
Towards Explainable Traffic Flow Prediction with Large Language Models
数据格式
prompt的三种格式
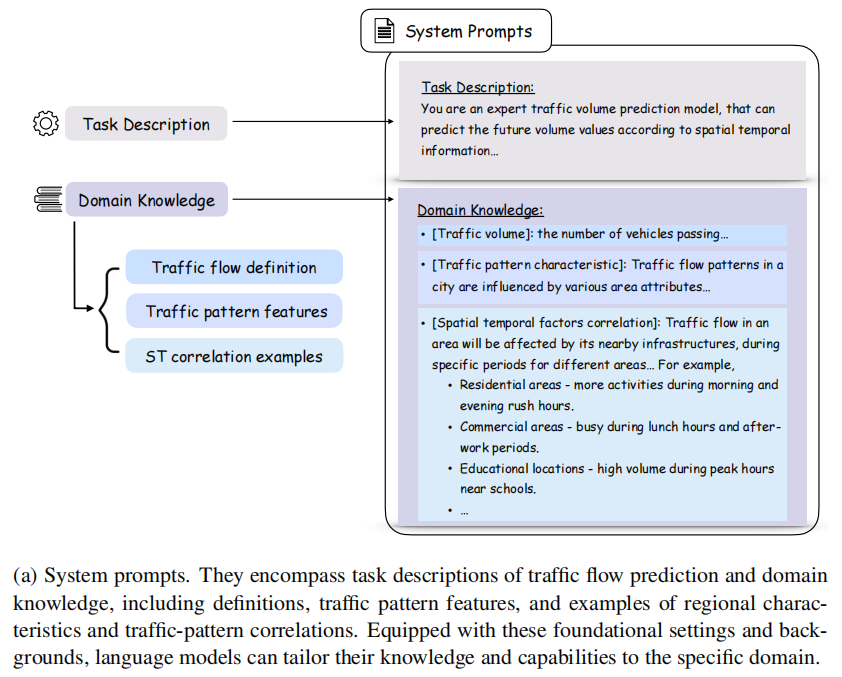
System prompts
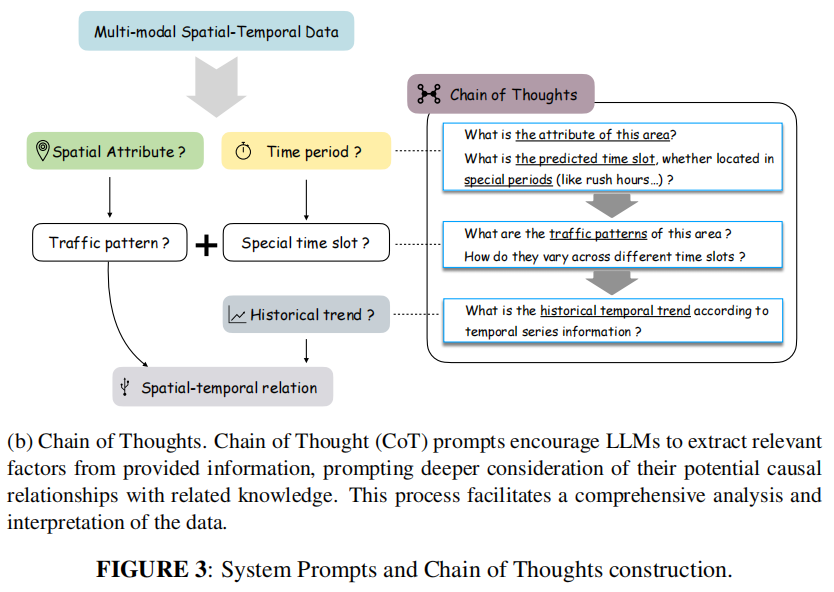
chain-of-thought
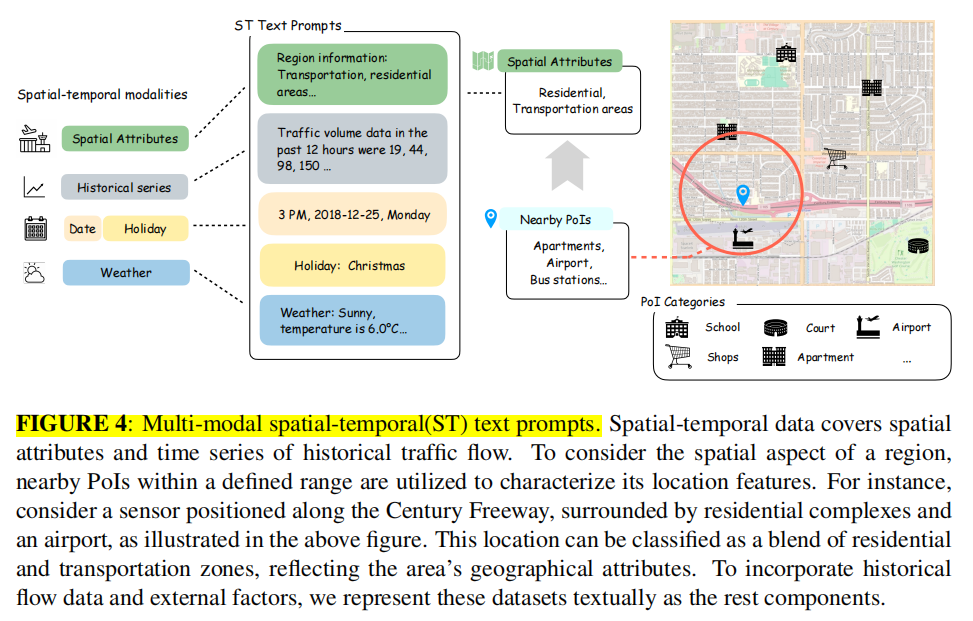
Multi-modal spatial-temporal(ST) text prompts.
