
对数据集做标准化处理的几种方法——基于R语言
数据集——iris(R语言自带鸢尾花包)
一、scale函数
scale函数默认的是对制定数据做均值为0,标准差为1的标准化。它的两个参数center和scale:
1)center和scale默认为真,即T
2)center为真表示数据中心化
3)scale为真表示数据标准化
中心化:所谓数据的中心化是指数据集中的各项数据减去数据集的均值。
标准化:标准化就是数据在中心化之后再除以标准差。变换后值域为[0,1]。
# 标准化与中心化
data(iris) # 读入数据
head(iris) #查看数据
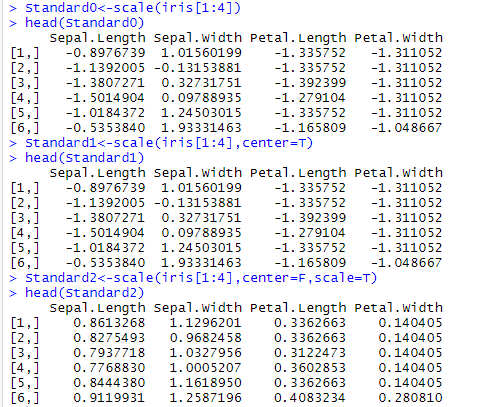
Standard0<-scale(iris[1:4])
head(Standard0)
Standard1<-scale(iris[1:4],center=T)
head(Standard1)
Standard2<-scale(iris[1:4],center=F,scale=T)
head(Standard2)
二、用自建函数法
test <- iris normalize <- function(x) { return((x - min(x)) / (max(x) - min(x))) } test_n <- as.data.frame(lapply(test[1:4], normalize)) head(test_n)

三、caret包preProcess函数
preProcess函数可以对特征变量施行很多操作,包括中心化和标准化。preProcess函数每次操作都估计所需要的参数,并且由predict.preProcess 应用于指定的数据集。
相比自建函数,非数值型的变量是被允许的,但是将被忽略故够保留数据集右边的非数值变量。
standard4 <- preProcess(iris, method = 'range') #化为0-1之间(x-min(x))/(max(x)-min(x)),其实range 的意义尚未理解 iris_s<- predict(standard4, iris) iris_s


 浙公网安备 33010602011771号
浙公网安备 33010602011771号