【目标检测】SSD+Tensorflow 300&512 配置详解
SSD_300_vgg和SSD_512_vgg weights下载链接【需要****~】:
| Model | Training data | Testing data | mAP | FPS |
|---|---|---|---|---|
| SSD-300 VGG-based | VOC07+12+COCO trainval | VOC07 test | 0.817 | - |
| SSD-300 VGG-based | VOC07+12 trainval | VOC07 test | 0.778 | - |
| SSD-512 VGG-based | VOC07+12+COCO trainval | VOC07 test | 0.837 | - |
我的csdn下载链接【没法****的同学】:
ssd-512:https://download.csdn.net/download/qq_36396104/10792340
ssd-300:https://download.csdn.net/download/qq_36396104/10792337
ssd源码https://github.com/DengZhuangSouthRd/SSD-TinyObject/blob/master/COMMANDS.md
转自:https://blog.csdn.net/liuyan20062010/article/details/78905517
1. 搭建SSD框架,下载解压即可
2. 下载pascalvoc数据,自己的数据根据voc格式改写(图片的名称,不用拘泥于6位数字,其他命名也可以)
解压后不要混合在一个文件夹下,要生成三个,主要是利用训练集测试的文件夹,VOCtrainval用来训练,VOCtest用来测试。
VOCtrainval 中JPEGImage文件夹中仅是训练和验证的图片,Main文件夹中仅是trainval.txt, train.txt, val.txt
VOCtest中JPEGImage文件夹中仅是测试图片,Main文件夹中仅是test.txt.

![]()
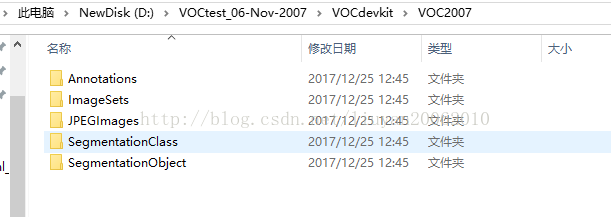

3. 图片数据重命名为6位数字
python代码
3.标记数据
4.生成txt文件,train.txt, trainval.txt, test.txt, val.txt
python代码
import os
import random
xmlfilepath=r'/home/xxx/subimage_xml_xiao'
saveBasePath=r"/home/xxx/txt"
trainval_percent=0.7
train_percent=0.7
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
5. 将训练类别修改为和自己一样的
SSD-Tensorflow-master—>datasets—>pascalvoc_common.py
根据实际情况进行修改
6. 将图像数据转换为tfrecods格式
SSD-Tensorflow-master—>datasets—>pascalvoc_to_tfrecords.py 。。。然后更改文件的83行读取方式为’rb’)

修改读取图片的类型:修改如下两个地方
“image_format = b'JPEG'”
“filename = directory + DIRECTORY_IMAGES + name + '.jpg'”中 jpg 可以修改读取图片的类型
修改67行,可以修改几张图片转为一个tfrecords,如下图

![]()
在SSD-Tensorflow-master文件夹下创建tf_conver_data.sh
7. 训练模型
train_ssd_network.py修改第154行的最大训练步数,将None改为比如50000。(tf.contrib.slim.learning.training函数中max-step为None时训练会无限进行。)
train_ssd_network.py,网络参数配置,若需要改,再此文件中进行修改
修改如下图中的数字600,可以改变训练多长时间保存一次模型