<s>[INST]<<SYS>>
Role: You are an expert traffic volume prediction model, that can predict the future volume values according to spatial temporal information. We want you to perform the traffic volume prediction task, considering the nearby environment and historical traffic volume data.
Context knowledge you could consider:
- Traffic volume: the number of vehicles passing a specific region in an hour, usually ranging from 0 to 1000.
- Traffic pattern characteristic: Traffic flow patterns in a city are influenced by various area attributes. Also, traffic volume has a periodic daily and weekly pattern.
- Spatial temporal factors correlation: Traffic flow in an area will be affected by its nearby infrastructures, during specific periods for different areas. You should think about how the volume will change in a specific area, during a specific time.
For examples,
Airports, and train stations - increased volume on weekends and holidays.
Residential areas - more activities during morning and evening rush hours.
Commercial areas - busy during lunch hours and after-work periods.
Educational locations - high volume during peak hours near schools.
Think carefully about the following questions about how spatial-temporal factors affect traffic flow.
- What is the attribute of this area and what is the predicted time zone located in special periods (like rush hours, weekdays, weekends, and holidays)?
- What are the traffic patterns of this area, and what is the change in different time slots?
- What is the historical temporal trend according to temporal information, considering the weekdays, around holidays?
<<\/SYS>>
Some important information is listed as follows:
- Location: District 3 in Yolo, California, USA, along the US50-E freeway, lane 4, direction of eastbound.
- Today's weather: Sunny. Temperature is 6.0°C, and visibility reaches 10.0 miles.
- Region information: including transportation areas, commercial areas and educational areas within a range of 5 km.
- Current Time: 3 PM, 2018-2-19, Monday, Washington's Birthday.
- Traffic volume data in the past 12 hours were 19, 44, 98, 150, 156, 178, 208, 246, 248, 257, 263 and 269, respectively.
According to the above information and careful reasoning, please predict traffic volumes in the next 12 hours (from 4 PM to 3 AM). Format the final answer in a single line as a JSON dictionary like: {Traffic volume data in the next 12 hours: [V1, V2, V3, V4, V5, V6, V7, V8, V9, V10, V11, V12]}.[\/INST]
{Traffic volume data in the next 12 hours: [262, 229, 221, 214, 152, 127, 100, 58, 38, 25, 22, 18]}.
