强化学习的几个主要方法(策略梯度、PPO、REINFORCE实现等)
本笔记有大量参考蘑菇书EasyRL https://datawhalechina.github.io/easy-rl/#/ 包括其配图和部分文本。
1. 基本概念
1.1 基本流程
强化学习是一种学习框架,其中智能体(Agent) 通过与 环境(Environment) 的交互,在每一步从环境中接收状态(State)和奖励(Reward),并通过选择行动(Action)来学习最优策略(Policy),以最大化其累计奖励。
换句话说,强化学习是让智能体找到一种行为策略,使得它在长期内获得的奖励总和(通常是期望值)最大化。

图中的每个元素代表以下含义:
- Agent(智能体):这是我们的学习者,它会根据当前的状态(State)做出一个动作(Action)。
- Environment(环境):这是智能体所处的外部世界,它会根据智能体的动作,给出相应的反馈:
- Reward(奖励):智能体执行动作后,环境会给出一个数值表示的奖励。正奖励表示动作的好坏,负奖励表示动作的坏处。
- Next State(下一个状态):执行动作后,环境的状态会发生变化,进入下一个状态。
- State(状态):环境在某个时刻的具体情况,比如游戏中的分数、机器人的位置等。
- Action(动作):智能体可以采取的各种行为,比如向左走、开火等。
1.2 马尔可夫过程
马尔科夫性质:一个随机过程的下一个状态只取决于当前状态,而与过去的状态无关。即:
马尔可夫性质也可以描述为给定当前状态时,将来的状态与过去状态是条件独立的。如果某一个过程满足马尔可夫性质,那么未来的转移与过去的是独立的,它只取决于现在。马尔可夫性质是所有马尔可夫过程的基础。
也就是说,满足以下关系,其中\(h_t = \{ s_1, s_2, s_3, \ldots, s_t \}\),\(h_t\)包含了之前所有状态
从当前 \(s_t\)转移到\(s_{t+1}\),它是直接就等于它之前所有的状态转移到 \(s_{t+1}\)。
马尔可夫链:离散时间的马尔可夫过程。其状态是有限的,例如:

可以用状态转移矩阵来描述状态转移过程
状态转移矩阵类似于条件概率(conditional probability),它表示当我们知道当前我们在状态 \(s_t\) 时,到达下面所有状态的概率。所以它的每一行描述的是从一个节点到达所有其他节点的概率。
1.3 马尔可夫奖励过程
马尔可夫链加上奖励函数。在马尔可夫奖励过程中,状态转移矩阵和状态都与马尔可夫链一样,只是多了奖励函数(reward function)。在强化学习中我们不知要关注过程,还要关注在过程中每一步所能获得到的奖励。
这里我们进一步定义一些概念。范围(horizon) 是指一个回合的长度(每个回合最大的时间步数),它是由有限个步数决定的。 回报(return)可以定义为奖励的逐步叠加,假设时刻\(t\)后的奖励序列为\(r_{t+1},r_{t+2},r_{t+3},⋯\),则回报为
回报(return)\(G_t\)可以表示为从时刻t开始直到回合结束获得的所有奖励的折扣总和:
其中,γ∈[0, 1]为折扣因子。随着时间的推移,未来的奖励会打折扣,表示我们更看重当前的奖励。
当我们有了回报的概念后,就可以定义状态价值函数(state-value function)V(s)。状态价值函数表示从状态s出发,按照当前策略一直执行下去,直到回合结束,所能获得的期望回报:
其中,\(G_t\)是之前定义的折扣回报(discounted return)。\(R(s)\)是奖励函数,我们对\(G_t\)取了一个期望,期望就是从这个状态开始,我们可能获得多大的价值。所以期望也可以看成未来可能获得奖励的当前价值的表现,就是当我们进入某一个状态后,我们现在有多大的价值。
这些话说的有点拗口,通俗来说就是\(G\)表示当下即时奖励和所有持久奖励等一切奖励的加权和,它是相对与一个序列中的一个状态节点来评估的,而价值函数\(V(s)\)是对某一个状态来评估而,把这个状态从序列中抽象出来了。
贝尔曼方程
一种快速求\(V(s)\)的方法。
1.4 马尔可夫决策过程
马尔可夫决策过程(MDP) = 马尔可夫奖励(MRP) + 智能体动作因素
MDP 的目标是找到一个最优策略 π,使得智能体在给定状态下选择最优的动作,从而最大化长期累积的折扣奖励。
状态价值函数:
动作价值状态函数:
\(A_t\)表示t时刻的动作,\(Q\)函数相对上面的\(V\)函数来说多考虑进去了一个动作的因素,而不只是单纯的状态。
马尔可夫决策的贝尔曼方程
2. REINFORCE
2.1 策略梯度算法
由于REINFORCE是最简单的侧率梯度算法,所以这里先介绍策略梯度算法
强化学习有 3 个组成部分:演员(actor)、环境和奖励函数。显然我们能控制的只有演员,环境和奖励函数是客观存在的。智能体玩视频游戏时,演员负责操控游戏的摇杆, 比如向左、向右、开火等操作;环境就是游戏的主机,负责控制游戏的画面、负责控制怪兽的移动等;奖励函数就是当我们做什么事情、发生什么状况的时候,可以得到多少分数, 比如打败一只怪兽得到 20 分等。在强化学习里,环境与奖励函数不是我们可以控制的,它们是在开始学习之前给定的。我们唯一需要做的就是调整演员里面的策略,使得演员可以得到最大的奖励。演员里面的策略决定了演员的动作,即给定一个输入,它会输出演员现在应该要执行的动作。
在下面的例子中,我们会用一个神经网络来当做演员,把环境输入,由神经网络给出动作。例如玩一个走格子的游戏,游戏规则如下,创建一个\(n \times n\)的棋盘,旗子在\((0, 0)\)处,要到达\((n, n)\)处,并用最少的步数走到。(也可以为了增加难度在中间设置一点障碍)棋子有四种动作,分别是“上、下、左、右”。
有四个动作,所以神经网络有四个输出,根据四个输出的概率进行采样选择下一步的动作。
智能体的每一步动作都会有一个奖励,为了让他能尽快走到终点,因此它每走到一个格子,除非那个格子是终点,我们就把那个格子的奖励设置为-1,终点的奖励可以设置为10,中间也可以设置障碍,例如将某个点的奖励设置为-100,这样就让模型学会避开这个点。
我们的游戏过程应该是这样的:

在一场游戏里面,我们把环境输出的\(s\)与演员输出的动作 \(a\) 全部组合起来,就是一个轨迹
给定演员的参数 \(θ\)(就是提到的神经网络的参数),我们可以计算某个轨迹\(\tau\)发生的概率为
这个计算是一步一步的,并不是并行的。其中\(p(s_{t+1} \mid s_t, a_t)\)意思是在环境为\(s_t\), 演员采取动作\(a_t\)的情况下环境变成\(s_{t+1}\)的概率。
那既然每一把游戏都是一个轨迹\(\tau\),每一把游戏都会有一个得分,这个得分按照我之前设定的规则应该是每个动作的回报\(G_t\)然后求和,由于整局游戏我已经玩完了,所以之后的动作是什么奖励是什么我也知道,因此我们能算出这个\(G_t\)。
我们把这局游戏每一步走完之后的\(G_t\)都存下来,如果这个\(G_t\)大于零,就说明这个动作有好处,可以增大采样采到这个动作的概率,注意,增加的是\(p_{\theta}(a_t|s_t)\)的概率,而不是\(p_{\theta}(a_t)\)的值,需要联系环境来考虑问题。就跟人斗地主一样,你是农民,你的队友手里只剩下两张王了,这个时候最好的决策就是将自己手里的炸弹打出来增加奖励。你出炸弹的概率就几乎是百分之百,\(p(出炸弹 \mid 队友手里只剩下两张王了) = 0.99\),而在别的情况下你出炸弹的概率就没必要这么高,毕竟很少有人开局就出炸弹。所以模型要提高的是\(p(出炸弹 \mid 队友手里只剩下两张王了)\)的值,而不是\(p(出炸弹)\)。这个\(G_t\)暂时不会用到,后面会用到。
在强化学习里面,除了环境与演员以外,还有奖励函数。如下图所示,奖励函数根据在某一个状态采取的某一个动作决定这个动作可以得到的分数。对奖励函数输入\(s_1, a_1\),它会输出\(r_1\),输入 \(s_2, a_2\),它会输出\(r_2\)。 我们把轨迹所有的奖励 \(r\)都加起来,就得到了\(R(\tau)\),其代表某一个轨迹 \(\tau\)的奖励。

那一把游戏能不能衡量一个演员(智能体)的能力呢,可能不行,因为你有可能是蒙的,那我们如何评价一个演员的能力呢,多玩几次,求期望:
那么这个\(\bar{R}_{\theta}\)就是我们要优化的目标了。也可以表达成这样:
因为我们要让奖励越大越好,所以可以使用梯度上升(gradient ascent)来最大化期望奖励。要进行梯度上升,我们先要计算期望奖励 \(\bar{R}_{\theta}\)的梯度。我们对\(\bar{R}_{\theta}\)做梯度运算。
对\(\theta\)求偏导:
由于\(\nabla log_a(f(x)) = \frac{\nabla f(x)}{f(x)lna}\),\(lna\)是常数,可以忽略(直接将底数看做是e更好理解下面的公式):
带入\(\nabla \bar{R}_{\theta}\)得:
由于轨迹是采不完的,因此\(\mathbb{E}_{\tau \sim p_{\theta}(\tau)}\)无法计算,我们只能以部分估计总体,这也是统计学的精髓,多采几次样,这里假设采样\(N\)个\(\tau\)并计算每一个\(\tau\)的\(\left[ R(\tau) \nabla \log p_{\theta}(\tau) \right]\)值,再将其求和取平均,用来近似\(\mathbb{E}_{\tau \sim p_{\theta}(\tau)}\)。
那如何处理\(\log p_{\theta}(\tau)\)呢?
