我们才能真正创建抽象语法树!
实际上,这就是抽象语法树如何适合更大编译过程的方式。 AST与我们已经了解的解析树有直接联系,同时依赖于lexer在创建AST之前先完成其工作。

创建抽象语法树作为语法分析阶段的最终结果。 语法分析过程中,语法分析器作为主要的“字符”位于最前面,居中,它可能会或可能不会始终生成语法分析树或CST。 根据编译器本身及其设计方式,解析器可能会直接直接构建语法树或AST。 但是,解析器将始终生成AST作为其输出,无论它是否在两者之间创建了一个解析树,或者解析器可能需要进行多少次传递才能这样做。
AST的解剖
既然我们知道抽象语法树很重要(但不一定令人生畏!),我们就可以开始剖析它。 关于AST的构造方式,一个有趣的方面与该树的节点有关。
下图举例说明了抽象语法树中单个节点的解剖结构。
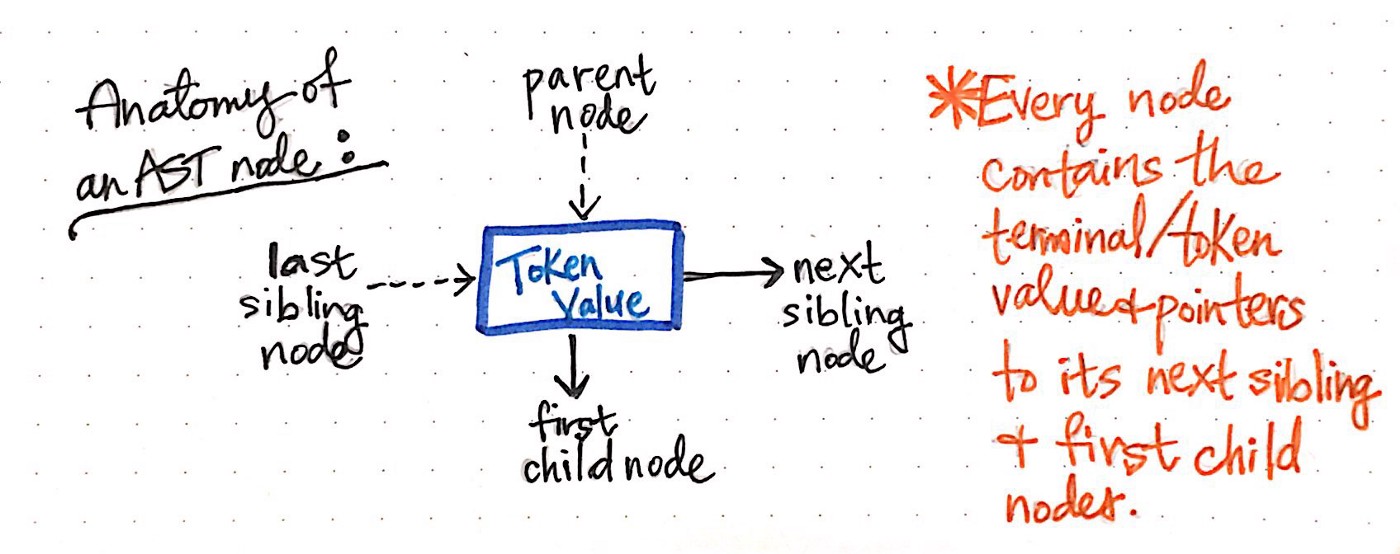
我们会注意到,该节点与之前见过的其他节点相似,因为它包含一些数据(“令牌”及其“值”)。 但是,它也包含一些非常具体的指针。 AST中的每个节点都包含对其 next 兄弟节点及其 first 子节点的引用。
例如,我们的“ 5 +(1 x 12)”的简单表达式可以构建为AST的可视化插图,如下图所示。
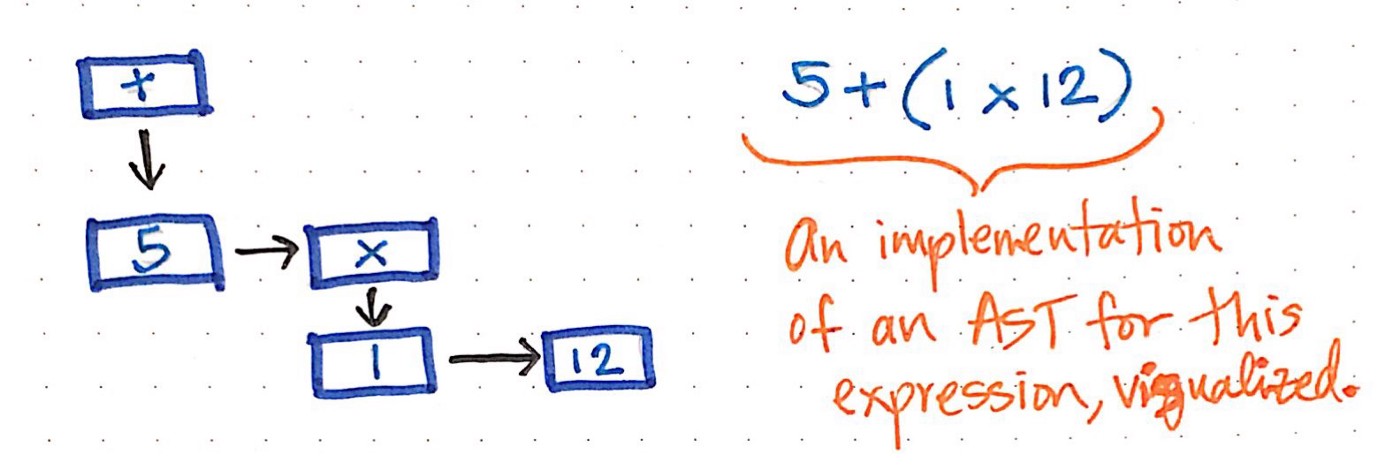
我们可以想象,读取,遍历或“解释”此AST可能是从树的最低层开始,然后逐步返回以建立一个值或在最后返回“结果”。
它还有助于查看解析器输出的编码版本,以帮助补充我们的可视化效果。 我们可以依靠各种工具并使用预先存在的解析器,以快速查看示例在通过解析器运行时表达式的外观。 以下是我们的源文本“ 5 +(1 * 12)”的示例,它贯穿Esprima,ECMAScript解析器及其生成的抽象语法树,随后是其不同标记的列表
使用JavaScript对我们的AST表达式进行代码可视化。
以这种格式,如果我们查看嵌套的对象,便可以看到树的嵌套。 我们会注意到,包含“ 1”和“ 12”的值分别是父操作“ ”的“ left”和“ right”子代。 我们还将看到乘法运算(*)构成了整个表达式本身的 right子树*,这就是为什么它被嵌套在较大的BinaryExpression对象中,位于键“ right”之下的原因。 类似地,“5” 的值是较大的“ BinaryExpression”对象的单个““ left””子代。

