轨迹联邦用到的具体公式 + 轨迹模块的设计
轨迹数据 + road network数据
LightTR: A Lightweight Framework for Federated Trajectory Recovery
是的,您说得对。这里的数据确实可以分为两种:
-
轨迹数据(Trajectory Data):
- 轨迹数据包含了一个移动对象(比如车辆)的行进路径,是通过GPS设备记录下来的。
- 这些数据由一系列GPS点组成,每个点记录了位置(纬度、经度)和时间戳。
- 轨迹数据可以是不完整的,可能包含噪声、缺失点等。在处理时,通常会经过地图匹配(Map Matching),将轨迹点关联到具体的道路片段上,从而形成地图匹配后的轨迹数据。
-
道路网络数据(Road Network Data):
- 道路网络被表示为一个有向图 $ G = (V, E) $,其中:
- $ V $ 是道路的顶点集合,每个顶点代表道路网络中的一个节点,比如交叉点或道路的端点。
- $ E $ 是道路的边集合,每条边表示两条道路片段之间的连接关系。
- 道路网络数据定义了道路之间的拓扑结构,包括道路片段、路口连接和道路的方向。
- 这种数据可以用于辅助地图匹配,将轨迹点匹配到道路片段上,帮助准确地恢复出行路径。
- 道路网络被表示为一个有向图 $ G = (V, E) $,其中:
总结
因此,这里确实包含两种数据:
- 轨迹数据:记录了移动对象在不同时间点的GPS位置。
- 道路网络数据:定义了道路片段之间的关系和连接结构,用于帮助理解轨迹数据的空间关系和路径约束。
这两种数据结合使用,可以帮助完成轨迹恢复任务,即在道路网络的约束下,对不完整的轨迹数据进行补全和恢复。
在这个 LightTR 框架中,输入的轨迹数据和路网数据通过以下几个模块进行计算和处理:
1. 局部轨迹预处理(Local Trajectory Preprocessing)
- 首先,对输入的原始轨迹数据进行地图匹配(Map Matching)。地图匹配会将GPS记录的轨迹点投影到道路网络中的具体道路片段上,形成“地图匹配轨迹”。
- 轨迹点被转换成对应的路网交叉点,使用隐马尔科夫模型(HMM)和已有的地图匹配方法(例如DHN)来生成轨迹序列。
- 生成的地图匹配轨迹 $ T = {(g_1, t_1), \dots, (g_n, t_n)} $ 包含了每个轨迹点在道路网络中的位置及其时间戳。
GRU用于编码,而ST-Blocks用于卷积输出预测
2. 轻量化轨迹嵌入模块(Lightweight Trajectory Embedding, LTE)
- 嵌入模型:将地图匹配后的轨迹 $ T $ 输入到嵌入模型中,该模型使用一个 Gated Recurrent Unit (GRU) 网络来捕捉轨迹的时序依赖特性。
- GRU将每个时间步的输入轨迹点 $ g_t $ 和当前的隐藏状态 $ h_{t-1} $ 结合来生成当前隐藏状态 $ h_t $。
- 这样就得到了轨迹的高维嵌入表示 $ h_t $,表示该轨迹的时空特征。
- ST-Blocks:在GRU生成的隐藏状态 $ h_t $ 基础上,使用一个自定义的时空操作模块(ST-operator)进一步处理,预测每个时间步的道路片段 $ e_t $ 和移动比率 $ r_t $。
- RNN层:ST-operator首先通过RNN计算高维隐藏特征 $ h_t' $,用于捕捉轨迹的序列依赖关系。
- 多任务模型(MT模型):接着,使用一个纯MLP的多任务模型(MT)来预测轨迹中道路片段 $ e_t $ 和移动比率 $ r_t $。由于道路片段和移动比率的相关性较高,使用多任务学习方式可以同时预测这两个特征,提高准确性。
3. 约束掩码层(Constraint Mask Layer)
- 在MT模型中,采用了约束掩码层来减少训练复杂度并进行细粒度的轨迹恢复。掩码层会基于距离对轨迹点施加约束,以确保预测点更接近原始轨迹点。
- 使用距离函数来度量预测点和真实轨迹点之间的欧式距离,将距离转化为一个权重 $ c_i = \exp(-\text{dist}^2 / \gamma) $,用于控制轨迹点的权重。
- 这个约束层在预测时可以对距离较远的候选道路片段进行惩罚,使模型更加关注与当前轨迹点更接近的候选道路片段。
4. 知识蒸馏(Knowledge Distillation)
- 为了在服务器和多个客户端之间实现有效的联邦学习,模型引入了知识蒸馏。使用预训练模型作为“教师模型”,在本地数据上生成知识表示,通过蒸馏的方式指导客户端的“学生模型”学习教师模型的知识。
- 在具体操作中,教师模型的预测结果被用来生成软标签,并传递给学生模型以提升其性能。
总结
在LightTR框架中:
- 轨迹数据首先经过地图匹配生成地图匹配轨迹。
- 轻量化嵌入模块将轨迹的时空特征嵌入,并通过ST-Blocks进行道路片段和移动比率的预测。
- 约束掩码层根据距离对候选点进行权重调整。
- 知识蒸馏用于联邦学习的优化,确保不同客户端在保持数据隐私的同时能够学习共享知识。
这些模块结合在一起,使得模型能够在道路网络的约束下,精准地恢复不完整的轨迹数据。
模块理解
是的,您可以这样理解。
在 LightTR 框架中:
-
GRU(Gated Recurrent Unit):
- GRU的主要作用是对轨迹中的每个节点进行编码,捕捉轨迹的时间依赖关系。
- 它逐步处理轨迹的每个节点,生成对应的隐藏状态 $ h_t $,这些隐藏状态代表了当前轨迹节点的时序特征。
-
ST-Blocks(时空块):
- ST-Blocks在GRU生成的隐藏状态基础上进一步处理,是一个用于输出预测的自定义模块。
- 具体来说,ST-Blocks包含了一个轻量化的时空操作模块(ST-operator),其中包括RNN层和多任务(MT)模型。RNN层负责生成高维特征,而MT模型用于多任务预测,输出当前轨迹节点的道路片段 $ e_t $ 和移动比率 $ r_t $。
- 这种结构可以理解为在GRU生成的轨迹编码基础上,通过类似“卷积”操作的多任务模块来预测轨迹节点的属性。
总结
- GRU用于对轨迹的每个节点进行编码,提取轨迹的时序特征。
- ST-Blocks则是在GRU编码的基础上,进一步通过卷积式的多任务预测模型,输出轨迹节点的具体预测(如道路片段和移动比率)。
所以您的理解是正确的:GRU负责编码,ST-Blocks负责基于编码的特征输出具体预测。
蒸馏损失在客户端-服务器的概念
在 LightTR 框架中的知识蒸馏过程主要分为从服务器到客户端和从客户端到服务器的两个步骤,具体流程如下:
1. 服务器到客户端:教师模型的初始化与下发
- 教师模型的预训练:在服务器端,首先对一个教师模型(teacher model)进行预训练,称之为meta-learner。这个教师模型通过部分客户端的子集轨迹数据进行训练,获得基础的元知识(meta-knowledge)。
- 模型参数下发:服务器将训练好的教师模型参数(即meta-knowledge)发送到每个客户端。这样,服务器端的教师模型就可以作为指导模型,帮助客户端在本地进行学习。
2. 客户端的本地训练(Student Model Training)
-
学生模型的初始化:在每个客户端,教师模型被用作学生模型(student model)的初始化参数。
-
本地数据学习:每个客户端根据自己的本地数据集对学生模型进行训练,目的是使模型适应本地的轨迹数据特性。每个客户端的轨迹数据会存在差异,因此需要本地优化。
-
蒸馏损失计算:在训练过程中,客户端利用从服务器传来的教师模型的知识(meta-knowledge)来计算蒸馏损失。具体来说,学生模型通过以下损失函数进行优化:
\[L_{\text{dist}}(f_{\text{tea}}, f_{\text{stu}}, T_{\text{icp}}) = \| f_{\text{tea}}(T_{\text{icp}}) - f_{\text{stu}}(T_{\text{icp}}) \|_2^2 \]这个损失函数衡量教师模型和学生模型之间的差异,通过最小化蒸馏损失,使得学生模型能够更接近教师模型的输出表现。