<\/s>
拆分内容的解释
-
标记和说明
<s>和</s>:表示文本的起始和结束,这是模型输入/输出常见的格式。[INST]:指明这是一个指令输入,模型根据这里的指令执行任务。<<SYS>>和<<\/SYS>>:系统提示的开始和结束,定义了模型任务的背景和要求。
-
系统提示 (
<<SYS>>...<<\/SYS>>)- 任务角色:明确模型是一个专家交通量预测模型。
- 背景知识:
- 交通量:每小时通过特定区域的车辆数量,通常范围为 0 到 1000。
- 交通模式特性:交通流量受到城市不同区域特征的影响,并具有日常和每周的周期性。
- 空间-时间因素相关性:交通流量会受到附近基础设施和特定时间段的影响,并举了一些例子(机场、居民区、商业区和教育区等)。
- 思考方向:提示模型在做出预测时需要考虑的因素,包括区域特征、时间段、历史交通模式等。
-
具体输入信息
- 位置:加州尤洛地区第三区,沿 US50-E 高速公路,东向的 4 号车道。
- 天气:晴天,温度为 6°C,能见度 10 英里。
- 区域信息:周围 5 公里范围内包括交通区、商业区和教育区。
- 当前时间:2018 年 2 月 19 日,星期一,华盛顿诞辰纪念日,下午 3 点。
- 过去 12 小时的交通量数据:19, 44, 98, 150, 156, 178, 208, 246, 248, 257, 263, 269。
-
模型任务指令
- 任务:根据以上信息和合理推理,预测未来 12 小时的交通量(从下午 4 点到凌晨 3 点)。
- 输出格式要求:模型输出应是一个 JSON 字典,格式如
{Traffic volume data in the next 12 hours: [V1, V2, ..., V12]}。
-
模型输出结果
{Traffic volume data in the next 12 hours: [262, 229, 221, 214, 152, 127, 100, 58, 38, 25, 22, 18]}:这是模型根据输入信息预测的未来 12 小时交通量数据。
数据处理,转换为token
从 examples 到 output 的处理是一个文本 tokenization 的过程。这里具体进行了以下操作:
-
提取输入文本:
examples[text_column_name]获取了数据集中与text_column_name对应的所有文本数据。这个text_column_name是之前确定的,例如"text"。- 这些文本可能是多个样本的列表,例如
["<s>[INST]<<SYS>>\nRole: You are an expert traffic ...", "another text", ...]。
-
Tokenization:
tokenizer([...], truncation=True, max_length=data_args.block_size, padding=False, return_tensors=None)将这些文本传递给tokenizer进行处理。tokenizer会将每个输入文本转换为一系列的 token ID。这些 ID 是文本中每个单词、符号或子词的编号,取决于 tokenizer 的词汇表。- 具体的参数:
truncation=True:如果输入文本超过max_length,将截断到指定的最大长度。max_length=data_args.block_size:设置每个输入的最大 token 数,超出部分将被截断。padding=False:不进行 padding 操作,这意味着每个样本的长度可能不同。return_tensors=None:返回的是普通的 Python 列表而非张量。
-
生成输出
output:output包含了三个主要字段:input_ids、attention_mask和labels。input_ids:每个输入文本被转换为一系列整数 ID。每个整数表示一个 token。attention_mask:一个布尔数组,用于指示哪些位置是实际的 token,哪些是 padding(如果有 padding 的话)。值为1表示有效 token,0表示 padding。labels:这个是从input_ids复制的,表示每个 token 对应的真实输出。因为是语言模型,labels通常与input_ids相同。
-
labels字段的设置:output['labels'] = output['input_ids'].copy()将input_ids直接复制到labels。这意味着训练时模型会试图预测每个位置的 token,即它是自回归的(每一步都预测下一个 token)。- 这种设置在语言模型训练中比较常见,尤其是
Causal Language Model类型。
总结:
代码从 examples 中提取到每个样本的文本数据,使用 tokenizer 将其转化为 token ID,同时生成 attention_mask 和 labels,最终构造出 output 作为模型的输入。这个过程实现了从原始文本到模型可以理解的数值表示的转化。
自回归的Loss
从您描述的情况来看,如果实际使用的是 tokenize_function 而不是 generate_and_tokenize_prompt,那它的处理方式确实不同。为了理解自回归任务的 loss 是如何设置的,我们需要看一下 tokenize_function 和模型的训练方式。自回归模型通常用于语言模型任务(如 GPT),这些模型是基于语言的生成任务。
1. tokenize_function 处理流程
先看一下 tokenize_function 的代码:
def tokenize_function(examples):
with CaptureLogger(tok_logger) as cl:
output = tokenizer(
[item for item in examples[text_column_name]],
truncation=True,
max_length=data_args.block_size,
padding=False,
return_tensors=None
)
