图形学中的剔除技术
现代剔除技术通常包括CPU上的粗粒度剔除和GPU上的细粒度剔除,这些剔除技术都是围绕不同粒度的物体而设计的。
剔除粒度可以分为对object/instance剔除、对cluster/chunk剔除和对triangle剔除。

- 对object/instance的剔除通常在CPU进行,目的是减少物体的Draw Call
- 对cluster/chunk的剔除通常用Compute Shader在GPU进行,目的是为了减少光栅化三角形的数量
- 对triangle的剔除通常通过硬件或者Compute Shader在GPU进行,目的是为了减少光栅化次数以及shading次数
视锥剔除
视锥剔除通常是一种软件剔除方法,其剔除粒度取决于具体场合,可以是包围盒也可以是cluster,视锥剔除可以分为两步,第一步是空间结构的划分,通常通过BVH的形式组织数据结构,第二步是对于包围盒的相交测试。
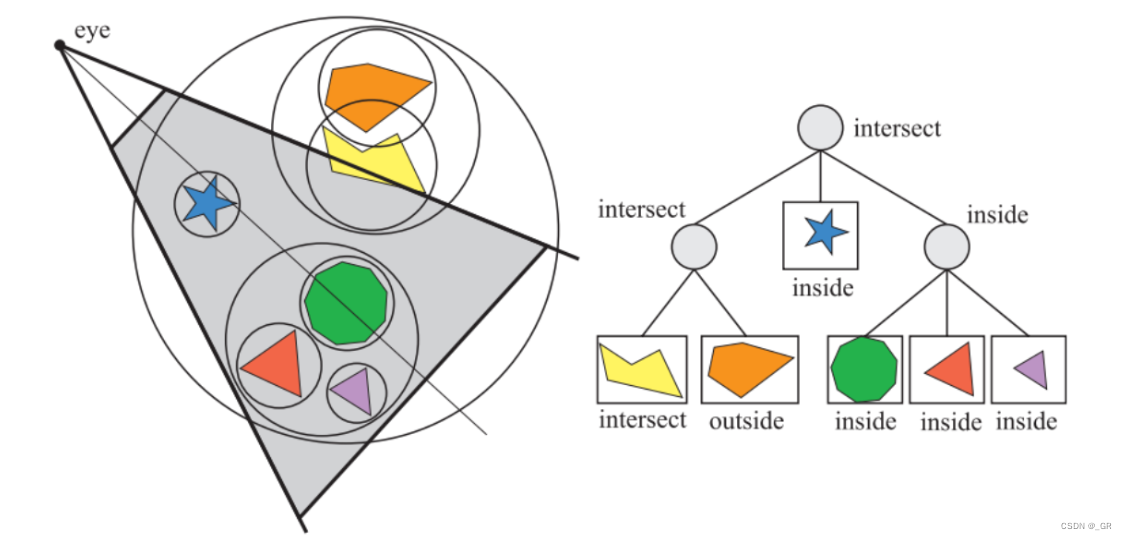
空间加速结构的遍历存在三种情况。
- 如果包围盒完全位于视锥之内,则其所有子节点都不需要做相交测试了。
- 如果包围盒部分处于视锥体之内,其子节点都需要进行相交测试。
- 如果包围盒处于视锥体之外则不会对其子节点进行进一步处理,直接对这颗树进行裁剪
实际上只有第二种情况需要后续的相交测试,相交测试的流程往往是判断包围盒是否在视锥体六个面内,但由于包围盒的子节点一定在根节点的包围盒内,所以根节点包围盒的相交测试不想交面的数据完全适用于根节点,如下图的情况,根节点包围盒在上下前后右五个面之内,只与视锥体左侧面相交,其子节点也一定在上下前后右五个面之内,只需要对视锥体左面做相交测试就可以了,完全可以复用根节点的数据。主要的方法是用位掩码标记需要相交测试的面,然后与相交器(intersector)一起传递。
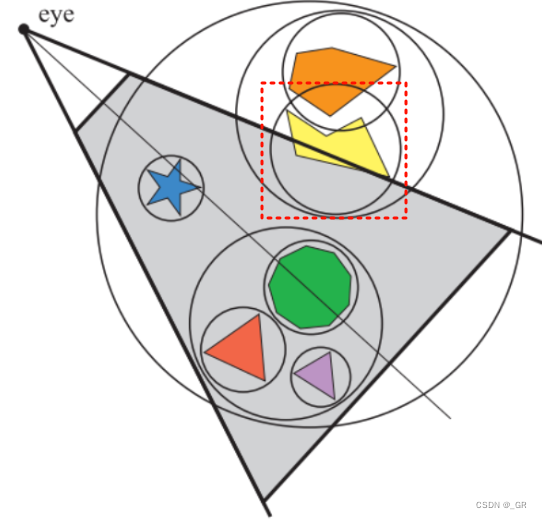
- 局限性
是否用BVH取决于具体场景需求,因为用BVH存在二叉树结构,用BVH可能因为左右子树遍历深度不一致导致打断GPU的并行,也就是带来负载平衡的问题。部分引擎不采用BVH而只用单一的BV列表的方式存储包围盒数据,因为数组的形式在SIMD和多线程上实现更简单且能带来更好的性能。但BV列表的方式会有剔除不干净的问题,这个时候就要权衡用BVH低并行和BV列表多Draw Call之间的代价了。
遮挡剔除
可以通过Early-Z等方式去解决可见性问题,但是这类方法会带来DrawCall过多和OverDraw两种问题,遮挡剔除就是解决这个问题的,从CPU端直接不发送多余的DrawCall既能减少CPU和GPU的通信成本又能减少OverDraw问题。
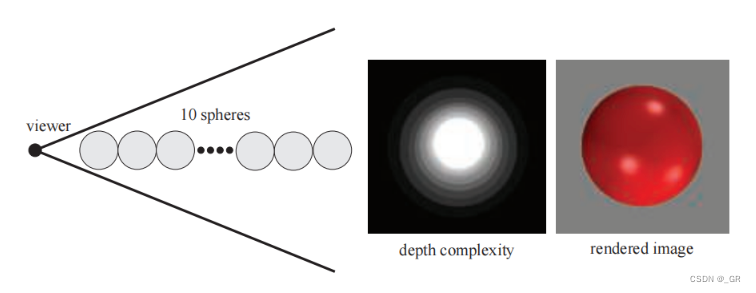