第二部中有一些与\(\theta\)无关的项直接被求偏导变成零了。因为\(p\)表示的是根据动作和前面的场景生成的场景为\(s_{t+1}\)的概率,与演员无关。
由上式和之前分析的由部分代替总体的思想一起带入\(\nabla \bar{R}_{\theta}\)可得:
那我们就可以将\(\nabla \bar{R}_{\theta}\)当做损失函数:
既然有了损失函数,那就可以直接套用深度学习神经网络那一套东西,更新参数:
那么网络的训练步骤就非常的简单:
采集数据 ——> 更新参数——>采集数据——>……
值得注意的是采集到的数据只会用一次就丢掉,这显然是一个可以优化的点,之后在PPO算法中会对其进行优化。

2.2 策略梯度算法的一些实现技巧
2.2.1 基线
如果奖励一直是正的,\(\nabla \bar{R}_{\theta}\)就会一直是正的,那概率就只会增加不会减少,什么意思呢?
如图所示:

在某一个状态有 3 个动作 a、b、c可以执行,b的奖励最大,c的奖励最小。但是如果采样没有采到a,只采到了b、c,那么b、c的概率就会增大(因为奖励是正的),因为a、b、c的概率和是1,b、c概率增大了,a的概率就会减小,这显然是不科学的。
因此我们可以引入一个基线,就是把奖励统一减去\(b\),让奖励有正有负,即:
2.2.2 分配合适的分数
观察损失函数:
在同一场游戏里面,在同一场游戏里面,所有的状态-动作对就使用同样的奖励项进行加权。
这显然是不公平的例如:
假设游戏都很短,只有 3 ~ 4 个交互,在 \(s_a\) 执行 \(a_1\)得到 5 分,在\(s_b\)执行\(a_2\)得到 0 分,在\(s_c\)执行\(a_3\)得到 −2 分。 整场游戏下来,我们得到 +3 分,那我们得到 +3 分 代表在\(s_b\)执行\(a_2\) 是好的吗? 这并不一定代表在\(s_b\)执行\(a_2\)是好的。因为这个正的分数,主要来自在\(s_a\)执行了\(a_1\),与在\(s_b\)执行\(a_2\)是没有关系的,也许在\(s_b\)执行\(a_2\)反而是不好的, 因为它导致我们接下来会进入\(s_c\),执行\(a_3\)被扣分。所以整场游戏得到的结果是好的, 并不代表每一个动作都是好的。

理想情况下这种情况不会发生,只要采样足够多,多次遇到\((s_a, a_1)\)的情况,我们就能通过梯度更新来合理评估它的概率,但是问题是采样成本很高,采样那么多次不太现实,因此我们可以为每个状态-动作对分配合理的分数,要让大家知道它合理的贡献。
我们之前谈到过\(G_t\)
它就能很好的反应每个状态的价值即:
说明:
事实上\(b\)通常是一个网络估计出来的,它是一个网络的输出。我们把\(R-b\)这一项称为优势函数(advantage function), 用\(A^{\theta}(s_t, a_t)\)来代表优势函数。优势函数取决于\(s\)和\(a\),我们就是要计算在某个状态\(s\)采取某个动作\(a\)的时候,优势函数的值。在计算优势函数值时,我们要计算\(\sum_{t'=t}^{T_n} r_{t'}^n\),需要有一个模型与环境交互,才能知道接下来得到的奖励。优势函数\(A^{\theta}(s_t, a_t)\)的上标是\(\theta\),\(\theta\) 代表用模型\(\theta\)与环境交互。从时刻\(t\)开始到游戏结束为止,所有\(r\)的加和减去\(b\),这就是优势函数。优势函数的意义是,假设我们在某一个状态\(s_t\)执行某一个动作\(a_t\),相较于其他可能的动作,\(a_t\)有多好。优势函数在意的不是绝对的好,而是相对的好,即相对优势(relative advantage)。因为在优势函数中,我们会减去一个基线\(b\),所以这个动作是相对的好,不是绝对的好。\(A^{\theta}(s_t, a_t)\)通常可以由一个网络估计出来,这个网络称为评论员(critic)。
2.3 REINFORCE算法实现
由于在游戏中我的策略是每个格子如果不是终点,奖励分数就是-1,因此无需使用基线,但是代码中使用了“分配合适分数”方法,所有函数作用代码中有详细注释,因此不再赘述。
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 环境定义
class GridWorldEnv:
def __init__(self, size=5):
# 初始化网格世界环境
self.size = size # 网格的大小
self.state = (0, 0) # 初始状态
self.goal = (size - 1, size - 1) # 目标状态
self.actions = ['up', 'down', 'left', 'right'] # 可用的动作
self.action_space = len(self.actions) # 动作空间的大小
def reset(self):
# 重置环境到初始状态
self.state = (0, 0)
return self.state
def step(self, action):
# 根据动作更新状态,并返回新的状态、奖励和是否完成
x, y = self.state
if action == 0: # 向上
x = max(0, x - 1)
elif action == 1: # 向下
x = min(self.size - 1, x + 1)
elif action == 2: # 向左
y = max(0, y - 1)
elif action == 3: # 向右
y = min(self.size - 1, y + 1)
self.state = (x, y)