需要修改的地方:
a. nets/ssd_vgg_300.py (因为使用此网络结构) ,修改87 和88行的类别
b. train_ssd_network.py,修改类别120行,GPU占用量,学习率,batch_size等
c eval_ssd_network.py 修改类别,66行
# =========================================================================== # # Main evaluation flags. # =========================================================================== # tf.app.flags.DEFINE_integer( 'num_classes', 21, 'Number of classes to use in the dataset.') #根据自己的数据修改为类别+1
d. datasets/pascalvoc_2007.py 根据自己的训练数据修改整个文件
方案1 从vgg开始训练其中某些层的参数
# 通过加载预训练好的vgg16模型,对“voc07trainval+voc2012”进行训练
# 通过checkpoint_exclude_scopes指定哪些层的参数不需要从vgg16模型里面加载进来
# 通过trainable_scopes指定哪些层的参数是需要训练的,未指定的参数保持不变,若注释掉此命令,所有的参数均需要训练
DATASET_DIR=/home/doctorimage/kindlehe/common/dataset/VOC0712/
TRAIN_DIR=.././log_files/log_finetune/train_voc0712_20170816_1654_VGG16/
CHECKPOINT_PATH=../checkpoints/vgg_16.ckpt
python3 ../train_ssd_network.py \
--train_dir=${TRAIN_DIR} \ #训练生成模型的存放路径
--dataset_dir=${DATASET_DIR} \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=${CHECKPOINT_PATH} \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
方案2 : 从自己预训练好的模型开始训练(依然可以指定要训练哪些层)
从自己训练的ssd_300_vgg模型开始训练ssd_512_vgg的模型
因此ssd_300_vgg中没有block12,又因为block7,block8,block9,block10,block11,中的参数张量两个网络模型中不匹配,因此ssd_512_vgg中这几个模块的参数不从ssd_300_vgg模型中继承,因此使用checkpoint_exclude_scopes命令指出。
因为所有的参数均需要训练,因此不使用命令--trainable_scopes
另外由300转512后还需修改:
1. 首先修改ssd_vgg_512.py的训练类别
2.修改train_ssd_network.py的model_name
修改为ssd_512_vgg
3. 修改nets/np_methods.py
修改:将300改为512, 将类别改为自己数据的类别(+背景)
4. 修改preprocessing/ssd_vgg_preprocessing.py
修改:将300改为512
5. 修改ssd_notbook.ipynb
a 将文件中数字“300”改为“512”
其他修改可以参考:http://blog.csdn.net/liuyan20062010/article/details/78905517
方案3:从头开始训练自己的模型
8. 测试或验证
首先将测试数据转换为tfrecords
在SSD-Tensorflow-master文件夹下建立一个sh文件
9. 利用ssd_notebook.ipynb显示训练测试模型的结果
修改红框标注的位置,一个是修改为自己的模型所在的路径,另一个是修改为自己图片所在的路径
![]()

![]()

10. 注意
- –dataset_name=pascalvoc_2007 、–dataset_split_name=train、–model_name=ssd_300_vgg这三个参数不要自己随便取,在代码里,这三个参数是if…else…语句,有固定的判断值,所以要根据实际情况取选择
- TypeError: expected bytes, NoneType found SystemError: returned a result with an error set 这是由于CHECKPOINT_PATH定义的时候不小心多了个#号键,将输入给注释掉了,如果不想使用预训练的模型,需要将--checkpoint_path=${CHECKPOINT_PATH} \注释掉即可
- SSD有在VOC07+12的训练集上一起训练的,用一个笨一点的办法: pascalvoc_to_tfrecords.py文件中,改变SAMPLES_PER_FILES,减少输出tfrecord文件的个数,再修改tf_convert_data.py的dataset参数,记得将前后两次的输出名改变一下,前后两次转换的tfrecords放在同一个文件夹下,然后手工重命名。(这里由于只是验证论文的训练方法是否有效,所以没必要写这些自动化代码实现合并,以后要用自己的数据集训练的时候就可以写一些自动化脚本)
- 有时候运行脚本会报错,可能是之前依次运行导致显存占满。
- 从pyCharm运行时,如果模型保存路径里之前的模型未删除,将会报错,必须保证该文件夹为空。
- 在TRAIN_DIR路径下会产生四中文件: 1. checkpoint :文本文件,包含所有model.ckpt-xxxx,相当于是不同时间节点生成的所有ckpt文件的一个索引。 2. model.ckpt-2124.data-000000-of-000001:模型文件,保存模型的权重 3. model.ckpt-2124.meta: 图文件,保存模型的网络图 4. model.ckpt-2124.index : 这个没搞太清楚 5. graph.pbtxt: 用protobuf格式保存的模型的图
- error:Default MaxPoolingOp only supports NHWC,这有两种原因:1、你的电脑没有gpu(情况很少)2、你使用的tensorflow版本有问题,看看是不是使用了非gpu版的tensorflow,或者使用的虚拟环境没切换过来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号