上图展示的是从后往前渲染的十个球,虽然最后成像是正确的,但是depth buffer却被写入了多次,最终将的像素高达10次写入,只通过Z-Test剔除会带来比较大的光栅化和硬件之间的通信成本。
遮挡剔除算法被分为两大类,point-based和cell-based,这两种遮挡剔除的思想类似于点光源和面光源。
- point-based
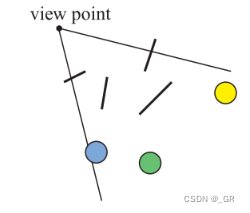
一般的遮挡剔除方案都是point-based,也就是从观察点形成的视锥体即使遮挡剔除的有效范围,在此范围内执行遮挡剔除算法且需要每帧都执行
- cell-based
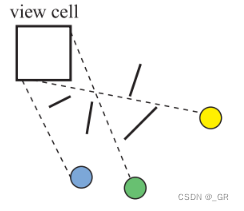
基于单元格的遮挡剔除会用更大的视锥体去包裹更多的物体,cell-based的好处是一旦计算了可见性,只要观察者位于对应的cell内就可以直接使用对应的遮挡剔除数据,这样可以复用多帧之前的数据不需要每帧都进行遮挡剔除。整个空间被划分成的cell并不会很多,所以cell-based的剔除结果可以通过预计算得到。
该类方案可以降低每帧都做遮挡剔除带来的功耗,但是大范围的遮挡剔除结果就意味着需要多发送许多本该被剔除掉的DrawCall,两者之间需要根据具体场景来权衡。
硬件遮挡查询(Occlusion Query)
硬件遮挡查询支持在执行绘制命令之前向GPU插入查询指令,查询指定的Draw Call中通过Depth Test的数量。
剔除的具体思路为先用一个简单的depth-only的pass将深度写入到z-buffer中,然后传入物体到GPU进行遮挡剔除,在GPU内三角形会被光栅化,其结果与z-buffer比较但不会写入深度,标记其可见像素数量n,如果n=0代表物体会被完全遮挡需要被剔除掉,反之不能剔除。最后再把信息传回CPU进行剔除。
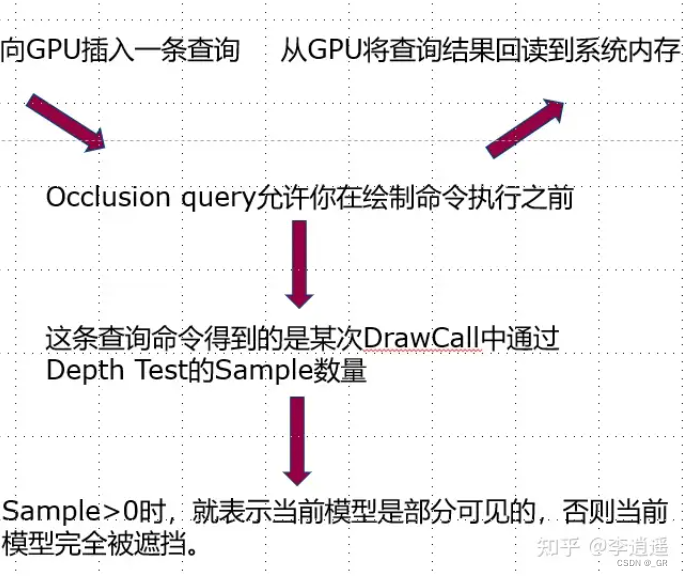
只看整个思路是完全不够的,因为DrawCall开销、VS开销以及信息回读很有可能导致剔除性能反而比不上不剔除,下面说说该方法的优化细节。
- 包围盒
对于复杂的场景哪怕只用depth only pass也有很大的VS压力,因为三角形太多了,可以通过多个紧贴的简单的包围盒或者简单的Proxy Mesh去代替高精度模型去做深度写入。同时后续做遮挡查询的时候也可以传入包围盒进行快速的查询。
- 合批
因为是depth only pass,所以不需要考虑材质,可以把多个包围盒进行batch处理减少DrawCall数量。
- 粗深度缓冲区
硬件厂商一般都会提供粗深度缓冲区来进行遮挡剔除,如z-cull和early-z等方式都会优化生成z-buffer的过程,以Tile的形式去存取深度来快速进行粗糙却保守的遮挡剔除。