reward = -1 # 默认奖励
if x == 2 and y != 2:
reward = -10
done = self.state == self.goal # 检查是否到达目标
if done:
reward = 10 # 到达目标的奖励
return self.state, reward, done
def render(self):
# 渲染当前状态的网格世界
grid = np.zeros((self.size, self.size)) # 创建一个全零的网格
x, y = self.state
grid[x, y] = 1 # 将当前状态的位置设为1
print(grid)
# 策略网络
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
# 初始化策略网络
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, 24) # 第一层全连接层
self.fc2 = nn.Linear(24, 128) # 第二层全连接层
self.fc3 = nn.Linear(128, output_dim) # 第三层全连接层
self.relu = nn.ReLU() # ReLU激活函数
self.softmax = nn.Softmax(dim=-1) # Softmax输出层
def forward(self, x):
# 前向传播
x = self.relu(self.fc1(x)) # 第一层激活
x = self.relu(self.fc2(x)) # 第二层激活
x = self.softmax(self.relu(self.fc3(x))) # 第三层激活
return x
# REINFORCE算法
class REINFORCE:
def __init__(self, state_space, action_space, learning_rate=0.01, gamma=0.99):
# 初始化REINFORCE算法
self.policy_network = PolicyNetwork(state_space, action_space) # 策略网络
self.optimizer = optim.Adam(self.policy_network.parameters(), lr=learning_rate) # Adam优化器
self.gamma = gamma # 折扣因子
def choose_action(self, state):
# 根据状态选择动作
state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) # 将状态转换为张量
action_probs = self.policy_network(state).detach().numpy()[0] # 获取动作概率
action = np.random.choice(len(action_probs), p=action_probs) # 根据概率选择动作
return action
def compute_discounted_rewards(self, rewards):
# 计算折扣奖励
discounted_rewards = np.zeros_like(rewards, dtype=np.float32) # 初始化折扣奖励
cumulative = 0
for i in reversed(range(len(rewards))):
cumulative = cumulative * self.gamma + rewards[i] # 计算累计折扣奖励
discounted_rewards[i] = cumulative
return discounted_rewards
def train(self, states, actions, rewards):
# 训练策略网络
discounted_rewards = self.compute_discounted_rewards(rewards) # 计算折扣奖励
# 归一化奖励
discounted_rewards = (discounted_rewards - np.mean(discounted_rewards)) / (np.std(discounted_rewards) + 1e-8)
discounted_rewards = torch.tensor(discounted_rewards, dtype=torch.float32)
states = torch.tensor(states, dtype=torch.float32) # 将状态转换为张量
actions = torch.tensor(actions, dtype=torch.long) # 将动作转换为张量
# 计算损失
log_probs = torch.log(self.policy_network(states)) # 计算对数概率
selected_log_probs = log_probs[range(len(actions)), actions] # 选择执行动作的对数概率
loss = -torch.mean(selected_log_probs * discounted_rewards) # 计算损失
# 优化网络
self.optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播
self.optimizer.step() # 更新参数
# 主程序
def main():
env = GridWorldEnv(size=5) # 创建网格世界环境
