mysql 执行原理
1.为什么使用Msyql
开放、免费
2.mysql介绍
关系型数据库管理系统(RDBMS)来存储和管理的大数据量。
所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法
来处理数据库中的数据。
RDBMS即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
注:
保证数据一致性。
关系型数据库,表与表之间存在对应关系。
非关系行数据库,表之间不存在关系,数据独立,随便存。
MYSQL是最流行的关系型数据库管理系统 。
支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
使用标准的SQL数据语言形式。
可以允许于多个系统上,并且支持多种语言。
这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
对PHP有很好的支持,PHP是目前最流行的Web开发语言。
支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,
64位系统支持最大的表文件为8TB。
是可以定制的,采用了GPL协议,你可以修改源码来开发自己的MYSQL系统。
GPL协议 。双向授权协议,就是通过账号密码继续访问。 GPL就是一个为了保护软件自由的一个协议,它强调的是开源,与钱无关。
3.mysql执行原理
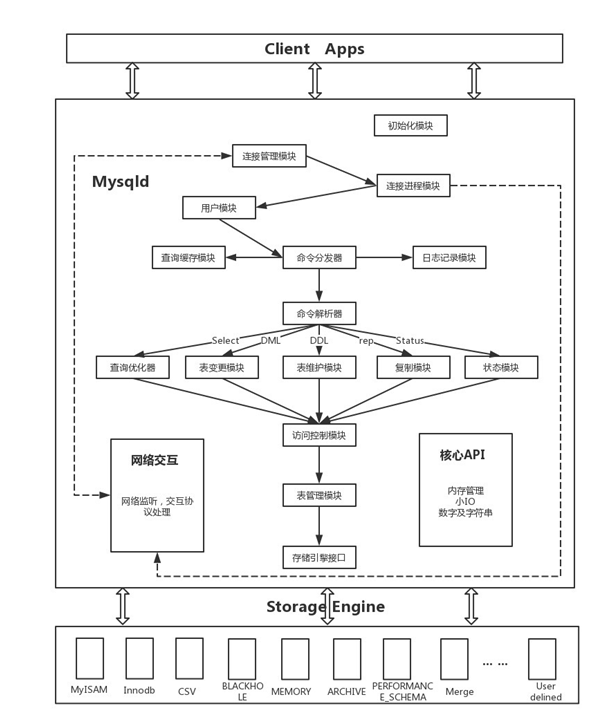
阐述mysql系统的各个模块是如何相亲相爱的完成一个我们认为的很简单的查询工作的。
我们对启动mysql,客户端建立连接,请求query,得到返回结果,最终退出。这样一整个过程来进行分析。
第一步:当我们执行启动mysql系统的命令之后,mysql的初始化模块就从系统配置文件中读取系统参数和命令行参数,并按照参数来初始化整个系统,如申请并分配buffer,初始化全局变量,以及各种结构等。同时各个存储引擎也被启动,进行各自的初始化工作。当整个系统初始化结束后,由连接管理模块接手,连接管理模块会启动处理客户端连接请求的监听程序,包括tcp/ip的网络监听,还有unix的socket,这时候,mysql server就基本启动完成,准备好接受客户端的请求了。
第二步:当连接管理模块监听到客户端的连接请求(借助网络交互模块的相关功能),双方通过Client & Server交互协议模块所定义的协议“寒暄”几句之后,连接管理模块就会将连接请求转发给线程管理模块,去请求一个连接线程。
第三步:线程管理模块接着将控制权交给连接线程模块,告诉连接线程模块,现在我这边连接请求过来了,需要建立连接,你赶快处理一下。连接线程模块会在接收到连接请求后,首先检查当前连接线程池中是否有被cache的空闲连接线程,如果有,就取出一个和客户端请求连接上,如果没有空闲的连接线程,则建立一个新的连接线程与客户端请求连接。当然,连接线程模块并不是在接收到连接请求后马上就会取出一个连接线程和客户端连接,而是首先通过调用用户模块进行授权检查,只有客户端请求通过了授权检查后,他才会将客户端请求和负责请求的连接线程连上。
在MySQL中,将客户端的请求分为了两种类型,一种是query,需要调用Parser也就是Query解析和转发模块的解析才能够执行的请求;一种是command,不需要调用Parser就可以执行的请求。如果我们的初始化配置打开了Full Query Logging(慢日志)的功能,那么Query解析与转发模块就会调用日志记录模块将请求计入日志。不管是一个Query类型的请求还是一个command类型的请求,都会被记录进入日志,所以出于性能考虑一般很少打开Full Query Logging的功能。