- 更快的查询变体
遮挡剔除存在一些速度更快的变体,比如可以用一个bool值来表示是否至少有一个片元通过了深度测试,因为n=0则剔除,n!=0则保留,其实只有剔除和不剔除两种状态,这种变体会在发现一个片元通过了测试(n!=0)就终止后续遮挡查询了。这种方法是保守的,但是这种粗糙的测试方法封死了后面更细粒度进行剔除的路子。
- 异步回读结果

查询结果回读到CPU需要的时间非常长,如果要等GPU回读以后才进行后续流程就会造成CPU进入stall状态等待GPU,这种空转是十分浪费的,一般的策略是CPU和GPU查询异步进行,其中CPU可以向GPU发送任意数量的查询请求,然后CPU会定期检查是否有任何结果可以使用,GPU会执行每个遮挡查询,并将查询结果放入一个队列中。CPU端的队列检查非常快,同时CPU还可以继续发送查询请求或者渲染物体,而不会发生停滞。这样会导致读上一帧的遮挡剔除结果,两帧之间如果变化过大有可能出现错误遮挡。
- 支持断言/条件的遮挡查询
异步回读结果会导致CPU和GPU的延迟,CPU上传的Draw Call可能是需要被剔除的,DirectX和OpenGL都支持断言/条件(predicated/conditional)的遮挡查询,GPU会记录遮挡查询后可见物体的ID,这样哪怕CPU提交了需要被剔除的数据也不会进入后续渲染流程。
层级深度缓冲剔除(Hierarchical Z Buffer)
层级深度缓冲也叫Hi-Z,这是一系列遮挡剔除的优化方案总称,具体的思路其实就是二分思想去做剔除,用一张粗糙的深度图做测试,没通过则说明该物体需要剔除掉了,通过深度测试则使用更低一级更精细的深度图继续做深度测试。

- 为什么需要Hi-Z
尽管用包围盒来做剔除计算可以大幅度减轻VS的压力,但一个包围盒有的时候是很大的 ,比如我们近距离看一颗草的包围盒,下图草的包围盒覆盖了13*13个像素,我们总共需要判断169次屏幕深度和包围盒深度,哪怕有一次包围盒深度要小于等于屏幕空间深度(包围盒里可能有一小部分要比屏幕深度离相机更近),那就不能剔除掉这个物体,因为只要出现一次这种情况,那就说明这个物体有可能出现在屏幕内被我们看到。
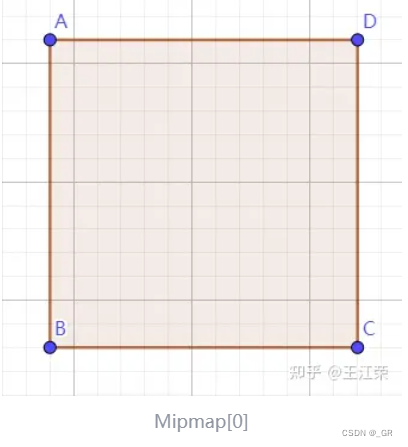
因此可以用Hi-Z的方式去减少包围盒判断的次数,就比如生成一个更高级的MipMap里面存储低一级MipMap里面四个像素的离相机最远的深度,那么包围盒只要比最远深度还要远那就剔除掉,因为这种情况这个物体一定是不可见的,且我们只需要非常少的判断次数就能得到结果。
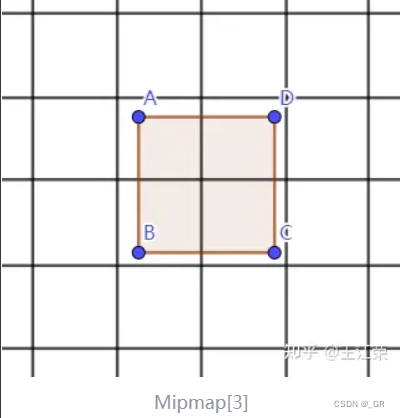