3. 客户端到服务器:全局模型的聚合
- 本地更新上传:客户端在本地训练完成后,将更新后的学生模型参数上传到服务器。
- 全局模型聚合:服务器将从多个客户端收到的本地模型更新进行聚合,从而生成一个全局模型。聚合的过程通常使用加权平均的方法。
- 动态调整参数 $ \lambda $:服务器根据每个客户端的验证精度(accuracy)和本地验证精度(acc_valid)之间的差异来动态调整参数 $ \lambda $,控制知识蒸馏的强度。如果客户端的本地模型表现已经很好(精度较高),则降低 $ \lambda $ 值,使得客户端模型不再依赖于教师模型。
4. 全局模型的迭代更新
- 迭代过程:整个蒸馏过程是一个迭代的循环。服务器持续接收客户端的更新并聚合生成新的全局模型,然后将该全局模型再次分发到客户端。
- 收敛条件:当全局模型在不同客户端的表现达到收敛条件(通常是准确度或损失的变化小于某个阈值)时,迭代过程停止。
总结
- 服务器初始化教师模型并将其下发到客户端;
- 客户端本地训练学生模型并使用蒸馏损失从教师模型中学习;
- 客户端将更新上传至服务器;
- 服务器聚合客户端的更新,并通过调节参数 $ \lambda $ 进一步优化全局模型。
这个过程确保了在数据分散的场景下,通过知识蒸馏实现高效的联邦学习,进而完成轨迹恢复任务。
A Graph-based Representation Framework for Trajectory Recovery via Spatiotemporal Interval-Informed Seq2Seq
从您描述的代码包含轨迹数据和路网数据来看,以下是典型的处理流程和模块化设计,可能与您的代码结构类似。此框架将分解为几个核心模块,分别处理轨迹数据和路网数据的预处理、特征提取、集成和预测等任务。
1. 数据预处理模块
-
轨迹数据预处理:
- 将原始轨迹数据(GPS记录的经纬度和时间戳)通过地图匹配算法映射到具体的道路片段上。这通常涉及使用Hidden Markov Model (HMM)或其他地图匹配算法,将每个轨迹点关联到道路网络中的特定道路片段。
- 对于时间戳,可以将其转化为相对时间间隔或者归一化时间,以便后续模块使用时间特征进行建模。
- 如果轨迹数据是低采样率的,可能还需要插值处理,以填补轨迹点之间的空隙。
-
路网数据预处理:
- 将道路网络建模为图结构 $G = (V, E) $,其中 $V $ 是道路片段节点的集合,$ E $ 是节点之间的连接关系。
- 使用Node2Vec或其他图嵌入方法为每个节点生成一个初步的地理位置嵌入,从而为道路片段提供初步的表示。
- 可能还会基于候选道路片段的概率,构建候选节点和连接关系,为候选图神经网络(例如CandiGNN)提供输入。
2. 图表示模块
-
地理表示模块(GeoGAT):
- 使用图注意力网络(GAT)进一步处理每个道路片段的地理嵌入,从而捕捉不同道路片段之间的空间关系。这一步能够帮助模型识别道路片段在空间结构上的相对位置,生成包含拓扑信息的节点嵌入。
-
候选节点表示模块(CandiGNN):
- 为每个轨迹点可能的候选道路片段生成表示。CandiGNN会基于轨迹点的候选概率(从地图匹配算法得出)来衡量各个候选道路片段之间的相关性。
- 在消息传递过程中,将候选概率作为权重,用于调整候选节点的表示,以捕捉轨迹点与其潜在路径的动态关系。
3. 时空轨迹表示模块
-
时间感知模块:
- 根据轨迹的时间信息,将时间戳转化为归一化时间值,并投影到嵌入空间中。这可以帮助模型识别出轨迹点之间的时间依赖关系。
-
空间感知模块:
- 使用每个轨迹点在路网图中的位置信息,将轨迹的空间信息表示为一个嵌入,通常结合网格ID和相对坐标。
- 将时间和空间嵌入结合,形成每个轨迹点的时空表示,从而在模型中保留时间和空间的联合关系。
4. 序列到序列模型(Seq2Seq)模块
-
编码器:
- 使用注意力增强的Transformer编码器来处理时空轨迹表示。编码器将图表示、轨迹点ID和速度特征等组合成一系列输入,构建时空感知的轨迹表示。
- 在编码器中增加时空间隔信息(如时间间隔和地理距离),以帮助模型在不同轨迹点之间捕捉上下文信息。
-
解码器:
- 使用特征差分感知解码器逐步预测轨迹点的位置。解码器在每个时间步预测当前轨迹点的目标道路片段ID和移动比率。
- 特征差分帮助解码器考虑相邻轨迹点之间的变化,从而更准确地进行逐点预测。
5. 训练和优化模块
- 多任务学习损失函数:
- 使用多任务学习的损失函数同时预测道路片段ID和移动比率,优化模型的时空预测能力。
- 交叉熵损失用于道路片段ID的分类,均方误差用于移动比率的回归预测。通过这种多任务损失的设置,可以在训练过程中兼顾位置预测的准确性和移动路径的合理性。
6. 预测与轨迹恢复模块
- 通过序列到序列模型的解码器预测完整轨迹,将缺失的轨迹点恢复,生成一个高采样率的轨迹。
- 使用模型输出的每个轨迹点的预测位置和时间,构建最终的轨迹路径。
总结
在您的代码中,轨迹数据和路网数据可能会依次经过以上模块:
- 数据预处理模块清洗和地图匹配;
- 图表示模块生成地理和候选表示;
- 时空轨迹表示模块生成时空联合表示;
- Seq2Seq模型模块通过时空感知编码和差分解码完成预测;
- 最后通过训练和预测模块优化模型并生成完整轨迹。
这些模块协同工作,能够有效地利用路网的拓扑结构和轨迹的时空信息来恢复轨迹中的缺失点,重构出完整的轨迹路径。
更通俗移动的解读
好的,下面是对模块 (a)、(b) 和 (c) 的详细说明,包括每个模块如何处理输入数据,以及它们在整个轨迹恢复框架中的角色。
(a) Trajectory-Aware Graph Representation(轨迹感知的图表示)
输入:
- 路网数据(Input_1):表示为一个有向图 $G = (V, E) \(,其中\) V \(是道路片段的集合,\)E $是道路片段之间的连接关系。
- 轨迹数据(通常包含 GPS 位置和时间戳)用于生成候选节点。
处理过程:
-
预训练嵌入(Pretraining-Emb):
- 通过Node2Vec或其他图嵌入方法,将路网图中的每个节点生成初始的地理位置嵌入(Initialized-Emb)。
-
GeoGAT模块:
- 将初始化的地理嵌入传入图注意力网络(GeoGAT),进一步增强节点之间的空间关系。得到的 Geo-Emb 包含了邻近道路片段的空间依赖信息,使得每个节点的表示不仅包含其自身的信息,还包含其周围道路片段的上下文关系。
-
候选节点表示模块(CandiGNN):
- 对每个轨迹点,根据候选节点生成网络(CandiGNN)来推断可能的候选道路片段。CandiGNN利用候选概率(RCP)生成候选节点嵌入(Candi-Emb),并采用消息传递机制在候选节点之间传播信息。这种机制使得轨迹点的候选节点信息可以集成到模型中,帮助预测它们的潜在位置。
-
图融合层(Graph Fusion Layer):
- 使用共注意力机制将 Geo-Emb 和 Candi-Emb 融合,生成图表示 Graph-Emb。这一步结合了地理信息和候选节点信息,增强了模型对轨迹点的潜在道路片段的理解。
输出:轨迹感知的图嵌入 Graph-Emb,它集成了路网的地理和轨迹候选信息,供后续模块使用。
(b) Spatiotemporal Trajectory Representation(时空轨迹表示)
输入:
- 低采样率轨迹(Input_2):轨迹点数据,包含GPS位置和时间戳信息。
- 地理栅格信息(Input_3):包括网格ID和相对坐标,用于表示空间位置。
处理过程:
-
时间嵌入(Time-Emb):
- 利用每个轨迹点的时间信息生成时间嵌入(Time-Emb),通常通过位置编码等方式来捕捉时间特征。
-
空间嵌入(Spatial-Emb):