output['labels'] = output['input_ids'].copy()
return output
1.1 分词 (tokenization)
tokenize_function读取examples中的文本数据,将其传递给tokenizer进行分词处理。- 分词的结果会得到
input_ids(词的编码)和attention_mask等信息。 - 重要的是,
output['labels'] = output['input_ids'].copy()。这意味着labels和input_ids是一样的。
- 自回归语言模型的 Loss 配置
对于自回归语言模型来说,模型的任务是根据序列中的前一个词预测下一个词。这种任务的训练方式被称为 自回归(autoregressive)。例如,给定一句话 "I am learning", 模型会学着去预测:
- "I" -> "am"
- "am" -> "learning"
- "learning" -> (句子结束)
具体来说:
input_ids是模型的输入。例如[I, am, learning]。labels是模型的目标输出。比如[am, learning, <eos>]。
3. Loss 的设置逻辑
在自回归任务中,模型的 labels 会用来计算损失。为了达到自回归的效果,labels 需要和 input_ids 进行对齐,并且在某些位置进行移位。
在代码 tokenize_function 中,我们看到这行代码:
output['labels'] = output['input_ids'].copy()
这意味着 labels 和 input_ids 完全相同。由于自回归语言模型使用了 shifted labels 的技术,模型会将 input_ids 中的每个 token 作为输入,并尝试去预测 labels 中下一个位置的 token。模型内部会自动将 labels 向右移位,并计算 cross-entropy loss。
假设 input_ids 是:
["<s>", "I", "am", "learning", "</s>"]
对应的 labels 会被模型自动移位成:
["I", "am", "learning", "</s>", -100]
这里的 -100 表示忽略的位置,在 PyTorch 中,如果 labels 中某个位置是 -100,该位置不会参与 loss 的计算。
Trainer基于labels自动判断loss的计算方式
在 Hugging Face 的 Trainer 框架中,模型的 loss 计算主要依赖于 labels 的设置方式。在你提到的两种不同 labels 配置方式中,Trainer 会根据 labels 的内容自动决定如何计算 loss。下面是具体的机制和如何区分两种情况的解释。
- 自回归 (Causal Language Modeling) Loss

对于自回归任务,如 GPT 系列模型或 LLaMA,这些模型本质上是在做 语言建模,即给定前面的 token,预测下一个 token。这种情况下:
labels是一个与input_ids相同的序列。Trainer的默认行为 是将labels向右移一位,然后计算每个时间步的预测和实际的 token 之间的loss。这种右移的操作通常在model.forward方法内部完成。
示例:
input_ids: [ "Hello", "world", "</s>" ]
labels: [ "Hello", "world", "</s>" ]
在模型内部,这会变成预测下一个 token:
Input: ["Hello"] -> 预测 "world"
Input: ["Hello", "world"] -> 预测 "</s>"
- 目标 (Target) 的 Loss 计算
在你的代码中有另一种设置,即在generate_and_tokenize_prompt中:
- 只有
target_text部分需要计算loss,而input_text的部分labels被设置为-100。-100是一种标记,用来告诉Trainer不要在这些位置计算loss。
例子:
input_text: "Please predict: "
target_text: "This is the answer."
合并后的 `full_prompt`
full_prompt = "Please predict: This is the answer."
对应的 `labels` 设置 (假设 `input_text` 长度为 3)
labels: [-100, -100, -100, "This", "is", "the", "answer", "."]
这样做的结果是,只有 target_text 部分会参与 loss 计算,而 input_text 部分不会。Trainer 通过检测 labels 中的 -100 来忽略对应位置的 loss。
- Trainer 如何判断
Trainer在调用模型的forward方法时,会自动传递input_ids和labels。模型的forward方法会根据labels的内容来决定如何计算loss。
- 对于自回归任务:
labels是完整的 token 序列,模型会尝试预测每个 token。 - 对于目标任务 (target-specific loss):
labels中的某些位置被标记为-100,这些位置的loss会被忽略。
代码中的 Trainer 自动处理这种情况,通过 transformers 内部的 forward 函数机制完成。对于 labels 设置为 -100 的 token,torch.nn.CrossEntropyLoss 会跳过这些位置,不计算 loss。
- 内部机制示例
在transformers框架中,自回归的forward计算通常是这样:
outputs = model(input_ids=input_ids, labels=labels)
loss = outputs.loss # 通过 labels 自动计算的 loss
如果 labels 是:
labels = [-100, -100, -100, "This", "is", "the", "answer", "."]