然而,抽象语法树最令人着迷的方面是这样的事实:即使它们是如此紧凑和简洁,它们也不总是容易尝试构建的简单数据结构。实际上,根据解析器处理的语言,构建AST可能会非常复杂!
大多数解析器通常会构造一个解析树(CST),然后将其转换为AST格式,因为有时这可能会更容易-尽管这意味着需要更多步骤,并且通常来说,从源文本传递更多内容。解析器知道要解析的语言的语法后,构建CST实际上非常容易。它不需要做任何复杂的工作来弄清楚令牌是否“重要”;取而代之的是,它仅按照其看到的顺序完全获取它所看到的内容,然后将它们全部吐出到树上。
另一方面,有些解析器将尝试以单个步骤完成所有这些操作,直接跳到构造抽象语法树。
直接建立AST可能会很棘手,因为解析器不仅必须找到标记并正确表示它们,而且还要确定哪些标记对我们很重要,哪些标记对我们不重要。
在编译器设计中,由于多个原因,AST最终变得非常重要。 是的,构造起来可能很棘手(并且可能很容易弄乱),但是,这是词法分析和语法分析阶段相结合的最后结果! 词法分析和语法分析阶段通常共同称为编译器的“分析阶段”或“前端”。

我们可以将抽象语法树视为编译器前端/终端的“最终项目”。 这是最重要的部分,因为这是前端必须展现的最后一件事。 此技术术语称为中间代码表示 或 IR ,因为它成为最终由编译器用来表示源文本的数据结构。
抽象语法树是IR的最常见形式,但有时也是最容易被误解的形式。 但是,既然我们对它的了解有所提高,我们就可以开始改变对这种可怕结构的看法! 希望现在对我们的威胁有所减轻。
原文地址:
https://medium.com/basecs/leveling-up-ones-parsing-game-with-asts-d7a6fc2400ff

 浙公网安备 33010602011771号
浙公网安备 33010602011771号