- 利用地理栅格信息生成空间嵌入(Spatial-Emb),将轨迹点的空间位置嵌入到模型中。这一步帮助模型理解每个轨迹点的空间位置关系。
-
轨迹嵌入(Traj-Emb):
- 将时间嵌入和空间嵌入进行拼接,生成每个轨迹点的时空表示(Traj-Emb)。这种组合表示确保轨迹点包含时间和空间的联合信息。
输出:低采样率轨迹嵌入 Traj-Emb,结合时间和空间信息,为后续的序列到序列模型提供时空上下文。
(c) Spatiotemporal Interval-Informed Seq2Seq(时空间隔知晓的Seq2Seq模型)
输入:
- 低采样率轨迹表示(来自模块 (a) 和 (b) 的输出,Graph-Emb 和 Traj-Emb 合并后得到)。
- 初始GRU隐藏状态 $ h_{gru}^{(0)} $:初始化的GRU隐藏状态。
处理过程:
-
Attention-Enhanced Transformer Encoder:
- 将低采样率轨迹表示输入到注意力增强的Transformer编码器中。编码器由多头注意力机制(包括查询、键和值)和全连接层(FFN)组成。
- 在多头注意力机制中,编码器计算轨迹点之间的相关性,帮助模型捕捉到时空依赖性。
- 编码器还考虑了轨迹点之间的时间间隔和地理距离,利用它们来增强时空关系的表示。
-
特征差分感知解码器(Feature Differences-Aware Decoder):
- 解码器部分通过GRU单元逐步生成高采样率轨迹点。每个时间步使用前一时间步的输出,结合特征差异信息来生成下一个轨迹点。
- 时空间隔信息(ΔTid 和 Distance):在解码过程中,模型利用每个时间步与前一时间步的时间和空间间隔信息,动态调整注意力权重,使预测更为精准。
- 解码输出:在每个时间步,解码器生成轨迹点的高采样率输出,包括预测的道路片段ID $ e^{(i)} $ 和移动比率 $ r^{(i)} $。
输出:高采样率轨迹 High-Sampling Trajectory Output,即恢复的完整轨迹,包含每个轨迹点的精确位置和道路片段ID。
总结
- 模块 (a):利用路网和轨迹数据生成图表示(Graph-Emb),结合地理和候选节点信息,为模型提供轨迹点的空间上下文。
- 模块 (b):通过时间和空间嵌入生成低采样率轨迹的时空表示(Traj-Emb),帮助模型理解轨迹点的时空分布。
- 模块 (c):结合 (a) 和 (b) 的输出,通过时空间隔知晓的Seq2Seq模型实现轨迹恢复,逐步生成完整的高采样率轨迹。
这种设计确保了轨迹恢复过程中,模型充分利用时空信息和路网的结构特性,提升轨迹预测的精确度。
ITPNET: TOWARDS INSTANTANEOUS TRAJECTORY PREDICTION FOR AUTONOMOUS DRIVING
数据
该文章的目标是多模型轨迹预测,具体来说是预测目标车辆的未来轨迹。文章提出了一种方法,通过利用仅两个观察到的位置(即当前时刻和前一个时刻的位置),来推测目标车辆在未来可能的运动路径。相比于传统方法需要较长的历史轨迹(通常是20个观察位置),该方法只需少量的输入数据,以进行瞬时轨迹预测,从而在推理过程中更为高效和实时。
以下是几个关键点:
-
输入数据:
- 已观察位置序列 $ X^{\text{obs}} = {x_1, x_2} $:这是目标车辆最近的两个已知位置,输入维度为 $ R^2 $,即每个位置都包含二维坐标。
- 未观察位置序列 $ X^{\text{unobs}} = {x_{-N+1}, x_{-N+2}, \dots, x_0} $:代表在两个已观察位置之前的历史轨迹(未观察位置)。其中 $ N $ 是未观察位置的总数量。
-
预测目标:
- 未来真实轨迹 $ X^{\text{gt}} = {x_3, x_4, \dots, x_{2+M}} $:这是目标车辆在未来 $ M $ 个时间步的真实轨迹。
- 预测的可能轨迹集合 $ {\hat{X}k}_{k=0} $**:模型的目标是预测 $ K $ 条未来可能的轨迹,每条轨迹的形式为 $ {\hat{x}_3^k, \hat{x}4^k, \dots, \hat{x}^k} $,其中 $ k $ 表示不同的可能轨迹。
-
任务挑战:
- 本文的方法试图使用最少的输入(仅两个位置)来预测未来的多条可能轨迹,这与传统方法依赖长时间历史轨迹的做法不同。
综上所述,这篇文章聚焦于一种轻量级的轨迹预测方法,通过仅使用少量观察到的状态信息来进行车辆未来轨迹的多模型预测,这种方法特别适合需要实时预测的场景。
没有road network的数据
从本文的方法和描述来看,它确实是只使用了轨迹数据,而没有涉及路网数据。本文的核心任务是从仅有的两个观察到的轨迹点出发,通过一种称为反向预测的过程来重构未观察到的轨迹特征,然后使用这些重构特征来预测未来的可能轨迹。
以下是数据处理的主要步骤:
-
特征提取和编码:
- 首先,通过一个通用的特征提取器(称为backbone,比如HiVT或LaneGCN)对已观察到的轨迹点进行编码,将轨迹点编码为潜在特征表示。
- 通过特征提取器对观察轨迹数据 \(X^{\text{obs}}\) 进行编码,得到表示 \(V^{\text{obs}} = \{v_1, v_2\}\)。
-
反向预测(Backward Forecasting):
- 由于只观测到两个点,缺乏足够的历史信息,反向预测模块尝试通过已观测的特征去反向重构未观测到的潜在特征 \(V^{\text{unobs}}\)。具体来说,使用一个自监督任务来逐步预测之前的未观测特征点。
- 该反向预测的过程由LSTM模型来完成,以逐点重构未观察的特征表示,得到估计的未观察到的潜在特征表示 \(\hat{V}^{\text{unobs}}\)。
- 为了确保反向预测的准确性,采用了平滑的 \(L_1\)损失和对比损失来优化模型,分别用于特征重构和特征分离。
-
去噪模块(Noise Redundancy Reduction Former, NRRFormer):
- NRRFormer由多个NRR块组成,每个块都包含一个自注意力模块,用于过滤掉反向预测过程中重构特征中的噪声和冗余信息。
- NRRFormer的作用是将估计的未观测特征 \(\hat{V}^{\text{unobs}}\) 进行降噪处理,并与已观测到的特征 \(V^{\text{obs}}\) 一起集成到一个紧凑的查询嵌入中,以便提取有意义的信息。
-
轨迹预测:
- 最后,将降噪后的查询嵌入输入到解码器中,解码器根据当前的查询嵌入生成多条未来轨迹的预测。
- 采用一种“胜者为王”的策略,从多个预测中选择最接近真实轨迹的预测,以提高预测的准确性。
从整体来看,该方法通过反向预测和噪声去除模块来应对少量观察轨迹点带来的信息不足问题,没有使用路网数据。
decoder-only类似于
在这篇文章的方法中,NRRFormer(Noise Redundancy Reduction Former)模块的主要目的是利用自注意力机制对反向预测生成的未观测特征进行去噪,同时集成已观测到的特征和预测未来轨迹的特征,从而为后续轨迹预测任务生成一个更可靠和紧凑的查询嵌入。
下面是NRRFormer的具体实现方式及去噪过程的解读:
1. 输入组成
- 未观测的估计特征(\(\hat{V}^{\text{unobs}}\)):这些特征是通过反向预测生成的,可能带有一定的噪声和不准确性。
- 已观测的特征(\(V^{\text{obs}}\)):这两个特征是轨迹的真实观察数据,没有噪声。
- 未来的目标特征:这是NRRFormer的目标,即生成一个查询嵌入,用于预测未来的轨迹。
2. 去噪和特征融合的实现过程
-
步骤 1:自注意力机制对未观测的估计特征去噪:
- 首先,NRRFormer的每个块会使用一个自注意力机制,将未观测的估计特征\(\hat{V}^{\text{unobs}}\)与一个查询向量\(Q\)进行关联。这时的查询向量(Q)初始化为随机向量。
