ES 聚合查询
ES聚合查询主要又三种模式,分别是分桶聚合(Bucket aggregations)、指标聚合(Metrics aggregations)、管道聚合(Pipeline aggregations),三种模式处理的业务场景不同,下面开始简要分析下.
1、分桶聚合(Bucket aggregations)
分桶聚合类似与关系型数据库的Group By查询,按照指定的条件,进行分组统计.下面用一张网络图(来自马士兵教育)来解释
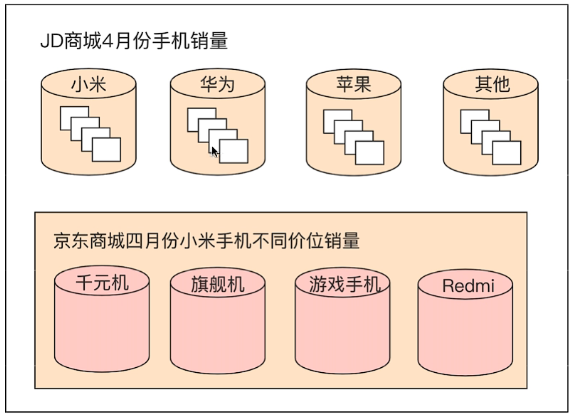
图中首先按照手机的品牌进行分桶统计数量,接着在小米手机的分桶基础上,再按照小米手机的档次进行二次分桶(分桶的嵌套查询)统计数量.
分桶聚合大致就是为了完成以上需求的
2、指标聚合(Metrics aggregations)
指标聚合主要是计算指标的Avg(平均值)、Max(最大值)、Min(最小值)、Sum(求和)、Cardinality(去重)、ValueCount(记数)、Stats(统计聚合)、Top Hits(聚合)等.下面用一张网络图(来自马士兵教育)来解释
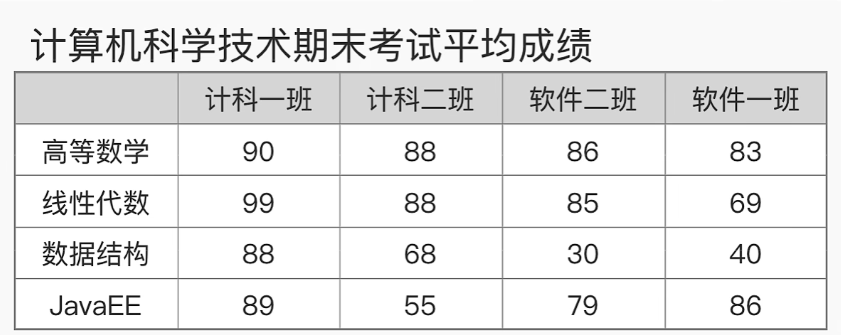
可以通过指标聚合计算某个班级、某个学科的最高分、最低分等等.
3、管道聚合(Pipeline aggregations)
管道聚合主要用于对聚和结果的二次聚合,举个例子,这里需要计算某个商城中的各个品牌手机价格平均值中最小的手机品牌.
这里第一步需要计算各个手机品牌价格的平均值,接着计算平均值中的最小值,这里就需要用到管道聚合.
4、实战演练
4.1、创建索引
进入kibna dev tools,输入以下代码创建索引
PUT food { "settings": { "number_of_shards": 3, //主分片3个 "number_of_replicas": 1 //每个分片包含一个副本 }, "mappings": { "date_detection": false, //关闭日期检测 "properties": { "CreateTime":{ "type":"date", "format": "yyyy-MM-dd HH:mm:ss" //指定写入的日期格式 }, "Desc":{ "type": "text", "fields": { "keyword":{ "type":"keyword", //创建正排索引 "ignore_above":256 } }, "analyzer": "ik_max_word",//数据写入时拆分的粒度越小越好 "search_analyzer": "ik_smart"//一般情况下,用户搜索时拆分的粒度不能很小,会导致用户检索不到想要的 }, "Level":{ "type": "text", "fields": { "keyword":{ "type":"keyword", "ignore_above":256 } } }, "Name":{ "type": "text", "fields": { "keyword":{ "type":"keyword", "ignore_above":256 } }, "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "Price":{ "type": "float" }, "Tags":{ "type": "text", "fields": { "keyword":{ "type":"keyword", "ignore_above":256 } } }, "Type":{ "type": "text", "fields": { "keyword":{ "type":"keyword", "ignore_above":256 } } } } } }
执行以上代码完成索引的创建.