agent = REINFORCE(state_space=10, action_space=4, learning_rate=0.01) # 创建REINFORCE智能体
episodes = 1000 # 训练回合数
reward_history = [] # 奖励历史
state = env.reset() # 重置环境
env.render() # 渲染初始状态
for episode in range(episodes):
state = env.reset() # 重置环境
states, actions, rewards = [], [], [] # 初始化状态、动作和奖励列表
done = False
while not done:
# 状态转换为独热向量
state_onehot = np.eye(env.size)[state[0]].tolist() + np.eye(env.size)[state[1]].tolist()
action = agent.choose_action(state_onehot) # 选择动作
next_state, reward, done = env.step(action) # 执行动作
states.append(state_onehot) # 记录状态
actions.append(action) # 记录动作
rewards.append(reward) # 记录奖励
state = next_state # 更新状态
agent.train(states, actions, rewards) # 训练智能体
reward_history.append(sum(rewards)) # 记录总奖励
if episode % 100 == 0:
print(f"Episode {episode}, Total Reward: {sum(rewards)}") # 每100回合打印一次总奖励
# 绘制奖励曲线
plt.plot(reward_history)
plt.xlabel("Episodes")
plt.ylabel("Total Reward")
plt.show()
if __name__ == "__main__":
main()
3. A2C算法
3.1 策略梯度的一些缺陷
策略梯度算法在理想情况下,在采样次数足够多的情况下效果是能很不错的,但是当采样不够时就会出现一些问题,例如\(G_t\)的取值是很不稳定的,下图可以形象说明:

由于\(G_t\)的取值不稳定,所以\((s_t, a_t)\)更新也不稳定。
3.2 DQN中的一些概念
由于\(G\)的值有点太不稳定太玄学了,因此我们可以想办法去用一个神经网络去预测在\(s\)状态下采取行动\(a\)时对应的\(G\)期望值,之后再训练中我们就直接用这个期望值去替代采样的值。为了完成这个目的,我们可以使用基于价值的方法深度Q网络,深度Q网络有两种函数,也就是两种评论员,他们分别是\(V_{\pi}(s)\)和\(Q_{\pi}(s,a)\),\(V_{\pi}(s)\)是指假设演员的策略是\({\pi}\),使用\({\pi}\)与环境交互,当智能体看到状态\(s\)时,接下来累积奖励的期望值是多少。\(Q_{\pi}(s,a)\)是指把\(s\)与\(a\)当作输入,它表示在状态\(s\)采取动作\(a\),接下来用策略\({\pi}\)与环境交互,累积奖励的期望值是多少。\(V_{\pi}(s)\)接收输入\(s\),输出一个标量。\(Q_{\pi}(s,a)\)接收输入\(s\),它会给每一个\(s\)都分配一个 \(Q\)值。
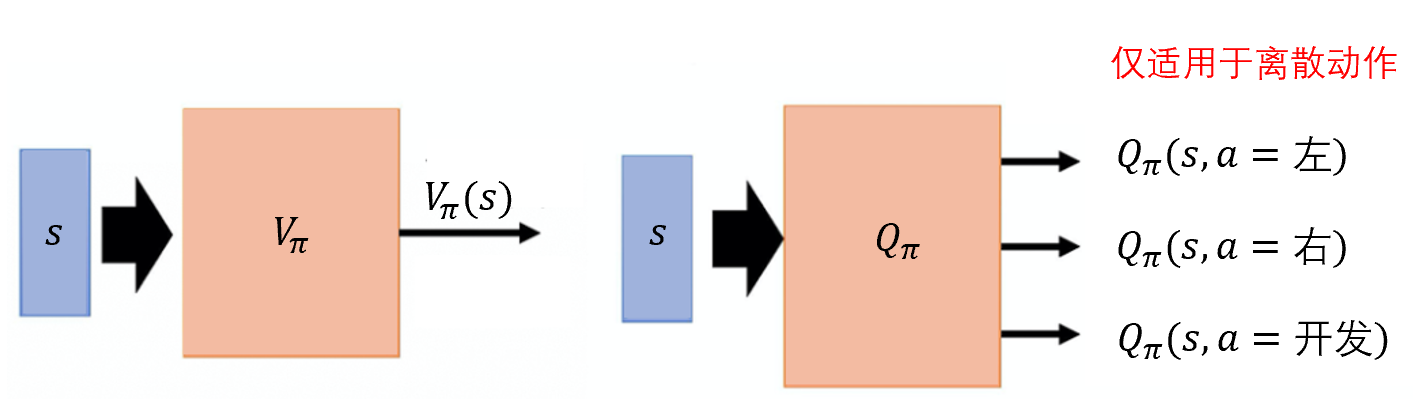
有了这两个函数,我们可以用这两个函数去替换原来的梯度公式:
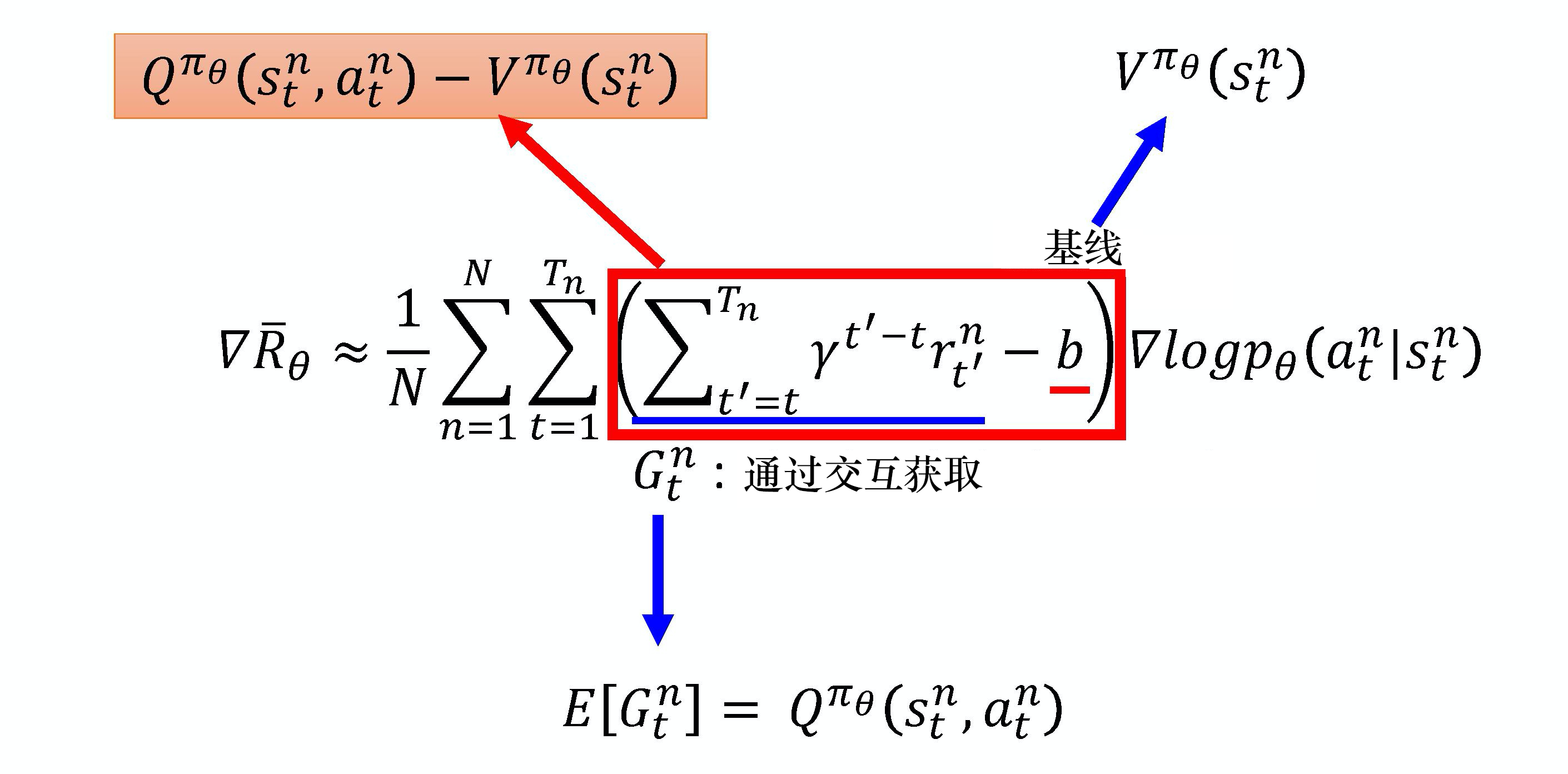
又出现一个问题,神经网络本来就不稳定,现在还要估计两个神经网络,Q网络和V网络,那岂不是更不稳定,估不准的概率岂不是就翻倍了,那就得想点办法只估计一个网络,事实上,在演员-评论员算法中,我们可以只估计网络 V,并利用\(V\)的值来表示\(Q\)的值,\(Q_{\pi}(s_t^n, a_t^n)\)可以写成$ r_t^n + V_{\pi}(s_{t+1}^n) $的期望值,即:
在状态\(s\)采取动作\(a\),我们会得到奖励\(r\),进入状态\(s_{t+1}\)。但是我们会得到什么样的奖励\(r\),进入什么样的状态\(s_{t+1}\),这件事本身是有随机性的。所以要把$ r_t^n + V_{\pi}(s_{t+1}^n) $取期望值才会等于Q函数的值。但我们现在把取期望值去掉,即:
即:Q函数与V函数的差值可以变成\(r_t^n + V_{\pi}(s_{t+1}^n) - V_{\pi}(s_t^n)\)
至于究竟为什么可以去掉期望值,也没有什么很强有力的数学解释,只是研究人员发现这么做效果不错,其他方法效果没这个好,大家伙就都用这个方法了,都直接把期望去掉了。
推了半天,得到一个\(r_t^n + V_{\pi}(s_{t+1}^n) - V_{\pi}(s_t^n)\),这个公式就是时序差分误差(TD-error),它代替了我们之前提到的优势函数,就是替代了\(A^{\theta}(s_t, a_t)\)。
那么\(\nabla \bar{R}_{\theta}\)就变成了:
算法流程:
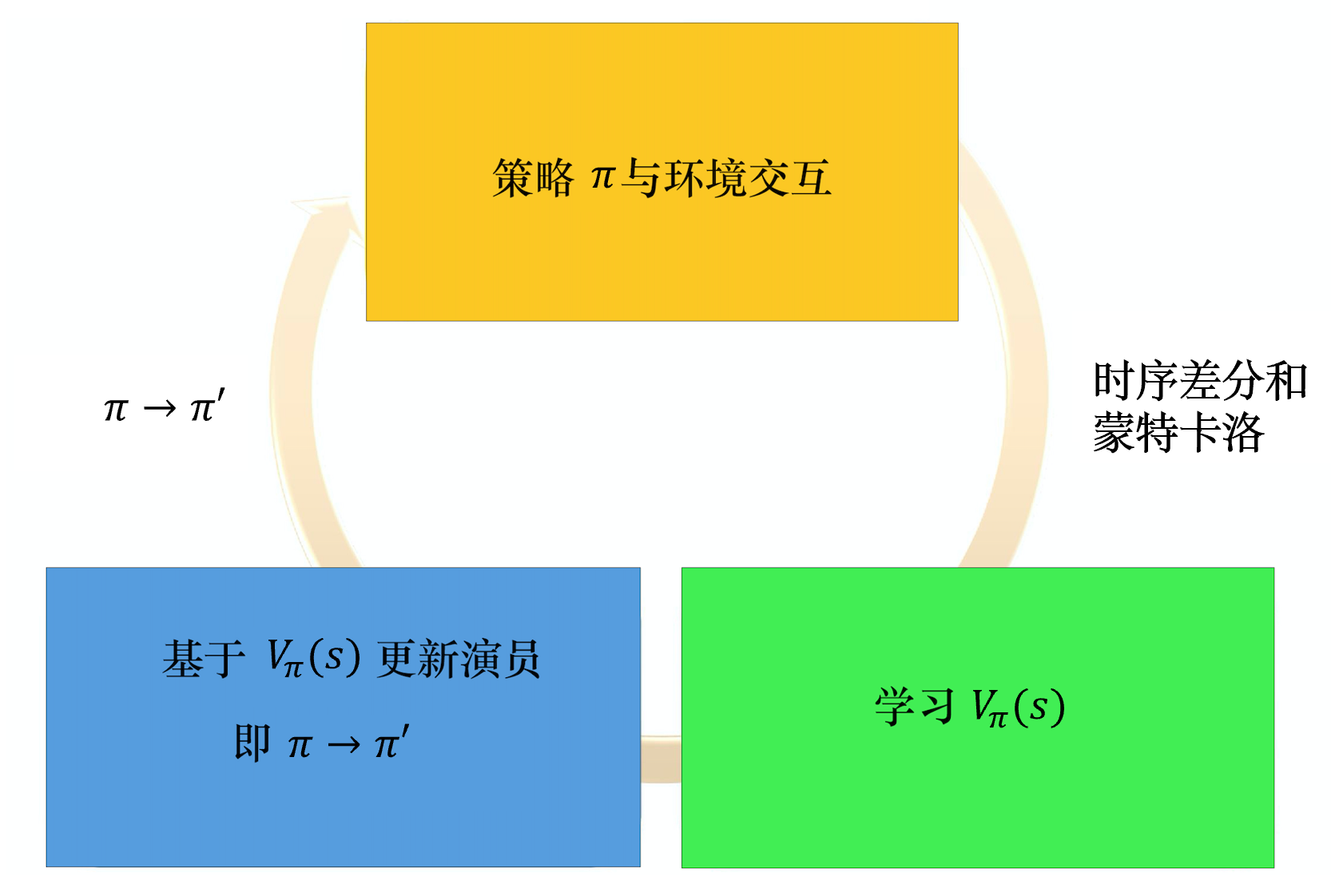
3.3 Actor网络和Critic网络的损失函数
讲了这么多,那么我们要训练两个网络,Actor网络和Critic网络,既然是训练这两个模型就需要损失函数,两个模型就需要两个损失函数,那他们分别是什么呢?