那么 loss 只会在 -100 以外的位置上计算,从而只让模型学习如何生成 target_text。
- 总结
Trainer判断计算哪种类型的loss,完全取决于labels的内容:
- 完整的
labels:每个 token 都参与loss计算,表示自回归任务。 - 带有
-100的labels:只有指定的 token 参与loss计算,表示只训练target_text,忽略input_text。
通过灵活设置 labels,可以轻松切换模型的训练任务,Trainer 会自动处理这些配置,不需要在 Trainer 中专门区分这两种情况。
模型在推理前的合并,base + Lora,将Lora合并到base中
是的,确实如此。
在这段代码中,执行了以下步骤:
-
PeftModel.from_pretrained(base_model, args.new_model_path):- 这一步是将微调后的 LoRA 参数加载到基础模型(
base_model)中。args.new_model_path指向了存储 LoRA 参数的路径。 - 此时,
new_model包含了base_model(LLaMA)的原始权重和附加的 LoRA 层,但 LoRA 层并没有合并到基础模型的参数中。
- 这一步是将微调后的 LoRA 参数加载到基础模型(
-
new_model.merge_and_unload():- 这一操作将 LoRA 参数合并到基础模型的权重中。在 LoRA 微调中,LoRA 层通过低秩矩阵来修改基础模型的权重,但这些修改是通过在推理时动态计算完成的。
- 合并操作会直接将 LoRA 的修改应用到
LLaMA模型的原始参数中,使得最终模型的权重变成了实际微调后的完整权重,不再依赖额外的 LoRA 层。 - 合并后,
new_model就成了一个包含了微调后的完整LLaMA模型。
-
.eval():- 这是将模型设置为评估模式(
evaluation mode),以确保推理过程中不会进行 dropout 或 batch normalization 的更新。
- 这是将模型设置为评估模式(
预测交通流量任务
- 模型的任务: 虽然使用了文本生成模型 (
task="text-generation"),但实际的应用场景是生成交通流量的数值预测。这表明模型生成的输出主要是未来时间段的交通流量数据。 - 输入和输出: 输入数据是通过从
[INST]...[/INST]中提取出来的指令(例如关于某个特定时间点的历史交通流量数据),输出则是解析生成的数值,并作为未来的流量预测结果。 - 文本与流量预测: 虽然代码使用了文本生成模型,但通过对
generated_text的解析,只保留了数值,因此模型的实际应用并没有生成复杂的文本,而是利用了自回归生成机制来预测未来交通流量数据。
综上所述,代码的预测过程主要针对未来流量数据,输入的信息可能包含上下文的文本描述,但输出主要集中在数值预测上。这种方法使用了文本生成模型的能力,但目标是生成预测数据,而不是典型的自然语言生成任务。
正则表达式的使用
这两个正则表达式在代码中的作用如下:
out = re.findall(r"(\d+)", result['generated_text'])[1:]
-
解释:
- 这个表达式用于从模型生成的
generated_text中提取数字序列。 re.findall(r"(\d+)", result['generated_text'])会匹配所有连续的数字字符,返回一个数字字符串的列表。例如,如果generated_text是"The traffic volumes: [100, 200, 300]",那么匹配结果将是["100", "200", "300"]。[1:]表示从匹配结果的第二个元素(索引为1)开始提取。这意味着它会跳过第一个匹配的数字,只保留后面的数字。
- 这个表达式用于从模型生成的
-
用途:
- 这段代码可能假设模型生成的
generated_text里第一个数字不是需要的流量数据,或者是某种标识符,因此跳过第一个匹配项,只保留后续的数字作为有效的预测结果。
- 这段代码可能假设模型生成的
label_pattern = r"\[/INST\]{Traffic volume data in the next \d+ hours: \[(.*)\]}.</s>"
-
解释:
- 这个正则表达式用于从
text字段中提取标签(真实值,即期望的交通流量数据)。 \[/INST\]匹配[/INST]这段文本,表示这是指令的结束。{Traffic volume data in the next \d+ hours: \[(.*)\]}匹配一个特定的文本模式,其中\d+是一个数字,表示未来多少小时的预测,(.*)表示在方括号[]内匹配任意字符(通常是数字),这些数字即为真实的交通流量数据。.</s>匹配句子的结束符号,确保只提取到标签部分的数据。
- 这个正则表达式用于从
-
用途:
- 这个模式用于从输入的验证数据中提取真实的交通流量数据,以便在后续的评估中与模型的预测结果进行比较。
总结
-
re.findall(r"(\d+)", result['generated_text'])[1:]:- 这是从模型生成的文本输出中提取有效的预测流量数据,跳过第一个数字,仅保留后续的数字作为最终的预测结果。
-
label_pattern = r"\[/INST\]{Traffic volume data in the next \d+ hours: \[(.*)\]}.</s>":- 这是从原始输入数据中提取真实的标签(交通流量数据),用以评估模型的预测性能。提取出的数据将作为对比标准,与模型预测的结果进行比较。
通过这两个不同的正则表达式,代码能够分别处理预测的输出数据和真实的标签数据,确保模型的评估和推理的逻辑能够顺利进行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号