【cs231n】图像分类 k-Nearest Neighbor Classifier(K最近邻分类器)【python3实现】
【学习自CS231n课程】
转载请注明出处:http://www.cnblogs.com/GraceSkyer/p/8763616.html
k-Nearest Neighbor(KNN)分类器
与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。所以当k=1的时候,k-Nearest Neighbor分类器就是Nearest Neighbor分类器。从直观感受上就可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。
【或者说,用这种方法来检索相邻数据时,会对噪音产生更大的鲁棒性,即噪音产生不确定的评价值对评价结果影响很小。】

上面例子使用了训练集中包含的2维平面的点来表示,点的颜色代表不同的类别或不同的类标签,这里有五个类别。不同颜色区域代表分类器的决策边界。这里我们用同样的数据集,使用K=1的最近邻分类器,以及K=3、K=5。K=1时(即最近邻分类器),是根据相邻的点来切割空间并进行着色;K=3时,绿色点簇中的黄色噪点不再会导致周围的区域被划分为黄色,由于使用多数投票,中间的整个绿色区域,都将被分类为绿色;k=5时,蓝色和红色区域间的这些决策边界变得更加平滑好看,它针对测试数据的泛化能力更好。
【注:白色区域表示 这个区域中没有获得K-最近邻的投票,你或许可以假设将其归为一个类别,表示这些点在这个区域没有最近的其他点】
建议:去网站上尝试用KNN分类你自己的数据,改变K值,改变距离度量,来培养决策边界的直觉。
网址:http://vision.stanford.edu/teaching/cs231n-demos/knn/
超参数的选择
在实际中,大多使用k-NN分类器,但是K值如何确定?距离度量如何选择?向K值和距离度量这样的选择,被称为超参数(hyperparameter)。问题在于,在时间中该如何设置这些超参数。
× 你首先可能想到的是,选择能对你的训练集给出最高准确率,表现最佳的超参数,这是糟糕的做法!例如:在之前的k-最近邻分类算法中,假设k=1,我们总能完美分类训练集数据,我们便采用了这个策略...但之前实践中让K取更大的值,尽管在训练集中分错个别数据,但对于在训练集中未出现过的数据分类性能更佳,可见K=1并不合适。【在机器学习中,我们关心的不是要尽可能拟合训练集,而是要让我们的分类器以及方法,在训练集以外的未知数据上表现得更好。】
× 你或许又会想,把所有的数据分成两部分:训练集和测试集。然后在训练集上用不同的超参数来训练算法,然后将训练好的分类器用在测试集上,再选择一组在测试集上表现最好的超参数。这也很糟糕!如果采用这种方法,那么很可能我们选择了一组超参,只是让我们的算法在这组测试集上表现良好,但是这组测试集的表现无法代表在全新的数据上的表现。所以,不要用测试集去调整参数,容易使得你的模型过拟合。【机器学习系统的目的,是让我们了解算法表现究竟如何,所以,测试集的目的是给我们一种预估方法,即在没遇到的数据上算法表现将会如何。】
√ 更常见的做法,就是将数据分为三组:训练集(大部分数据),验证集(从训练集中取出一小部分数据用来调优),测试集。我们在训练集上用不同超参来训练算法,在验证集上进行评估,然后用一组超参(选择在验证集上表现最好的)。然后,当完成了这些步骤以后,再把这组在验证集上表现最佳的分类器拿出来,在测试集上跑一跑。这个数据才是告诉你,你的算法在未见的新数据上表现如何。非常重要的一点是,必须分割验证集和测试集,所以当我们做研究报告时,往往只是在最后一刻才会接触到测试集。
以CIFAR-10为例,我们可以用49000个图像作为训练集,用1000个图像作为验证集。验证集其实就是作为假的测试集来调优。
代码实现:


1 import numpy as np 2 import pickle 3 import os 4 5 6 class KNearestNeighbor(object): 7 def __init__(self): 8 pass 9 10 def train(self, X, y): 11 """ X is N x D where each row is an example. Y is 1-dimension of size N """ 12 # the nearest neighbor classifier simply remembers all the training data 13 self.Xtr = X 14 self.ytr = y 15 16 def predict(self, X, k=1): 17 """ X is N x D where each row is an example we wish to predict label for """ 18 """ k is the number of nearest neighbors that vote for the predicted labels.""" 19 num_test = X.shape[0] 20 # lets make sure that the output type matches the input type 21 Ypred = np.zeros(num_test, dtype=self.ytr.dtype) 22 23 # loop over all test rows 24 for i in range(num_test): 25 # using the L1 distance (sum of absolute value differences) 26 distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1) 27 # L2 distance: 28 # distances = np.sqrt(np.sum(np.square(self.Xtr - X[i, :]), axis=1)) 29 indexes = np.argsort(distances) 30 Yclosest = self.ytr[indexes[:k]] 31 cnt = np.bincount(Yclosest) 32 Ypred[i] = np.argmax(cnt) 33 34 return Ypred 35 36 37 def load_CIFAR_batch(file): 38 """ load single batch of cifar """ 39 with open(file, 'rb') as f: 40 datadict = pickle.load(f, encoding='latin1') 41 X = datadict['data'] 42 Y = datadict['labels'] 43 X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1).astype("float") 44 Y = np.array(Y) 45 return X, Y 46 47 48 def load_CIFAR10(ROOT): 49 """ load all of cifar """ 50 xs = [] 51 ys = [] 52 for b in range(1, 6): 53 f = os.path.join(ROOT, 'data_batch_%d' % (b, )) 54 X, Y = load_CIFAR_batch(f) 55 xs.append(X) 56 ys.append(Y) 57 Xtr = np.concatenate(xs) # 使变成行向量 58 Ytr = np.concatenate(ys) 59 del X, Y 60 Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, 'test_batch')) 61 return Xtr, Ytr, Xte, Yte 62 63 64 Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar-10-batches-py/') # a magic function we provide 65 # flatten out all images to be one-dimensional 66 Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072 67 Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072 68 69 70 # assume we have Xtr_rows, Ytr, Xte_rows, Yte as before 71 # recall Xtr_rows is 50,000 x 3072 matrix 72 Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation 73 Yval = Ytr[:1000] 74 Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train 75 Ytr = Ytr[1000:] 76 77 # find hyperparameters that work best on the validation set 78 validation_accuracies = [] 79 for k in [1, 3, 5, 10, 20, 50, 100]: 80 # use a particular value of k and evaluation on validation data 81 nn = KNearestNeighbor() 82 nn.train(Xtr_rows, Ytr) 83 # here we assume a modified NearestNeighbor class that can take a k as input 84 Yval_predict = nn.predict(Xval_rows, k=k) 85 acc = np.mean(Yval_predict == Yval) 86 print('accuracy: %f' % (acc,)) 87 88 # keep track of what works on the validation set 89 validation_accuracies.append((k, acc))
这代码我有空的话再完善吧......没空(
程序结束后,我们会作图分析出哪个k值表现最好,然后用这个k值来跑真正的测试集,并作出对算法的评价。
把训练集分成训练集和验证集。使用验证集来对所有超参数调优。最后只在测试集上跑一次并报告结果。
交叉验证
设定超参数的另一个策略是交叉验证。这在小数据集中更常用一些,在深度学习中不那么常用。当我们训练大型模型时,训练本身非常消耗计算能力,因此这个方法实际上不常用。
还是用刚才的例子,如果是交叉验证集,我们就不是取1000个图像,而是将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。

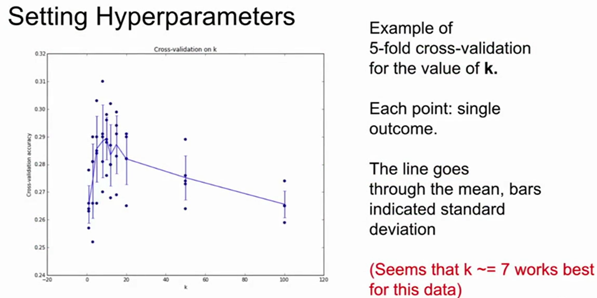
下图是5份交叉验证对k值调优的例子。针对每个k值,得到5个准确率结果,取其平均值,然后对不同k值的平均表现画线连接。本例中,当k=7的时算法表现最好(对应图中的准确率峰值)。如果我们将训练集分成更多份数,直线一般会更加平滑(噪音更少)。
实际应用:
在实际情况下,人们不是很喜欢用交叉验证,主要是因为它会耗费较多的计算资源。一般直接把训练集按照50%-90%的比例分成训练集和验证集。但这也是根据具体情况来定的:如果超参数数量多,你可能就想用更大的验证集,而验证集的数量不够,那么最好还是用交叉验证吧。至于分成几份比较好,一般都是分成3、5和10份。
常用的数据分割模式。给出训练集和测试集后,训练集一般会被均分。这里是分成5份。前面4份用来训练,黄色那份用作验证集调优。如果采取交叉验证,那就各份轮流作为验证集。最后模型训练完毕,超参数都定好了,让模型跑一次(而且只跑一次)测试集,以此测试结果评价算法。
KNN的劣势:
其实,KNN在图像分类中很少用到,原因如下:
- 它在测试时运算时间很长,这和我们刚才提到的需求不符,
- 像欧几里得距离或者L1距离这样的衡量标准用在比较图像上不太合适,这种向量化的距离函数,不太适合表示图像之间视觉的相似度。
- 它并不能体现图像之间的语义差别,更多的是图像的背景,色彩的差异。
- K-近邻算法还有另一个问题,我们称之为“维度灾难”。 K-近邻分类器,它有点像是用训练数据 把样本空间分成几块,这意味着,如果我们希望分类器有好的效果,我们需要训练数据能密集地分布在空间中,否则最近邻点的实际距离可能很远,也就是说,和待测样本的相似性没有那么高。而问题在于,想要密集地分布在空间中,我们需要指数倍地训练数据,这很糟糕,我们根本不可能拿到那么多的图片去密布这样的高维空间里的像素。
参考:
https://www.bilibili.com/video/av17204303/?from=search&seid=6625954842411789830
https://zhuanlan.zhihu.com/p/20900216?refer=intelligentunit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号