Actor网络的损失函数如下:
Critic网络损失函数如下:
有了损失函数又改如何求梯度算参数呢:
首先需要明白有两个网络,Actor网络和Critic网络,他们在上述公式中的体现是什么,时序差分误差\(\delta_t^n = r_t^n + V_{\pi}(s_{t+1}^n) - V_{\pi}(s_t^n)\),既然是误差,涉及到评估工作,因此V网络就是Critic网络,其网络参数并未在公式中标注,可以将其标注为\({\phi}\)。至于Actor网络,公式中已经标明过了,\({\pi}_{\theta}\)表示\(\pi\)这个策略网络的参数就是\(\theta\),因此求梯度也就很轻松。
Actor网络的梯度公式如下:
Critic网络的梯度公式如下:
3.4 A2C算法实现
实现优势演员-评论员算法的时候,有两个一定会用到的技巧。
第一个技巧是,我们需要估计两个网络:\(V\)网络和策略的网络(也就是演员)。评论员网络\(V_{\pi}(s)\)接收一个状态,输出一个标量。演员的策略\({\pi(s)}\)接收一个状态,如果动作是离散的,输出就是一个动作的分布。如果动作是连续的,输出就是一个连续的向量。
离散动作的例子如下,连续动作的情况也是一样的。输入一个状态,网络决定现在要采取哪一个动作。演员网络和评论员网络的输入都是\(s\),所以它们前面几个层(layer)是可以共享的。

第二个技巧是我们需要探索的机制。在演员-评论员算法中,有一个常见的探索的方法是对\({\pi}\)输出的分布设置一个约束。这个约束用于使分布的熵(entropy)不要太小,也就是希望不同的动作被采用的概率平均一些。这样在测试的时候,智能体才会多尝试各种不同的动作,才会把环境探索得比较好,从而得到比较好的结果。
这里运用了两个技巧,第二个技巧在Actor网络的损失函数上加了个正则项,因此Actor损失函数变成了这样:
代码中主要是以玩一个CartPole的游戏举例来实现的,游戏的具体玩法可以去网上搜到,大概就是一个平衡杆左右移动让杆子不倒的游戏。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 配置类,集中管理所有超参数
class Config:
def __init__(self):
# 神经网络结构参数
self.hidden_dim = 128 # 共享网络隐藏层维度
self.actor_hidden_dim = 64 # Actor网络隐藏层维度
self.critic_hidden_dim = 64 # Critic网络隐藏层维度
# 算法训练参数
self.lr = 0.001 # 学习率
self.gamma = 0.99 # 折扣因子,用于计算未来奖励的现值
self.entropy_coef = 0.01 # 熵系数,用于鼓励探索
self.value_loss_coef = 0.5 # 价值损失系数,平衡actor和critic损失
# 训练过程参数
self.max_episodes = 5000 # 最大训练回合数
self.max_steps = 500 # 每个回合的最大步数
# 其他设置
self.seed = 42 # 随机种子,确保实验可重复性
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备选择
self.rewards_history = [] # 用于存储每个episode的reward
# Actor-Critic网络结构
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, config):
super(ActorCritic, self).__init__()
# 共享特征提取层
self.common = nn.Sequential(
nn.Linear(state_dim, config.hidden_dim), # 状态到特征的映射
nn.ReLU() # 非线性激活函数
)
# Actor网络:决策策略
self.actor = nn.Sequential(
nn.Linear(config.hidden_dim, action_dim), # 特征到动作概率的映射
nn.Softmax(dim=-1) # 输出动作概率分布
)
# Critic网络:状态价值评估
self.critic = nn.Sequential(
nn.Linear(config.hidden_dim, 1) # 特征到状态价值的映射
)
def forward(self, state):
common_out = self.common(state) # 提取共享特征
policy = self.actor(common_out) # 计算动作概率
value = self.critic(common_out) # 估计状态价值
return policy, value
# A2C算法实现
class A2C:
def __init__(self, state_dim, action_dim, config):
self.config = config
self.model = ActorCritic(state_dim, action_dim, config) # 创建神经网络
self.optimizer = optim.Adam(self.model.parameters(), lr=config.lr) # Adam优化器
self.gamma = config.gamma # 折扣因子
def compute_loss(self, states, actions, rewards, dones, next_states):
# 数据预处理:转换为PyTorch张量
states = torch.FloatTensor(states)
next_states = torch.FloatTensor(next_states)
actions = torch.LongTensor(actions)
rewards = torch.FloatTensor(rewards)
dones = torch.FloatTensor(dones)
# 获取当前状态的策略和价值估计
policy, values = self.model(states)
_, next_values = self.model(next_states)
# 计算TD目标和优势函数
# TD目标 = 即时奖励 + 折扣因子 * 下一状态的价值 * (1-终止标志)
td_targets = rewards + self.gamma * next_values.squeeze(1) * (1 - dones)
# 优势函数 = TD目标 - 当前状态的价值估计
advantages = td_targets - values.squeeze(1)
# 计算策略(Actor)损失
action_probs = policy.gather(1, actions.unsqueeze(1)).squeeze(1)
# 计算策略熵,用于鼓励探索
entropy = -(policy * torch.log(policy + 1e-10)).sum(1).mean()
# Actor损失 = -(log策略 * 优势函数) - 熵系数 * 熵
actor_loss = -(torch.log(action_probs) * advantages.detach()).mean() - \
self.config.entropy_coef * entropy
# Critic损失 = 优势函数的平方误差
critic_loss = self.config.value_loss_coef * advantages.pow(2).mean()
# 总损失 = Actor损失 + Critic损失
return actor_loss + critic_loss
def update(self, states, actions, rewards, dones, next_states):
loss = self.compute_loss(states, actions, rewards, dones, next_states)
self.optimizer.zero_grad() # 清除之前的梯度
loss.backward() # 反向传播计算梯度
self.optimizer.step() # 更新网络参数
# 训练主循环
def train_a2c():
config = Config() # 创建配置对象
# 设置随机种子确保可重复性
torch.manual_seed(config.seed)
np.random.seed(config.seed)
# 创建CartPole环境
env = gym.make("CartPole-v1")
state_dim = env.observation_space.shape[0] # 状态空间维度
action_dim = env.action_space.n # 动作空间维度
# 创建A2C智能体
agent = A2C(state_dim, action_dim, config)
# 训练循环
for episode in range(config.max_episodes):
state, _ = env.reset() # 重置环境
# 初始化回合数据存储
states, actions, rewards, next_states, dones = [], [], [], [], []
total_reward = 0 # 记录回合总奖励
episode_reward = 0 # 记录每个episode的reward
# 单回合交互循环
for step in range(config.max_steps):
# 将状态转换为张量并添加批次维度
state_tensor = torch.FloatTensor(state).unsqueeze(0)
# 获取动作概率分布
policy, _ = agent.model(state_tensor)
# 从概率分布中采样动作
action = torch.multinomial(policy, 1).item()
# 执行动作
next_state, reward, done, _, _ = env.step(action)
# 存储交互数据
states.append(state)
actions.append(action)
rewards.append(reward)
dones.append(done)
next_states.append(next_state)
total_reward += reward # 累积奖励
episode_reward += reward # 累积每个episode的reward
state = next_state # 更新状态
if done: # 如果回合结束,跳出循环
break
# 回合结束后更新模型
agent.update(states, actions, rewards, dones, next_states)
print(f"Episode {episode + 1}, Total Reward: {total_reward}")
# 记录每个episode的reward
config.rewards_history.append(episode_reward)
# 如果达到目标奖励,提前结束训练
if total_reward >= 500:
print("Solved!")
break
# 绘制训练奖励曲线
plot_rewards(config.rewards_history)
env.close() # 关闭环境
# 绘图函数
def plot_rewards(rewards):
plt.figure(figsize=(10,5))
plt.plot(rewards)
plt.title('Training Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.grid()
plt.show()
# 程序入口
if __name__ == "__main__":
train_a2c()
设置的reward到达500就提前结束训练,结果图:

4. PPO算法
近端策略优化(proximal policy optimization,PPO)算法是OpenAI的默认强化学习算法,在RLHF中也用到了这个算法,说明这个算法还是很强的,那它到底解决了一个什么问题呢?