- 由于\(\hat{V}^{\text{unobs}}\)的长度较长,而\(Q\)的长度较短(通常设置为单个向量或少量维度),这种设计让自注意力机制强迫\(\hat{V}^{\text{unobs}}\)的信息浓缩进\(Q\)中。这一步能够起到去噪的作用,因为只保留了未观测特征中对预测有用的信息。
- 这一步不依赖于外部监督标签,属于一种自监督的降噪过程。
-
步骤 2:结合已观测特征的信息:
- 经过去噪后的查询向量\(\hat{Q}_{\text{unobs}}\)与已观测的特征\(V^{\text{obs}}\)再次通过一个自注意力模块进行整合。
- 此过程融合了未观测特征的精华部分和已观测特征,进一步增强了查询向量的代表性,确保它包含了过去的观测信息和有用的预测信息。
-
步骤 3:反复堆叠的NRRBlocks:
- 多层NRRBlocks叠加能够多次重复上述去噪和信息融合的过程,使得噪声信息逐渐减少,而有用信息逐步被提取到查询嵌入中。
- 最终的查询嵌入\(Q_L\)携带了未观测特征、已观测特征的浓缩信息,成为一个可靠的输入嵌入,供后续轨迹预测使用。
3. 是否使用监督标签
- 没有直接使用监督标签:NRRFormer的去噪过程主要依赖自注意力机制和嵌入信息的浓缩,而不是基于外部的监督信号。这是一种无监督的降噪设计,因为它没有用到真实的未来轨迹作为标签来优化降噪过程。
- 不过,NRRFormer的输出查询嵌入会在最终的轨迹预测模块中得到评估,而轨迹预测模块使用了回归和分类损失函数来指导整体模型的优化。因此,从全局角度来看,NRRFormer的参数会受到最终轨迹预测目标的间接影响,但去噪本身没有明确的监督标签。
4. 轨迹预测的输入
- 轨迹预测模块输入的不是单独的未观测、已观测和未来特征,而是NRRFormer生成的最终查询嵌入\(Q_L\)。
- 这个查询嵌入\(Q_L\)已经浓缩了未观测特征的精华、已观测特征的信息,经过去噪和信息融合后,代表了对未来轨迹的预测需求。因此,在轨迹预测模块中,直接使用\(Q_L\)进行解码,预测未来轨迹的多个可能路径。
总结
NRRFormer通过自注意力机制来去除未观测特征中的噪声,将其精华部分与已观测特征融合,生成一个查询嵌入 \(Q_L\)。在预测未来轨迹时,直接使用\(Q_L\)作为输入,而不是单独的未观测、已观测和未来特征。NRRFormer的去噪过程是无监督的,但最终查询嵌入会在预测任务中受到间接的监督信号指导。
ControlTraj: Controllable Trajectory Generation with Topology-Constrained Diffusion Model
数据
是的,这段内容确实包含了两种数据:
-
Road Segments (Road Network Data): 这部分数据定义了路网结构,表示为一系列连接的线段(两个或多个 GPS 点连接形成的线段),每个线段包含起点和终点的经纬度信息。路网的拓扑结构反映了道路的物理连接方式,这类数据可以从公开数据源(例如 OpenStreetMap)中获取,用于定义道路的空间布局。
-
Trajectory (Trajectory Data): 这部分数据定义了轨迹,轨迹是由 GPS 点序列构成的,每个点包含经度、纬度和时间戳信息。轨迹数据通常表示某个目标(例如车辆或行人)的移动路径。
目标
这篇文章的目标是构建一个可控的轨迹生成器,能够在给定的路网拓扑约束下生成多个符合实际情况的轨迹。生成的轨迹需要符合路网的拓扑结构,具有现实性和良好的泛化能力。这意味着生成的轨迹不仅仅需要遵循实际道路网络的限制,还需要看起来真实合理,可以在不同的路网环境中应用。
框架 (结合两种transformer)
是的,Pre-trained RoadMAE 和 Geo Attention 确实是两个不同的模块,它们各自基于不同的 Transformer 机制来处理数据。
1. Pre-trained RoadMAE
-
结构:RoadMAE 是一种基于 Transformer 的自编码器(Autoencoder),专门用于处理道路网络数据。它类似于传统的 Transformer 编码器和解码器架构,主要包括多头自注意力(Multi-Head Self-Attention)和多层感知机(MLP)等层结构。
-
功能:RoadMAE 的主要功能是对道路段(Road Segments)进行编码,将道路的拓扑结构、空间信息等特征捕捉并编码为嵌入表示。在训练过程中,它会对道路段生成带有空间上下文的细粒度表示,特别是通过masking(掩码)机制让模型能够学习在部分信息缺失的情况下推测道路的整体结构。
-
目标:在预训练过程中,RoadMAE 通过重建被遮盖的道路片段来学习道路拓扑结构。这种结构化的空间信息为后续轨迹生成提供了一个强约束条件,使得生成的轨迹符合道路网络的约束。
2. Geo Attention
-
结构:Geo Attention 是一个带有地理空间上下文的注意力机制,它也采用了 Transformer 结构,但其功能和关注点与 RoadMAE 不同。Geo Attention 的主要设计目的是在轨迹生成过程中,引入道路拓扑信息和行程属性,通过逐步降低噪声,生成符合道路网络约束的轨迹。
-
功能:Geo Attention 的注意力机制主要是处理轨迹生成中的每一步,结合地理位置信息和道路约束条件对生成的轨迹进行优化。它关注的不仅是单步的轨迹点,还要结合道路结构信息和上下文信息,使得每一步的轨迹预测更符合真实道路路径。
-
实现:Geo Attention 模块使用了带条件嵌入的注意力机制,包括自注意力(Self-Attention)和条件注意力(Conditional Attention)。自注意力机制用于捕捉轨迹生成过程中轨迹点之间的依赖关系,而条件注意力将道路和行程属性作为条件,确保生成的轨迹点符合约束。
区别与配合
- RoadMAE 作为预训练模块,专注于对道路网络的结构和空间特性进行编码。它的输出是一个包含道路拓扑信息的嵌入,用于指导生成轨迹时的约束。
- Geo Attention 则在实际生成轨迹时起作用。它结合道路的拓扑约束和实时生成的轨迹点进行条件指导,确保每一步生成的轨迹点都符合地理空间的限制。
因此,RoadMAE 和 Geo Attention 是两个不同的 Transformer 模块,它们分别在数据处理的不同阶段承担特定任务,互相配合完成道路约束条件下的轨迹生成。
是的,根据文章的描述,输入数据包括了轨迹数据和路网数据。具体来说,轨迹数据记录了车辆的历史行驶路径(包含车辆在不同时间的地理位置),而路网数据则包括道路段(road segments)的拓扑信息、属性(如类型、长度、宽度等)、以及相邻道路之间的连接关系。这些数据共同为轨迹生成和恢复提供了基础。
两个自注意力模块及其处理的数据
-
Motion-GAT 模块:
- 处理的数据:主要处理的是路网数据,具体是道路段的空间信息和运动关系(例如左转、右转、直行等)。
- 功能:该模块通过自注意力机制聚合了当前道路段与其相邻道路段的信息,生成每个道路段的增强表示。它不仅关注当前道路段的静态属性,还通过引入运动关系向量来表示道路之间的转向关系(如从道路段 A 到道路段 B 是右转还是左转)。
- 目标:通过聚合相邻道路段的信息,Motion-GAT 能够捕捉到复杂的道路网络结构,并在每个道路段的表示中融合邻近道路的特征。这种机制有助于在轨迹恢复时为模型提供更加精确的路网结构信息,使得生成的轨迹能够更好地遵循道路网络的约束。
-
OD-Attention 模块:
- 处理的数据:主要处理轨迹数据,尤其是历史的 OD(起点-终点)对数据,提取驾驶习惯。
- 功能:该模块利用自注意力机制在历史 OD 配对中提取驾驶习惯特征。具体而言,它计算当前 OD 配对与历史 OD 配对之间的相似性,并通过多头注意力机制选择性地将相似的历史 OD 特征融入到当前轨迹的表示中。