4.2 插入数据
PUT food/_doc/1 { "CreateTime":"2022-06-06 11:11:11", "Desc":"青菜 yyds 营养价值很高,很好吃", "Level":"普通蔬菜", "Name":"青菜", "Price":11.11, "Tags":["性价比","营养","绿色蔬菜"], "Type":"蔬菜" } PUT food/_doc/2 { "CreateTime":"2022-06-06 13:11:11", "Desc":"大白菜 好吃 便宜 水分多", "Level":"普通蔬菜", "Name":"大白菜", "Price":12.11, "Tags":["便宜","好吃","白色蔬菜"], "Type":"蔬菜" } PUT food/_doc/3 { "CreateTime":"2022-06-07 13:11:11", "Desc":"芦笋来自国外进口的蔬菜,西餐标配", "Level":"中等蔬菜", "Name":"芦笋", "Price":66.11, "Tags":["有点贵","国外","绿色蔬菜","营养价值高"], "Type":"蔬菜" } PUT food/_doc/4 { "CreateTime":"2022-07-07 13:11:11", "Desc":"苹果 yyds 好吃 便宜 水分多 营养", "Level":"普通水果", "Name":"苹果", "Price":11.11, "Tags":["性价比","易种植","水果","营养"], "Type":"水果" } PUT food/_doc/5 { "CreateTime":"2022-07-09 13:11:11", "Desc":"榴莲 非常好吃 很贵 吃一个相当于吃一只老母鸡", "Level":"高级水果", "Name":"榴莲", "Price":100.11, "Tags":["贵","水果","营养"], "Type":"水果" } PUT food/_doc/6 { "CreateTime":"2022-07-08 13:11:11", "Desc":"猫砂王榴莲 榴莲中的战斗机", "Level":"高级水果", "Name":"猫砂王榴莲", "Price":300.11, "Tags":["超级贵","进口","水果","非常好吃"], "Type":"水果" }
执行以上代码,完成索引数据的插入.
4.3 分桶聚合(Bucket aggregations)
现在查询各个标签的产品数据,如超级贵的食物有多少个,并按照标签属性进行升序排列,代码如下:
GET food/_search { "size": 0, //关闭hit(source)数据的显示 "aggs": { "tags_aggs": { "terms": { "field": "Tags.keyword", //一般情况下,带有keyword的类型的字段才能进行聚合查询,应为keyword类型,es会为其创建正排索引
"size": 20, //显示的桶的个数,常用于分页,
"order": { "_count": "asc" //按照每个桶统计的数量进行升序排列 } } } } }
搜索结果如下:
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "tags_aggs" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "便宜", "doc_count" : 1 }, { "key" : "国外", "doc_count" : 1 }, { "key" : "好吃", "doc_count" : 1 }, { "key" : "易种植", "doc_count" : 1 }, { "key" : "有点贵", "doc_count" : 1 }, { "key" : "白色蔬菜", "doc_count" : 1 }, { "key" : "营养价值高", "doc_count" : 1 }, { "key" : "贵", "doc_count" : 1 }, { "key" : "超级贵", "doc_count" : 1 }, { "key" : "进口", "doc_count" : 1 }, { "key" : "非常好吃", "doc_count" : 1 }, { "key" : "性价比", "doc_count" : 2 }, { "key" : "绿色蔬菜", "doc_count" : 2 }, { "key" : "水果", "doc_count" : 3 }, { "key" : "营养", "doc_count" : 3 } ] } } }
这里需要注意两点
(1)、一般情况下,text类型(应为内容较长),es不会为其创建正排索引,但是带有keyword类型的text类型,es会为其创建倒排索引的同时创建正派索引(但是此时的keyword正排索引会有长度限制通过ignore_above去配置)。es中一般只有正排索引才能进行聚合查询
(2)、一般情况下,不会对text字段创建正排索引,应为对大文本字段创建正排索引没有什么意义,而且正排索引会创建磁盘文件,浪费资源和空间.
(3)、通过fielddata 修改mapping通过如下代码
POST food/_mapping { "properties":{ "Tags":{ "type":"text", "fielddata":true } } }
执行上述代码,接着直接如下搜索
GET food/_search { "size": 0, //关闭hit(source)数据的显示 "aggs": { "tags_aggs": { "terms": { "field": "Tags", //这里不在用keyword "size": 20, //显示的桶的个数,常用于分页, "order": { "_count": "asc" //按照每个桶统计的数量进行升序排列 } } } } }
搜索结果如下:
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "tags_aggs" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 35, "buckets" : [ { "key" : "便", "doc_count" : 1 }, { "key" : "值", "doc_count" : 1 }, { "key" : "口", "doc_count" : 1 }, { "key" : "国", "doc_count" : 1 }, { "key" : "外", "doc_count" : 1 }, { "key" : "宜", "doc_count" : 1 }, { "key" : "常", "doc_count" : 1 }, { "key" : "易", "doc_count" : 1 }, { "key" : "有", "doc_count" : 1 }, { "key" : "植", "doc_count" : 1 }, { "key" : "点", "doc_count" : 1 }, { "key" : "白", "doc_count" : 1 }, { "key" : "种", "doc_count" : 1 }, { "key" : "级", "doc_count" : 1 }, { "key" : "超", "doc_count" : 1 }, { "key" : "进", "doc_count" : 1 }, { "key" : "非", "doc_count" : 1 }, { "key" : "高", "doc_count" : 1 }, { "key" : "吃", "doc_count" : 2 }, { "key" : "好", "doc_count" : 2 } ] } } }
这里明显收到了分词器的影响,因为Tags属性没有指定ik分词器,所以这里用的是standard分词器.接着用分词结果进行了桶聚合.