先介绍两个概念,同策略学习(On-Policy Learning)和异策略学习(Off-Policy Learning),在强化学习里面,要学习的是一个智能体。如果要学习的智能体和与环境交互的智能体是相同的,我们称之为同策略。如果要学习的智能体和与环境交互的智能体不是相同的,我们称之为异策略。
PPO的主要解决的问题是什么呢?
无论是A2C算法还是REINFOCE算法,都有一个问题,数据在采样完成,更新模型一次之后就丢弃了,前文不止一次强调过,数据采样是很昂贵且费事的,只用一次就丢显然是不合理的,但是数据用一次之后模型已经更新了,旧的数据是旧的模型产生的不能用来更新新的模型,PPO就是用来解决这个问题的。
它的思路是这样的,我们用梯度下降去降低损失,由于学习率的问题,我们可能方向对了,但是步子迈小了,所以用旧数据再去更新一次,再迈一步,但是直觉告诉我们不能一直用旧数据,因为模型参数多迭代几次之后可能跟产生旧数据的旧模型完全不一样了,PPO最大的贡献就在于它告诉模型什么时候旧数据不能再用了,定量分析了新模型与旧模型的差距。
这里先介绍重要性采样的概念。
4.1 重要性采样
假设我们有一个函数 \(f(x)\),要计算从分布 \(p\) 采样 \(x\),再把 \(x\) 代入 \(f\),得到 \(f(x)\)。我们该怎么计算 \(f(x)\) 的期望值呢?假设我们不能对分布 \(p\) 做积分,但可以从分布 \(p\) 采样一些数据 \(x^i\)。把 \(x^i\) 代入 \(f(x)\),取它的平均值,就可以近似 \(f(x)\) 的期望值。
现在有另外一个问题,假设我们不能从分布 \(p\) 采样数据,只能从另外一个分布 \(q\) 采样数据 \(x^i\),\(q\) 可以是任何分布。如果我们从 \(q\) 采样 \(x^i\),就不能使用刚刚的方法。因为刚刚的方法需要从\(p\)里面采样。
但是我硬要从\(q\)里面采,神奇的数学会给出解决方案:
我们就可以写成对\(q\)里面所采样出来的 x 取期望值。我们从\(q\)里面采样\(x\),再计算 \(f(x){\frac{p(x)}{q(x)}}\),再取期望值。所以就算我们不能从\(p\)里面采样数据,但只要能从\(q\)里面采样数据,就可以计算从\(p\)采样\(x\)代入\(f\)以后的期望值。
其中\(f(x){\frac{p(x)}{q(x)}}\)称作重要性权重。它主要用来修正两个分布之间的差异,但是它也不是万能的,通过上面的式子我们能看出它只能保证两种采样方法的期望相同,没说方差相同,如果方差巨大的话,也达不到我们想要的效果,两个分布的方差如下(\(\text{Var}[X] = \mathbb{E}[X^2] - \left(\mathbb{E}[X]\right)^2\))
可以看到对\(q\)分布采样的方差比对\(p\)分布采样的方差多乘了一个\(\frac{p(x)}{q(x)}\),所以就一件事,\(p\)和\(q\)的分布要尽量相似用这个方法才能有一个很好的效果。下面举个例子来说明这一点:

例如,当 \(p(x)\) 和 \(q(x)\) 差距很大时,就会有问题。如图所示,假设蓝线是 \(p(x)\) 的分布,绿线是 \(q(x)\) 的分布,红线是 \(f(x)\)。如果我们要计算 \(f(x)\) 的期望值,从分布 \(p(x)\) 做采样,显然 \(\mathbb E_{x \sim p}[f(x)]\) 是负的。这是因为左边区域 \(p(x)\) 的概率很高,所以采样会到这个区域,而 \(f(x)\) 在这个区域是负的,所以理论上这一项算出来会是负的。
接下来我们改成从 \(q(x)\) 采样,因为 \(q(x)\) 在右边区域的概率比较高,所以如果我们的采样点不够多,可能只会采样到右侧。如果我们只采样到右侧,可能 \(\mathbb E_{x \sim q}[f(x)\frac{p(x)}{q(x)}]\) 是正的。我们这边采样到这些点,去计算它们的 \(f(x)\frac{p(x)}{q(x)}\) 都是正的。我们采样到这些点都是正的,取期望值以后也是正的,这是因为采样的次数不够多。假设我们采样次数很少,只能采样到右边。左边虽然概率很低,但也有可能被采样到。假设我们好不容易采样到左边的点,因为左边的点的 \(p(x)\) 和 \(q(x)\) 差是很多的,这边 \(p(x)\) 很大,\(q(x)\) 很小。\(f(x)\) 好不容易终于采样到一个负的,这个负的就会被乘上一个非常大的权重,这样就可以平衡刚才那边一直采样到正的值的情况。最终我们算出这一项的期望值,终究还是负的。但前提是我们要采样足够多次,这件事情才会发生。但有可能采样次数不够多,\(\mathbb E_{x \sim p}[f(x)]\) 与 \(\mathbb E_{x \sim q}[f(x)\frac{p(x)}{q(x)}]\) 可能就有很大的差距,这就是重要性采样的问题。
有了重要性采样,就可以使用旧模型参数\({\theta'}\)采集到的数据来更新新的模型参数\(\theta\),旧模型记作\(\pi_{\theta}\),新模型记作\(\pi_{\theta'}\)。
梯度公式:
这个公式是由REINFORCE的梯度公式加了一个重要性权重变换过来的。
状态动作对概率分开算:
这个式子表示在状态-动作对$ (s_t, a_t) $服从策略 \(π_θ\) 分布下的期望。其中\(A^{\theta}(s_t, a_t)\)表示的就是优势函数,之前在A2C算法里替换的那个,这里讨论的是重要性采样,继续使用\(A^{\theta}(s_t, a_t)\)来表示,最后在PPO算法里换成时序差分误差即可。
我们用状态-动作对$ (s_t, a_t) $服从策略 \(π_{\theta'}\) 分布下的期望加上重要性权重\(f(x){\frac{p(x)}{q(x)}}\)来近似$ (s_t, a_t) \(在\)π_θ$下的分布,即:
由于:
因此:
假设模型是\({\theta}\)的时候,我们看到\(s_t\)的概率,与模型是\(θ'\)的时候,我们看到\(s_t\)的概率是一样的,即\({p_{\theta}(s_t)} = {p_{\theta'}(s_t)}\)。因此可得:
为什么可以这样假设呢?有很多种解释,有的说差的不远,有的说环境状态与动作关联性不是很强,也有的说随机系统怎么怎么滴,反正也不用纠结了,不这么干这个算法很难进行下去,这么做效果好就对了!