第四步:当客户端请求和连接线程“互换暗号(互通协议)”接上头之后,连接线程就开始处理客户端请求发送过来的各种命令(或者query),接受相关请求。他将收到的query语句转发给Query解析和转发模块,Query解析器先对Query进行基本的语义和语法解析,然后根据命令类型的不同,有些会直接处理,有些会分发给其他模块来处理。
如果是一个Query类型的请求,会将控制权交给Query解析器,Query解析器首先分析是不是一个select类型的query,如果是,则调用查询缓存模块,让它检查该query在query cache中是否已经存在。如果有,则直接将cache中的数据返回给连接线程模块。然后通过与客户端连接的线程将数据输出给客户端。如果不是一个可以被cache的query类型,或者cache中没有改query的数据,那么query将被继续传回Query解析器,让Query解析器进行相应处理,在通过Query分发器分发给相关处理模块。
第五步:如果解析器解析结果是一条未被cache的select语句,则将控制权交给Optimizer,也就是Query优化器模块,如果是DML或者是DDL语句,则会交给表变更管理模块,如果是一些更新统计信息、检测、修复和整理类的query则会交给表维护模块去处理,复制相关的query则转交给复制模块去进行相应的处理,请求状态的query则交给状态收集报告模块。实际上表变更管理模块根据所对应的处理请求的不同,是分别由insert处理器、delete处理器、update处理器、create处理器,以及alter处理器这些小模块来负责不同的DML和DDL的。
第六步:在各个模块收到Query解析与分发模块发过来的请求后,首先会通过访问控制模块检查连接用户是否有访问控制目标表以及目标字段的权限,如果有,就会调用表管理模块请求相应的表,并获取对应的锁。表管理模块首先会看到该表是否已经存在于table cache中,如果已经打开则直接进行锁相关的处理,如果没有在cache中,则需要在打开表文件获取锁,然后将打开的表交给表变更管理模块。
第七步:当表变更管理模块“获取”打开的表之后,就会根据该表的相关meta信息,判断表的存储引擎类型和其它相关信息。根据表的存储引擎类型,提交请求给存储引擎接口模块,调用对应的存储引擎实现模块,进行相应处理。
不过,对于表变更管理模块来说,可见的仅是存储引擎接口模块提供的一系列“标准”接口,底层存储引擎实现模块的具体实现,对于表变更管理模块来说是透明的。他只需要调用对应的接口,并指定表类型,接口模块会根据表类型调用正确存储引擎来进行相应的处理。
第八步:当一条query或者是一个command处理完成(成功或者失败)之后,控制权都会交还给连接线程模块。如果处理成功,则将处理结果(可能是一个Result set,也可能是成功或者失败的标识)通过连接线程反馈给客户端。如果处理过程中发生错误,也会将相应的错误信息发送给客户端,然后连接线程模块会进行相应的清理工作,并继续等待后面的请求,重复上面提到的过程,或者完成客户端断开连接的请求。
第九步:如果在上面的过程中,相关模块使数据库中的数据发生了变化,而且MySQL打来了bin-log功能,则对应的处理模块还会调用日志处理模块将相应的变更语句以更新事件的形式记录到相关参数指定的二进制日志文件中。
在上面各个模块的内容处理过程中,各自的核心运算处理功能部分都会高度依赖整个MySQL API模块,比如内存管理,文件I/O,数字和字符串处理等。
您的资助是我最大的动力!
金额随意,欢迎来赏!