通常我们会一直找更高级别的MipMap直到该层级MipMap里面一个像素能完全包裹一个包围盒再做上面的判断,这样就最少一次就可以剔除掉物体了,但一般采用的是4×4的判断方式,因为极端情况下,如果包围盒中心恰好在屏幕正中心,而包围盒又占不满那一个Tixel,该包围盒就可能受到Tixel内其他位置的深度影响,本该被剔除却因为这种原因没被剔除,这就会导致遮挡剔除命中率降低。
最原始的思路通过将场景维护在一颗八叉树中,将屏幕z-buffer作为图像金字塔,通过从前向后遍历八叉树,在遇到被遮挡的八叉树节点就将他们剔除掉,每个节点都会在不同分辨率的z金字塔上做深度测试来判断是否要被剔除掉。

- 构建z-buffer金字塔
先生成一张全分辨率的z-buffer,每高一级(更粗糙)的z-buffer的mipmap内存的是更精细mipmap内的最大深度值(近处深度为0,远处深度为1),有这种生成规则是因为剔除的判断条件是包围盒的最近深度>对应深度图区域的最远深度。
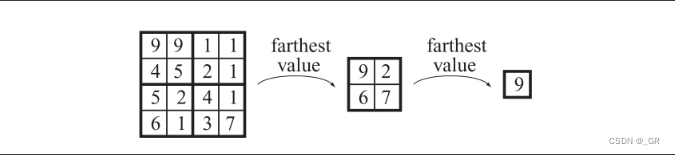
该算法分为3步
- 使用一些遮挡物来获得深度图并生成完整的z-buffer金字塔
- 遍历物体八叉树把物体包围盒投影到屏幕空间中,根据包围盒大小估计需要用到的z-buffer金字塔的mip层级
- 针对mip层级进行深度测试,如果遮挡结果不明确则用更精细的mip继续测试
但大多数场景都不会用上面完整版本的Hi-Z算法,因为八叉树和BVH都是对GPU不友好且昂贵的,下面说下Hi-Z的部分改进做法
- 预生成遮挡物
算法第一步需要生成一张完整的z-buffer,但是或者过程如果不做处理是比较耗费性能的,因此其实可以以n个物体为一组通过预生成一套简化的遮挡物体集合用来剔除,这样可以减少VS压力。
- 使用上一帧的z-buffer
利用前一帧的ZBuffer重投影后的信息在Compute Shader里指导Hi-Z做遮挡剔除, 上一帧深度基本是免费的,这样不需要额外的DrawCall,这种方法存在两个问题,如果重投影个别像素在上一帧没有对应位置就会导致生成的ZBuffer存在漏洞,这导致高级别的深度MipMap几乎剔除不了任何物体,另一个是会导致动态物体重投影区域产生延迟且快速移动物周围会产生物体突然出现的问题,因为动态物体这帧可见了但是按上一帧判断还是被剔除了。
- Double Pass互补
同时考虑了上一帧的深度图和这一帧部分物体的深度。首先对部分遮挡物做做一次光栅化,将光栅化结果与前一帧深度1/16分辨率的重投影结果结合起来再构建z-buffer金字塔。