根据之前策略梯度算法里面的套路:
那我们要优化的目标函数就是:
我们本来是要在\(\theta\)上进行采样来更新\(\theta\)的,但是现在变成在\(\theta'\)上采样来更新\(\theta\)了,那就由同策略学习变成了异策略学习。
以上就是重要性采样。它有一个显而易见的问题,就是新旧策略差距过大的话,旧策略采出来的数据意义就不是很大了,PPO算法就是为了解决这一问题。
4.2近端策略优化(PPO)
为了不使\(p_{\theta}(a_t|s_t)\)和\(p_{\theta'}(a_t|s_t)\)差距过大,就是让两个概率模型差距不那么大,之前我们是用交叉熵来衡量两个概率模型的差距,在这里我们使用相对熵,也就是KL散度来衡量这种差距。
KL散度公式:
\(D_{KL}(P||Q)\)表示KL散度,KL散度量化了如果用\(Q\)来表示\(P\),需要付出多少额外的信息代价。
既然我们可以量化两个模型之间的差距,模型之间的差距又不能过大,就顺理成章的能想到把量化过后的模型之间的差距当成一个正则项加到目标函数里面去不就行了吗,事实上PPO算法也是这样做的。
PPO算法的优化目标(损失函数):
PPO 有一个前身:信任区域策略优化(trust region policy optimization,TRPO)。TRPO 可表示为:
TRPO看起来和PPO很接近了,但是它把KL散度当成一种约束了,这种约束在基于梯度优化里面很难实现它,但是如果像PPO那样直接当成一个正则项,那么梯度优化实现它就会非常简单。
PPO算法还有两个变体。
4.2.1 近端策略优化惩罚(PPO-penalty、PPO1)
在实现PPO算法的时候一般使用前一个训练的迭代得到的演员的参数\(\theta^k\)与环境做大量交互,得到大量数据,来更新\(\theta\),就可以写成这样:
里面有个超参数\(\beta\)有点不好控制,我们可以给KL散度设置一个最大值,一个最小值,当KL散度大于最大值的时候,就说明后面的罚没有发挥作用,就是正则项作用太小了,就增大\(\beta\)提升KL散度的影响,当KL散度小于最小值的时候,就说明罚的太重了,后面一项的效果太强了,就减小\(\beta\)削弱KL散度的影响。
因此我们称之为自适应KL惩罚(adaptive KL penalty)。
4.2.2 近端策略优化裁剪(PPO-clip、PPO2)
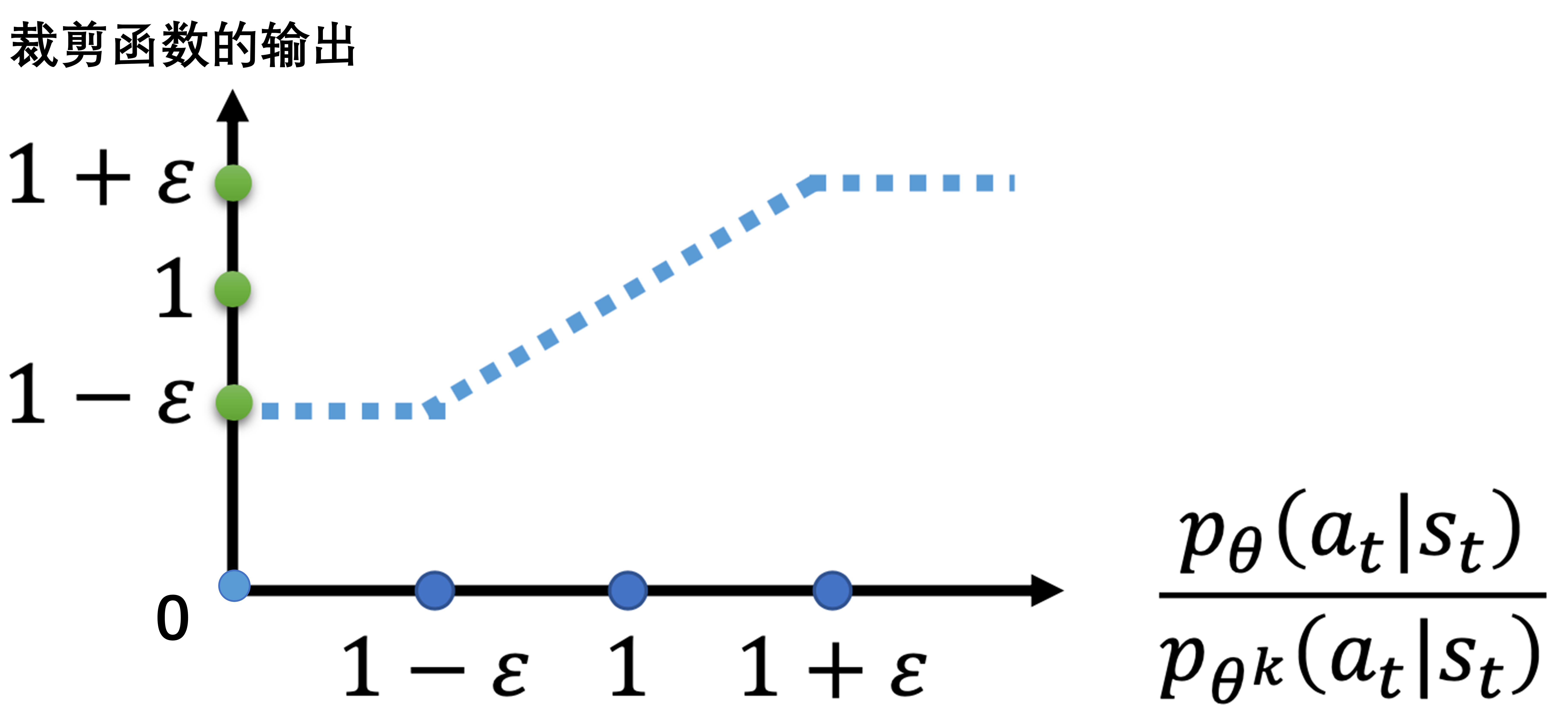
如果觉得计算 KL 散度太复杂了,还有一个 PPO2算法,PPO2 即近端策略优化裁剪。近端策略优化裁剪的目标函数里面没有 KL 散度,其要最大化的目标函数为
第二项前面有一个裁剪(clip)函数,裁剪函数是指,在括号里面有3项,如果第一项小于第二项,那就输出\(1−ε\);第一项如果大于第三项,那就输出\(1+ε\)。
\(ε\)是一个超参数,是我们要调整的,可以设置成 0.1 或 0.2 。
剪裁函数图像:
看到PPO2的目标函数就不如之前的式子好理解了,那这个到底是啥意思呢,不用KL散度怎么知道新模型和旧模型之间的差距呢?

再重新审视一下剪裁函数
观察上面两幅图,绿色的线指的是\(\frac{p_{\theta}(a_t|s_t)}{p_{\theta^k}(a_t|s_t)}\),蓝色的线指的是被剪裁之后的样子。
- \(A^{\theta^k}(s_t, a_t) > 0\)表示当前状态动作对是好的。希望它的概率,也就是\(p_{\theta}(a_t|s_t)\)越大越好,但是也不能太大,它与\(p_{\theta'}(a_t|s_t)\)的比值不能超过\(1+ε\),如果超过了就会遇到我们之前的方差问题,红色的线就是指的是目标函数。
- \(A^{\theta^k}(s_t, a_t) < 0\)表示当前状态动作对是不好的。同理,希望它的概率,也就是\(p_{\theta}(a_t|s_t)\)越小越好,但是也不能太小,它与\(p_{\theta'}(a_t|s_t)\)的比值不能低于\(1-ε\),如果低于了就会遇到我们之前的方差问题,红色的线就是指的是目标函数。
4.3 PPO算法的实现
这里我们选择实现的是近端策略优化裁剪,也就是PPO2,PPO算法是策略梯度算法的一种,为了将其效果最大化,可以结合A2C算法一起使用,那就是Critic网络和A2C一样,A2C算法中Actor我们用PPO的优化目标来代替A2C算法中的目标,同时我们采用时时序差分的方法来做采样,把优势函数换成时序差分误差即可,损失函数就变成了以下:
其中\(\delta_t^n = r_t^n + V_{\pi}(s_{t+1}^n) - V_{\pi}(s_t^n) \text{:TD-error。}\)
但是在PPO的实现里面我们一般不直接这么做,而是像套娃一样用了另一种叫做GAE(Generalized Advantage Estimation)的误差来取代TD-error,就像最开始我们用回报\(G_t\)来取代单步奖励\(r_t\)那样,\(G_t\)的公式是这样的:
也就是:
那GAE是怎么做的呢?