注意需要注意的是通过fielddata创建的正排索引是位于jvm堆空间中的,是一种临时手段,所以通过这种方式容易引起oom,数据量大的时候要谨慎使用.
4.4 指标聚合(Metrics aggregations)
4.4.1 现在按照价格统计以下,所有食物价格的最贵的、所有食物价格的最便宜的、所有食物价格的平均值、所有食物价格的总和,代码如下:
GET food/_search { "size": 0, //关闭hit(source)数据的显示 "aggs": { "max_price":{ "max": { "field": "Price" } }, "min_price":{ "min": { "field": "Price" } }, "avg_price":{ "avg": { "field": "Price" } }, "sum_price":{ "sum":{ "field": "Price" } } } }
执行结果如下:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "max_price" : { "value" : 300.1099853515625 }, "min_price" : { "value" : 11.109999656677246 }, "avg_price" : { "value" : 83.44333092371623 }, "sum_price" : { "value" : 500.65998554229736 } } }
注意这里有简便操作通过stats进行快速的查询,代码如下:
GET food/_search { "size": 0, "aggs": { "price_stats": { "stats": { "field": "Price" } } } }
结果如下:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "price_stats" : { "count" : 6, "min" : 11.109999656677246, "max" : 300.1099853515625, "avg" : 83.44333092371623, "sum" : 500.65998554229736 } } }
4.4.2 按照名称对所有的食品进行去重
GET food/_search { "size": 0, //关闭hit(source)数据的显示 "aggs": { "name_count_no_equal":{ "cardinality": { "field": "Name.keyword" } } } }
结果如下:
{ "took" : 3, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "name_count_no_equal" : { "value" : 6 } } }
4.5 管道聚合(Pipeline aggregations)
现在需要计算各个物分类中价格平均值最低的食物分类,代码如下:
GET food/_search { "size": 0, "aggs": { "type_bucket": { //首先按照Type字段进行分桶 "terms": { "field": "Type.keyword" }, //因为要计算各个分桶的平均值,所以在分桶的基础上做指标聚合 "aggs": { "price_bucket": { "avg": { "field": "Price" } } } }, //这里通过buckets_path实现查找平均值最低的食物分类的桶 "min_bucket":{ "min_bucket": { "buckets_path": "type_bucket>price_bucket" } } } }
搜索结果如下:
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "type_bucket" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "水果", "doc_count" : 3, "price_bucket" : { "value" : 137.1099952061971 } }, { "key" : "蔬菜", "doc_count" : 3, "price_bucket" : { "value" : 29.77666664123535 } } ] }, "min_bucket" : { "value" : 29.77666664123535, "keys" : [ "蔬菜" ] } } }
结果中首先buckets实现了按照Type进行分桶,内部的price_bucket实现了各个分桶的平均值计算,最后再通过min_bucket的buckets_path实现了平均值最小的Type的查找.
这里大致的逻辑是过程化的,第一步先按照Type进行分桶计算,为了计算每个分桶的平均值,所以需要在分桶计算的基础上进行指标计算,这里对应的步骤就是在type_bucket的内部在次做了agg运算,最后在前面结果集的基础上通过bucket_path,查找平均值最低的分桶的类型.
4.6 复杂的嵌套聚合查询
现在需要计算每个食物分类中,不同档次的食品中,价格最低的食物,代码如下:
GET food/_search { "size": 0, "aggs": { "type_bucket": { //首先按照Type进行分桶 "terms": { "field": "Type.keyword" }, "aggs": { "level_bucket": { //然后按照Level进行分桶 "terms": { "field": "Level.keyword" }, "aggs": { //接着计算不同Type下的Level分桶的平均值 "price_avg": { "avg": { "field": "Price" } } } }, //因为是要计算最低平均值的分类,所以buckets_path要和level分桶查询平级 "min_leve_bucket":{ "min_bucket": { "buckets_path": "level_bucket>price_avg" } } } } } }
查询结果如下:
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 3, "successful" : 3, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "type_bucket" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "水果", "doc_count" : 3, "level_bucket" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "高级水果", "doc_count" : 2, "price_avg" : { "value" : 200.10999298095703 } }, { "key" : "普通水果", "doc_count" : 1, "price_avg" : { "value" : 11.109999656677246 } } ] }, "min_leve_bucket" : { "value" : 11.109999656677246, "keys" : [ "普通水果" ] } }, { "key" : "蔬菜", "doc_count" : 3, "level_bucket" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "普通蔬菜", "doc_count" : 2, "price_avg" : { "value" : 11.609999656677246 } }, { "key" : "中等蔬菜", "doc_count" : 1, "price_avg" : { "value" : 66.11000061035156 } } ] }, "min_leve_bucket" : { "value" : 11.609999656677246, "keys" : [ "普通蔬菜" ] } } ] } } }
这里还是过程化的脚本,但是要注意的是bucket_path,要和统计的目标对象平级.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号