- 目标:OD-Attention 的目的是通过历史轨迹中的驾驶习惯(例如,某个驾驶员在特定路段的偏好路径)来指导当前轨迹的生成,使得生成的轨迹更符合驾驶行为模式。这样,模型在生成轨迹时可以考虑到驾驶习惯,从而增加生成路径的合理性和真实性。
总结
- Motion-GAT 模块主要是基于路网数据的空间和运动信息,聚合了当前道路段及其相邻道路段的信息,用于捕捉道路网络的拓扑结构和相邻关系。
- OD-Attention 模块主要基于轨迹数据中的历史 OD 配对,通过学习驾驶习惯特征来增强轨迹生成的合理性,使得生成的轨迹更符合历史行驶模式。
这两个模块的自注意力机制分别在空间(路网)和行为(驾驶习惯)上增强了轨迹恢复的准确性,确保生成的轨迹不仅遵循道路网络的结构约束,还符合车辆的历史驾驶习惯。
CausalTAD: Causal Implicit Generative Model for Debiased Online Trajectory Anomaly Detection
在这篇论文的 Road-constrained Prediction 部分中,确实使用了轨迹数据和路网数据。具体来说,路网数据在轨迹预测过程中扮演了重要角色,以限制和约束轨迹预测的范围。这是通过以下方法实现的:
-
输入数据的组成:输入包含轨迹数据(trajectory data)和路网数据(road network data)。轨迹数据提供了路径的起点、终点和每个时间步的具体路径段信息。路网数据提供了每个道路段的邻接关系,使得预测可以受到这些邻接关系的限制。
-
两个关键自注意力模块:
- TG-VAE(Trajectory Generation VAE):这个模块用来估计轨迹的概率 $ P(c, t) $。在进行轨迹生成时,TG-VAE会使用道路约束来确保轨迹的生成符合实际道路网络。例如,预测下一个路径段时,仅限于当前路径段的邻居,从而减少预测过程中的路径偏移。
- RP-VAE(Road Preference VAE):该模块用于估计每个路径段的偏好(scaling factor),从而解决由道路偏好带来的偏差问题。RP-VAE通过变分自编码器(VAE)结构来生成道路偏好的嵌入,并对路径段进行约束。这种约束确保了不同路径段的偏好能够合理分布在整个路网中。
-
模块如何处理不同数据:
- TG-VAE专注于轨迹生成,使用轨迹数据进行生成任务,通过邻接路径段的约束(来自路网数据)来避免不合理的预测。
- RP-VAE专注于路段偏好计算,主要使用路网数据构建每个路段的特定偏好嵌入,并通过采样和变分推断来获得估计值,进一步对轨迹生成过程中的偏好进行因果消偏。
结论
在Road-constrained Prediction中,轨迹数据用于构建和生成路径的实际轨迹,而路网数据用于提供约束,确保轨迹生成符合道路结构的合理性。两个自注意力模块分别处理不同的数据来源,TG-VAE主要针对轨迹的生成,而RP-VAE用于校正道路偏好,从而实现无偏的轨迹异常检测和预测。这种方法结合了轨迹数据和路网数据,以增强预测的精度和可靠性。
G2LTraj: A Global-to-Local Generation Approach for Trajectory Prediction
数据 (只包含轨迹数据),不包含road network
好的,让我们从输入的轨迹数据开始,详细描述模型是如何处理轨迹数据的,以达到精准的未来轨迹预测效果。
1. 输入的轨迹数据表示
在这篇文章的轨迹预测任务中,输入是目标代理(interested agent)在过去时间段内的观测轨迹。这个轨迹数据通常包含该代理在不同时间步的坐标信息:
其中:
- $ (x_i, y_i) $ 表示在时间步 $ i $ 代理的位置坐标。
- $ T_p $ 是历史轨迹的长度。
在输入的场景中,除了目标代理的轨迹数据之外,还可能包含环境中其他代理的信息(如位置、速度等)和地图信息(如道路或障碍物的位置),这部分信息在模型中被简化地表示为 $ S $。
2. 编码器提取代理特征
模型首先通过一个编码器对输入的轨迹数据和其他信息进行编码,以提取出代表目标代理状态的特征向量 $ A $。编码器可以使用现有的轨迹预测网络(如基于LSTM、GRU或图神经网络的编码器)来处理轨迹信息。
其中,$ G $ 表示编码器,它将历史轨迹 $ P $ 和其他信息$ S $ 作为输入,输出特征向量 $ A $。该特征向量 $ A $ 表示了当前时间步上代理的状态,包括其位置信息、速度信息等。这些特征将用于未来轨迹的预测。
3. Global-to-Local 生成方法
模型的创新之处在于Global-to-Local 生成方法。该方法分为两个阶段:
- 全局关键点生成:首先生成未来轨迹的关键时间步。
- 局部递归生成:利用全局生成的关键点逐步预测中间点,完成整个轨迹的生成。
3.1 全局关键点生成
在这个阶段,模型将未来轨迹分段处理。关键点的生成粒度设为 $ L $,即每隔 $ L $ 个时间步生成一个关键点。这些关键点用来划分轨迹的局部区段。
生成关键点的集合为:
其中 $ N $是生成的关键点数量(确保关键点的数量能够覆盖未来轨迹的长度 $ T_f $)。接着,模型通过两层 MLP $\psi_L $ 生成关键点的坐标:
其中:
- $ A $ 是从编码器得到的代理特征。
- $ \hat{Z} \in \mathbb{R}^{(N+1) \times 2} $ 表示所有关键点的坐标。
为了保持关键点之间的合理性和一致性,引入了空间约束损失 $ L_s^L $,该损失项会迫使生成的关键点之间的距离接近真实轨迹的关键点之间的距离。
3.2 局部递归生成
在生成了全局关键点之后,模型进入局部递归生成阶段,用来填充每个区段的中间点。在这一步中,模型不仅依赖于生成的关键点,还引入了代理特征 $ A $,即通过编码器提取的历史运动信息。这样做的目的是确保生成的中间点在时间和运动学上与历史轨迹保持一致。
具体来说,给定一个区段的起始点 $t_i $ 和终止点 $ t_j $,中间点的生成公式为:
其中:
- $ p_i $ 和 $ p_j $ 是起始和终止点的时间位置嵌入。
- Projection 是一个投影层,结合了起始点、终止点、时间嵌入和代理特征 $ A $ 来生成中间点的坐标。
该过程以递归的方式填充所有中间点,最终生成整个轨迹。
4. 置信度得分计算
模型采用多种粒度的关键点生成不同粒度的未来轨迹预测。通过这种方式,可以得到一组不同的预测轨迹。为了选择最优的预测轨迹,模型计算每条轨迹的置信度得分,并选择置信度最高的轨迹作为最终结果。
给定每条生成的轨迹 $ \hat{F}_{2m} $,其置信度得分计算公式为:
其中:
- ADE(Average Displacement Error)表示预测轨迹与真实轨迹之间的平均L2距离。
- 置信度得分越高,表示该预测轨迹越接近真实轨迹。
最终的预测结果选择置信度最高的轨迹。
5. 损失函数和模型优化
模型的最终损失函数结合了以下几部分:
其中:
- $ L_G $ 是模型的基础损失,用于优化轨迹的生成。
- $ L_{s_i}^2 $ 是空间约束损失,确保关键点的空间一致性。
- $ L_c $ 是置信度得分的回归损失,确保选择的轨迹最优。
总结
- 轨迹数据处理从输入的历史坐标开始,经过编码器提取特征,再通过Global-to-Local方法生成未来轨迹。
- Global-to-Local生成方法分为两个阶段,全局生成关键点,局部生成中间点,确保轨迹生成过程连贯。
- 置信度得分计算用于在不同粒度的生成结果中选出最优的预测轨迹,提升预测精度。
粒度 (下采样)
是的,文中提到的“不同粒度”指的正是 Global-to-Local 生成方法中的粒度(granularity)。
在 Global-to-Local 生成方法中,粒度(granularity) $L $ 是指全局关键点生成的时间间隔,即在未来轨迹预测过程中,每隔 $ L $ 个时间步生成一个关键点。例如,设 $ L = 8 $,意味着每 8 个时间步生成一个关键点,这些关键点划分出轨迹的多个局部区段。
为什么需要不同粒度?