也可以写成
这样看就非常清楚了,其中\(\delta_t = r_t + V_{\pi}(s_{t+1}) - V_{\pi}(s_t) \text{:TD-error。}\)
-
当\(λ=0\),GAE等价于单步 TD,偏差低但方差高。
-
当\(λ=1\),GAE近似于蒙特卡洛回报(Monte Carlo Return),方差低但偏差高。
-
调整\(λ\)参数可以在偏差和方差之间找到一个更合适的折中。
-
\(γ\)是折扣因子,控制对未来奖励的关注程度。
用GAE来替代之前的\(A^{\theta^k}(s_t, a_t)\),那公式就可以写成:
智能体的任务和之前的A2C算法里面的任务是一样的。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torch.distributions import Categorical
import matplotlib.pyplot as plt
class Config:
def __init__(self):
# PPO特定参数
self.clip_epsilon = 0.2 # PPO裁剪系数,用于限制策略更新的幅度
self.ppo_epochs = 10 # 每次更新的PPO轮数
self.batch_size = 64 # 小批量训练的大小
self.gae_lambda = 0.95 # GAE参数,用于计算优势函数
# 基础参数
self.hidden_dim = 64 # 神经网络隐藏层维度
self.lr = 0.0003 # 学习率
self.gamma = 0.99 # 折扣因子
self.max_episodes = 5000 # 最大训练回合数
self.max_steps = 500 # 每个回合最大步数
self.seed = 42 # 随机种子
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 设备选择(GPU/CPU)
self.entropy_coef = 0.01 # 熵正则化系数,用于鼓励探索
# 分离Actor和Critic网络
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
# 定义Actor网络结构
self.network = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层到隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, action_dim), # 隐藏层到输出层
nn.Softmax(dim=-1) # 输出层使用Softmax得到动作概率分布
)
def forward(self, state):
# 前向传播,返回动作概率分布
return self.network(state)
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
# 定义Critic网络结构
self.network = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层到隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, 1) # 隐藏层到输出层,输出状态价值
)
def forward(self, state):
# 前向传播,返回状态价值
return self.network(state)
class PPO:
def __init__(self, state_dim, action_dim, config):
self.config = config
self.actor = Actor(state_dim, action_dim) # 初始化Actor网络
self.critic = Critic(state_dim) # 初始化Critic网络
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=config.lr) # Actor优化器
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=config.lr) # Critic优化器
def get_action(self, state):
with torch.no_grad():
state = torch.FloatTensor(state) # 转换状态为张量
action_probs = self.actor(state) # 获取动作概率分布
dist = Categorical(action_probs) # 创建类别分布
action = dist.sample() # 采样动作
action_log_prob = dist.log_prob(action) # 获取动作的对数概率
return action.item(), action_log_prob.item() # 返回动作和对数概率
def compute_gae(self, values, rewards, dones, next_value):
advantages = []
gae = 0
for t in reversed(range(len(rewards))):
if t == len(rewards) - 1:
next_val = next_value # 最后一步的下一个值
else:
next_val = values[t + 1] # 其他步骤的下一个值
delta = rewards[t] + self.config.gamma * next_val * (1 - dones[t]) - values[t] # TD误差
gae = delta + self.config.gamma * self.config.gae_lambda * (1 - dones[t]) * gae # 计算GAE
advantages.insert(0, gae) # 插入到优势列表开头
advantages = torch.FloatTensor(advantages) # 转换为张量
return advantages
def update(self, states, actions, old_log_probs, rewards, dones, next_state):
states = torch.FloatTensor(np.array(states)) # 转换状态为张量
actions = torch.LongTensor(actions) # 转换动作为张量
old_log_probs = torch.FloatTensor(old_log_probs) # 转换旧的对数概率为张量
# 计算GAE
with torch.no_grad():
values = self.critic(states).squeeze() # 获取当前状态的价值
next_value = self.critic(torch.FloatTensor(next_state)).item() # 获取下一个状态的价值
advantages = self.compute_gae(values.tolist(), rewards, dones, next_value) # 计算优势
returns = advantages + values # 计算回报,即优势+状态价值,因为advantages是基于TD误差的是相对值,所以需要加上状态价值得到绝对值,来稳定训练
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8) # 标准化优势
# PPO更新多轮
for _ in range(self.config.ppo_epochs):
for idx in range(0, len(states), self.config.batch_size):
batch_states = states[idx:idx + self.config.batch_size] # 获取小批量状态
batch_actions = actions[idx:idx + self.config.batch_size] # 获取小批量动作
batch_old_log_probs = old_log_probs[idx:idx + self.config.batch_size] # 获取小批量旧的对数概率
batch_advantages = advantages[idx:idx + self.config.batch_size] # 获取小批量优势
batch_returns = returns[idx:idx + self.config.batch_size] # 获取小批量回报
# 计算新的动作概率
action_probs = self.actor(batch_states)
dist = Categorical(action_probs)
new_log_probs = dist.log_prob(batch_actions)
# 计算熵
entropy = dist.entropy().mean()
# 计算比率和裁剪后的目标
ratio = torch.exp(new_log_probs - batch_old_log_probs)
surr1 = ratio * batch_advantages
surr2 = torch.clamp(ratio, 1-self.config.clip_epsilon, 1+self.config.clip_epsilon) * batch_advantages
# 计算Actor损失(加入熵正则化项)
actor_loss = -torch.min(surr1, surr2).mean() - self.config.entropy_coef * entropy
# 计算Critic损失
critic_values = self.critic(batch_states).view(-1) # 使用 view(-1) 替代 squeeze()
critic_loss = nn.MSELoss()(critic_values, batch_returns)
# 更新Actor网络
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# 更新Critic网络
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
def train_ppo():
config = Config() # 初始化配置
env = gym.make("CartPole-v1") # 创建环境
state_dim = env.observation_space.shape[0] # 获取状态维度
action_dim = env.action_space.n # 获取动作维度
agent = PPO(state_dim, action_dim, config) # 初始化PPO智能体
rewards = [] # 用于存储每个回合的奖励
for episode in range(config.max_episodes):
state, _ = env.reset() # 重置环境
states, actions, rewards_buffer, log_probs, dones = [], [], [], [], [] # 初始化存储变量
total_reward = 0 # 初始化总奖励
for step in range(config.max_steps):
action, log_prob = agent.get_action(state) # 获取动作和对数概率
next_state, reward, done, _, _ = env.step(action) # 执行动作
states.append(state) # 存储状态
actions.append(action) # 存储动作
rewards_buffer.append(reward) # 存储奖励
log_probs.append(log_prob) # 存储对数概率
dones.append(done) # 存储是否结束
total_reward += reward # 累加奖励
state = next_state # 更新状态
if done:
break
agent.update(states, actions, log_probs, rewards_buffer, dones, next_state) # 更新智能体
rewards.append(total_reward) # 记录每个回合的奖励
print(f"Episode {episode + 1}, Total Reward: {total_reward}") # 打印当前回合的奖励
if total_reward >= 500:
print("Solved!") # 如果总奖励达到500,表示问题解决
break
env.close() # 关闭环境
# 绘制reward曲线
plt.plot(rewards)
plt.title('Training Rewards')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.show()
if __name__ == "__main__":
train_ppo()
结果:

可以看到,两百次采样以内就能达到目标,获得奖励(500)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号