不同的粒度能够适应不同类型的运动轨迹:
-
较粗的粒度:适用于运动特征比较平稳的轨迹,例如以恒定速度和方向行驶的情况。在这种情况下,较大的时间间隔(如 $ L = 8 $)依然能够准确捕捉整体轨迹。
-
较细的粒度:适用于运动特征变化较快的轨迹,例如频繁转弯或加速的情况。此时,需要较小的时间间隔(如 $L = 2 $)生成更多关键点,以更精确地捕捉运动变化。
如何应用不同粒度?
模型首先在最小的粒度(如 $ L = 2 $)下生成关键点序列,然后逐步对其进行下采样,生成一系列不同粒度的关键点集合。例如,给定未来轨迹长度 $ T_f $:
- 细粒度(L=2):生成关键点集合 $G_{L=2} = {t_1, t_3, \dots, t_{T_f}} $
- 中等粒度(L=4):对 $ G_{L=2} ) 进行下采样,得到关键点集合 ( G_{L=4} = {t_1, t_5, \dots, t_{T_f}} $
- 更粗粒度(L=8):继续下采样,得到关键点集合 $ G_{L=8} = {t_1, t_9, \dots, t_{T_f}} $
如何使用不同粒度的轨迹?
在生成了不同粒度的轨迹之后,模型会基于每条轨迹的置信度得分来选择最优的轨迹。这一过程如下:
- 计算每条轨迹的置信度得分,即预测轨迹与真实轨迹的相似度(通过平均位移误差 ADE 计算)。
- 选择置信度得分最高的轨迹,作为最终的预测结果。
这种策略能够根据轨迹的复杂性动态选择适当的粒度,提高了模型在不同运动模式下的适应性,使得预测结果既准确又符合运动规律。
Characterized Diffusion and Spatial-Temporal Interaction Network for Trajectory Prediction in Autonomous Driving
处理不同的轨迹
这里的代理是指,处理不同轨迹之间的联系么?
是的,在这里“代理”(agent)指的是参与轨迹预测任务的不同对象或实体,通常代表车辆、行人等在同一场景中的移动对象。处理不同代理之间的联系主要目的是捕捉它们之间的空间和时间交互关系,以便模型能够更准确地预测目标代理(例如,目标车辆或行人)的未来轨迹。
具体来说,这里的模型并不是仅仅处理单个轨迹的时间序列,而是考虑了多个代理的轨迹(例如,邻近的车辆或行人)的时空关系。通过引入不同代理之间的交互,模型能够更好地理解它们的运动行为模式,从而捕捉到一个代理的运动如何受到其他代理的影响。
模型中的代理联系处理方式:
- Temporal Encoder:为每个代理提取其独立的时间特征,捕捉其在时间维度上的依赖性,但此时不涉及代理间的交互。
- Spatial Encoder:利用多头自注意力机制(Transformer中的自注意力模块)来捕捉不同代理之间的空间关系。这里的自注意力机制计算了每个代理与其他代理之间的相似性,生成注意力分数,从而体现了一个代理如何受到其他代理位置和状态的影响。
- ST Fusion:进一步结合了空间和时间特征,将不同代理之间的交互关系整合到一个长时空特征中,以便后续的解码器使用。
在这种架构下,模型能够在轨迹预测时不再仅仅依赖目标代理本身的历史轨迹数据,而是借助邻居代理的轨迹信息来进行更准确的预测。这种方法在密集或复杂场景(例如多车道交通或行人密集区域)中尤其有效,因为它能够捕捉代理之间的潜在避让、跟随或协同运动模式,从而预测出更合理的未来轨迹。
框架
是的,这里确实只使用了轨迹数据,而没有使用路网数据。
以下是该模型中 Space-Time (ST) Interaction Module 的工作原理,特别是各个模块如何处理轨迹数据的详细说明:
1. Temporal Encoder
功能:提取目标代理和邻居代理的时间依赖特征。
- 输入:输入的是每个代理在每个时间戳的历史状态 $ x_t $。
- 处理过程:
- 通过一个全连接层,将历史状态 $ x_t $ 转换为时间嵌入向量 $ F_t $:
\[ F_t = \delta(\varphi(x_t, W_{\text{emb}})) \]其中,$ \delta \(表示全连接层,\) \varphi $是 LeakyReLU 激活函数。
2. 使用一个 RNN(递归神经网络,如 LSTM 或 GRU),基于前一个时间戳的隐藏状态 $ h_{t-1} $ 和当前时间戳的嵌入向量 $ F_t $,更新每个时间戳的隐藏状态 $ h_t $:\[h_t = f_{\text{tem}}(F_t, h_{t-1}, W_{\text{init}}) \]其中,$ W_{\text{init}} $ 是可学习参数矩阵,$ f_{\text{tem}} $ 表示用于时间编码的递归神经网络。
3. 最终得到目标代理的时间特征矩阵 $ H_0 \in \mathbb{R}^{T_p \times D} $和每个邻居代理的时间特征矩阵 $ H_i \in \mathbb{R}^{T_p \times D} $。
2. Spatial Encoder
功能:提取代理之间的空间关系。
- 输入:从 Temporal Encoder 得到的时间特征矩阵 $ H $。
- 处理过程:
- 使用多头自注意力机制,将各个代理的时间特征作为查询、键和值矩阵:\[Q, K, V = f_{\text{sp}}(H, H, W_q, W_k, W_v) \]其中,$ f_{\text{sp}} $ 表示空间注意力,$ W_q, W_k, W_v $ 是可学习的参数矩阵。
- 计算注意力分数 ( \omega ),表示不同代理之间的相似性:\[\omega = \Pi \left( \frac{Q \cdot K}{\sqrt{D_{\text{init}}}} \right) \]其中,$ \Pi $ 表示归一化操作,用于表示代理之间的相互影响。
- 通过矩阵乘法,利用注意力分数来捕捉重要的代理之间的关系,生成单头注意力输出 ( \upsilon ):\[\upsilon = \omega \cdot V \]
- 使用多头注意力机制(multi-head attention)获得综合的空间关系 $ \Upsilon = [\upsilon_1, \upsilon_2, \dots, \upsilon_n] $。
- 引入一个门控机制 $ H_g $,用于控制每个头的权重,选择性地增强或抑制特定的头输出:\[H_a = \kappa(\Upsilon), \quad H_g = \sigma(\kappa(\Upsilon)), \quad S = H_a \odot H_g \]其中,$ \sigma $ 是 Sigmoid 激活函数,$ \kappa $ 是线性层,$ \odot $ 表示元素乘操作,最后的输出 $ S \in \mathbb{R}^{T_p \times D} $ 是每个时间步的空间编码。
- 使用多头自注意力机制,将各个代理的时间特征作为查询、键和值矩阵:
3. ST Fusion
功能:融合时空信息,进一步捕捉时空交互特征。
- 输入:来自 Spatial Encoder 的输出 $ S $。
- 处理过程:
- 再次应用自注意力机制,通过 $ f_{\text{ST}} $ 函数将 $ S $ 转换为查询、键和值矩阵:\[Q', K', V' = f_{\text{ST}}(S, W'_q, W'_k, W'_v) \]其中,$ W'_q, W'_k, W'_v $ 是新的可学习参数矩阵。
- 类似于 Spatial Encoder 中的操作,使用归一化和门控机制来生成最终的长时空特征 $ U $:\[U = [u_{-T_p+1}, u_{-T_p+2}, \dots, u_0] \in \mathbb{R}^{T_p \times D} \]这些特征综合了空间和时间信息,捕捉了目标代理和邻居代理之间的交互。
- 再次应用自注意力机制,通过 $ f_{\text{ST}} $ 函数将 $ S $ 转换为查询、键和值矩阵:
4. Decoder
功能:基于之前生成的特征预测未来轨迹。
- 输入:空间和时间交互特征 $ U $ 以及目标代理的历史轨迹。
- 处理过程:
- 使用 LSTM 作为解码器,根据长时空特征 $ U $ 和上一时间步的预测坐标 $ \hat{y}_{t-1} $,递归地预测未来的 2D 空间坐标 $ \hat{y}_t $:\[\hat{y}_t = f_{\text{LSTM}}(U, \hat{y}_{t-1}, W_{\text{decoder}}) \]其中,$ W_{\text{decoder}} $ 是 LSTM 解码器的参数矩阵。
- 通过简单的 LSTM 解码器即可预测未来轨迹,保证了模型的参数较少但预测准确。
- 使用 LSTM 作为解码器,根据长时空特征 $ U $ 和上一时间步的预测坐标 $ \hat{y}_{t-1} $,递归地预测未来的 2D 空间坐标 $ \hat{y}_t $:
总结
这个 ST-block 模块通过交替编码时间和空间信息,有效地捕捉了代理之间的时空交互关系。Temporal Encoder 关注单个代理的时间依赖性,Spatial Encoder 则通过 Transformer 自注意力机制捕捉代理间的空间关系。随后,ST Fusion 进一步结合时空特征,为 LSTM 解码器提供了丰富的信息,使得该模型能够在没有路网数据的情况下实现轨迹预测。
More Than Routing: Joint GPS and Route Modeling for Refine Trajectory Representation Learning
是的,这篇文章使用了轨迹数据和路网数据。
数据类型
- 轨迹数据:文章使用GPS轨迹数据(GPS Trajectory),包含GPS点序列,每个点记录了经纬度和时间戳。这个数据用于捕捉对象的移动路径。
- 路网数据:路网数据(Road Network)表示为有向图结构,其中节点代表路段,边代表路段之间的连接。路网数据提供了地理和拓扑结构,用于辅助理解对象的移动路径在道路上的映射。
模型结构
在模型的框架图中,分成了两条处理路径,分别对应不同的数据:
-
上半部分:处理轨迹的GPS Encoder
- 使用了双向GRU(BiGRU)进行编码。这一模块分为两级结构:
- Intra-road BiGRU:对每个子轨迹(sub-trajectory)内的GPS点进行编码,捕捉每个路段内的时间序列特征。
- Inter-road BiGRU:对路段序列进行编码,捕捉不同路段之间的序列依赖关系。
- 这种双重BiGRU结构可以确保轨迹数据中不同路段之间的依赖关系,同时减少噪声和冗余信息的影响。
- 使用了双向GRU(BiGRU)进行编码。这一模块分为两级结构:
-
下半部分:处理路网的Route Encoder
- 使用了图注意力网络(GAT)来更新和增强路段的表示。具体来说:
- 使用GAT层对路网进行信息传递,以捕捉路段之间的空间依赖关系。每个路段(节点)的表示向量会根据相邻路段的信息进行更新,从而得到更具拓扑信息的表示。
- 此外,还对路段的时间信息进行了编码,使用了多个时间特征(如分钟索引、周索引和实际行驶时间)来捕捉交通的时变特性。然后,这些包含时间和空间信息的路段表示被输入到Transformer编码器中,以进一步优化和精炼表示。
- 使用了图注意力网络(GAT)来更新和增强路段的表示。具体来说:
总结
- 上半部分的BiGRU模块用于处理和提取轨迹数据的时间序列特征。
- 下半部分的GAT模块用于处理路网数据,捕捉路段之间的拓扑结构和空间关系。
通过这种双视角的设计,模型能够将GPS轨迹和路网信息整合,从而生成更通用和富有信息的轨迹表示,支持自监督学习任务。
这篇文章设计了两种自监督学习任务来训练模型,以增强模型对轨迹和路网数据的表示学习。这些任务分别是:
1. MLM (Masked Language Modeling) - 掩码语言模型任务
在这个任务中,模型会随机掩盖轨迹中的部分子路径(sub-paths),并要求模型重建这些被掩盖的部分。这种掩码语言模型任务主要针对轨迹中路段序列的表示学习。
-
Shared Mask:在GPS轨迹和路网轨迹(Route Trajectory)中,对相同的路段进行掩码,即掩盖相同的子路径,以防止两个视角之间的信息泄露。这种设计保证了两个视角的同步学习。
-
损失计算:模型将尝试通过输出的表示来重建这些被掩盖的路段,并使用交叉熵损失(Cross-Entropy Loss)来计算重建误差,以此作为训练信号。
这种任务的设计有助于模型学习到轨迹和路网中路段的序列关系和结构依赖。
2. CMM (Cross-Modal Matching) - 跨模态匹配任务
跨模态匹配任务的目标是让模型学习如何对齐GPS视角和路网视角的轨迹表示。这里的“模态”指的是GPS和路网两个视角。
-
任务设计:模型要求配对GPS和路网视角中的轨迹表示,这些表示应该对应同一个真实轨迹。当GPS视角和路网视角表示的轨迹匹配时,被认为是正确的匹配;而对于不匹配的对,模型应能区分出这些对不相符。
-
损失计算:对于每个GPS-Route匹配对,模型使用一个二元分类损失来判断是否匹配。为了提高效率,文章简化了计算,仅考虑每次查询中最接近当前轨迹的负样本。
这一任务的设计主要目的是对齐两个视角中的表示空间,帮助模型在不同模态的轨迹表示中学习一致性。
3. 总体损失函数
最终的自监督训练目标是组合MLM损失和CMM损失:
其中,\(w_1, w_2, w_3\) 是用于平衡各任务损失的超参数。
总结
这两种自监督任务使得模型能够从不同视角中捕捉轨迹的特征,学习到轨迹中隐含的时间、空间和拓扑信息,从而增强模型在缺少标注数据情况下的表示学习能力。
Learning to Hash for Trajectory Similarity Computation and Search
做得是检索任务
你理解得很接近,这里是四条轨迹表示的结合与处理。让我们详细分解一下 Hash Layer 的计算过程,以及它如何将四条轨迹聚合成一个最终的哈希表示。
四条轨迹表示
在 Trajectory Augmentation 部分,模型生成了四种不同的轨迹表示:
- GPS轨迹 (T):原始的GPS轨迹。
- 网格轨迹 (Tg):将GPS轨迹映射到网格上得到的轨迹。
- 反转GPS轨迹 (Tr):GPS轨迹的反转版本。
- 反转网格轨迹 (Tgr):网格轨迹的反转版本。
这些不同的表示可以从不同的角度提供轨迹信息,尤其是反转表示有助于保持距离度量的对称性。
Hash Layer的具体步骤
Hash Layer 的主要任务是将这四条轨迹表示聚合并转化为一个统一的哈希表示,用于Hamming空间的相似性检索。
具体计算步骤
-
编码四条轨迹:
首先,通过不同的编码器对这四条轨迹表示进行编码:- GPS轨迹(T)和反转GPS轨迹(Tr)通过
Attention-based Trajectory Encoder进行编码,得到对应的编码表示 $ h_T $ 和 $ h_{Tr} $。 - 网格轨迹(Tg)和反转网格轨迹(Tgr)通过
Light-Weight Grid Representation Encoder进行编码,得到对应的编码表示 $ h_{Tg} $ 和 $ h_{Tgr} $。
- GPS轨迹(T)和反转GPS轨迹(Tr)通过
-
合并同类表示:
每对同类型的轨迹表示(即,GPS轨迹和反转GPS轨迹,网格轨迹和反转网格轨迹)分别通过MLP层进行融合。- GPS轨迹表示 $ h_T $和反转GPS轨迹表示 $ h_{Tr} $ 融合为一个表示 $ h_{T}^{fused} $。
- 网格轨迹表示 $ h_{Tg} $ 和反转网格轨迹表示 $ h_{Tgr} $ 融合为一个表示 $ h_{Tg}^{fused} $。
-
最终融合表示:
将这两个融合表示 $ h_{T}^{fused} $ 和$ h_{Tg}^{fused}$ 进一步通过一个MLP层整合,得到单一的最终融合表示 $ h $。 -
生成哈希码:
将最终融合表示 $ h $ 传入Sign Function(符号函数),将其转换为二进制哈希码$ z_T \(,每个值是\) +1$ 或 $-1 $,这就是在Hamming空间中的哈希表示。这个哈希码可以用于高效的相似性检索。
Hash Layer 的作用
- 反转对称性:通过结合反转版本的表示,
Hash Layer确保了轨迹距离度量的对称性,即反转后的轨迹与原轨迹具有相同的哈希表示。这对于DTW和Frechet等对称距离函数尤其重要。 - 统一哈希表示:
Hash Layer将四种轨迹信息融合成一个统一的表示,既保留了不同增广轨迹的特征,又减少了计算复杂度,使得在Hamming空间中的检索更高效。
总结
Hash Layer 主要将四条轨迹表示(GPS轨迹、网格轨迹及其反转)逐步融合,最终得到一个统一的哈希表示,用于相似性检索。
Trajectory Similarity Measurement: An Efficiency Perspective
这篇文章对比了各种相似性计算的方法
其中有一中构建四叉树的方法
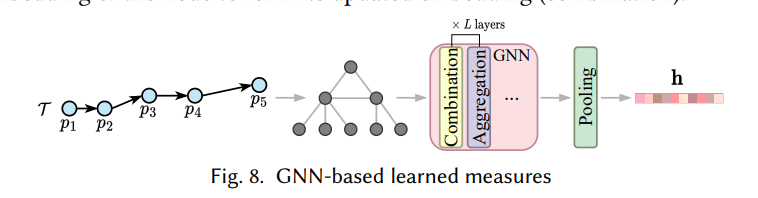
在这里,轨迹被转换成图的过程主要依赖于多层四叉树结构和图神经网络 (GNN) 处理。让我分步骤解释这个转换过程:
-
构建四叉树 (Quadtree):
- 首先,空间被划分成不同大小的单元格(cells),即四叉树结构。这种多层的四叉树允许在不同的尺度上观察轨迹,从而生成多粒度的视图。
- 每一个单元格都可以包含多个轨迹点。根据需要,四叉树可以继续细化单元格,直到达到所需的精细度。
-
生成图节点:
- 将轨迹中的每个轨迹点查询到四叉树中对应的单元格,然后将该轨迹点添加为图中的一个节点。
- 这些轨迹点节点的层级和空间分布信息都保存在图结构中。
-
添加边 (Edges):
- 在图中,轨迹路径中的相邻轨迹点会被连接成边,从而保持轨迹路径的顺序关系。
- 另外,在四叉树结构中相邻的单元格(即空间上相邻的节点)也会被连接,以表示这些轨迹点在空间中的邻接关系。
-
多粒度结构:
- 利用多层四叉树,TrajGAT 可以在多个尺度上构建轨迹图。较小的单元格能够更详细地表示空间关系,而较大的单元格则提供更粗略的视角。
- 这种多粒度的图结构帮助模型捕获轨迹的局部和全局模式。
-
GNN的图嵌入处理:
- 构建完成的图会被输入到 GNN 中进行处理。在每一层 GNN 中,每个节点会从其邻居节点中聚合信息(Aggregation),然后将聚合的信息与自身的嵌入向量结合(Combination),更新其嵌入表示。
- 经过多层 GNN 处理后,每个节点的嵌入向量都会更加丰富地包含轨迹的空间关系信息。
-
Pooling汇总:
- 最后,通过池化 (Pooling) 操作,将图中的所有节点的嵌入表示汇总成一个整体的轨迹表示向量 ( h )。这个向量可以用于后续的相似性度量或其他分析任务。
总结
在这个方法中,轨迹被转化为一个图结构,轨迹点成为图中的节点,相邻点之间用边连接。借助多层四叉树结构实现多粒度视图后,再利用 GNN 对图进行处理,生成包含轨迹空间信息的嵌入表示。
KGTS: Contrastive Trajectory Similarity Learning over Prompt Knowledge Graph Embedding
从描述来看,确实,这个模型使用了轨迹数据(trajectory data),而并没有显式地使用路网数据(road network data)。以下是对其细节的分析:
-
仅使用轨迹数据:文中定义了轨迹(trajectory)作为一系列点的序列,每个点包含纬度和经度信息。整个框架基于将空间划分为网格,并使用网格表示轨迹,而不是依赖具体的路网结构(如路段和交叉口)。具体来说,轨迹点被映射到不同的网格,从而形成基于网格的表示。这些网格之间的关系被建模为一个“知识图谱”(Knowledge Graph),但它不涉及道路网络的拓扑信息,仅仅考虑了相邻网格之间的直接连接。
-
GRU 用于顺序信息编码:在整个模型的最后一步中,使用了一个GRU(Gated Recurrent Unit)来嵌入轨迹网格的顺序信息。GRU是一种常用的循环神经网络,用于捕获序列数据中的时间或顺序依赖性。在这里,GRU负责编码轨迹点的顺序,以生成最终的轨迹嵌入(trajectory embedding)。该嵌入将被用于对比学习,以衡量不同轨迹之间的相似性。
-
对比学习(Contrastive Learning):模型使用对比学习来训练轨迹嵌入模块。在这种方式下,通过生成正样本(即与原轨迹相似的样本)和负样本(与原轨迹不相似的样本)来进行训练,目标是最小化正样本之间的距离,最大化负样本之间的距离。正样本的生成通过一些策略,例如在轨迹的起点或终点添加、删除、移动网格,从而模拟出相似但不完全相同的轨迹。
总结
- 数据类型:该模型只使用了轨迹数据,而没有使用路网数据。它通过将空间划分为网格并利用相邻网格之间的关系来建模空间信息。
- GRU 的作用:GRU用于捕获轨迹的顺序信息,并生成最终的轨迹嵌入。
- 对比学习:通过生成相似和不相似的样本,使用对比学习来优化嵌入空间,使得相似轨迹的嵌入更加接近。
这种方法是基于轨迹数据的网格化和顺序信息的编码,适用于无路网结构的轨迹相似性计算和表示学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号