《刺客信条大革命》用的方案和整个类似,大概对最靠近相机的300个occluder做光栅化来补充上一帧depth-buffer重投影导致的漏洞,由于300个occluder得到的depth-buffer并不能代表所有情况,尽管结合上一帧考虑还是有可能剔除掉不该被剔除的物体的,所以第一个Pass需要用补全后的depth-buffer来对所有cluster进行遮挡剔除,做完之后写入深度得到新的depth-buffer,筛选出被剔除掉的物体,第二个Pass对这些要被剔除掉的物体用新的depth-buffer再做一次遮挡剔除,如果某些物体这一次没有被剔除,那么就渲染这些物体,这种方法可以得到完全正确的图像。
第一个Pass得到的剔除结果是非保守的,得到的只是大概率不会被剔除的物体,这时候用这些cluster做第二次剔除就能得到保守结果了。
软件光栅化剔除
软件光栅化即为纯CPU的剔除,该方法不经过GPU所以不会有GPU stall的问题。
软件光栅遮挡剔除的基本做法,就是在每一帧update完成之后,在CPU侧对场景进行一遍光栅化,输出一个depth buffer,之后使用这个depth buffer对场景物件进行剔除,避免将那些不可见的数据塞入渲染列表,从而减轻渲染压力。
基于Masked的软光栅(MSOC)
Masked Software Occlusion Culling是基于Hi-Z的一种创新方法,不同于以往的Hi-Z需要先生成全分辨率的zbuffer才能降分辨率生成粗糙深度图,该方法可以在光栅化过程中直接计算出全分辨率的三角形遮挡关系且用降分辨率的贴图去存储,计算过程中也会用生成的深度图去指导光栅化的进行,同时利用现代CPU的向量指令集如AVX,SSE 4.1和SSE 2优化执行效率。
MSOC最大的优势在于他可以在更新深度的同时直接做遮挡剔除,而不需要输出完深度再用深度指导剔除。

最基础的软光栅框架包含两个Pass
- 对少量比较重要的物体进行视锥、背面剔除,剔除后结果光栅化后记录全分辨率的深度,以Tile(8×8)为单位进行降分辨率,每个Tile内的最大深度对应降分辨率depth buffer的一个pixel深度。
- 先对物体包围盒进行视锥剔除,剔除后结果通过CPU转换到屏幕空间,用包围盒的最小深度和包围盒覆盖的Tile的最大深度比较,如果包围盒最小深度比Tile最大深度还大则说明该物体可以被剔除。
MSOC做的优化
-
屏幕空间被划分成矩形Tile(32×8),因为这种结构可以很好的利用CPU的SIMD特性(8路SIMD,每路32通道),这样对三角形光栅化的时候可以对一个Tile多个像素并行计算一次性输出一整个Tile的结果。
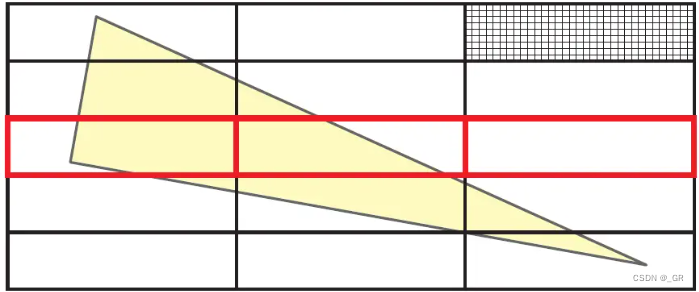
-
对于每个Tile只用两个浮点数Z0max和Z1max来表示深度和32位的mask来表示这个Tile内每个像素是用Z0max还是用Z1max,每个Tile输出的是一张coverage depth,在这种表达方式下,不需要使用全分辨率的depth buffer就能得到较高的裁剪精度。
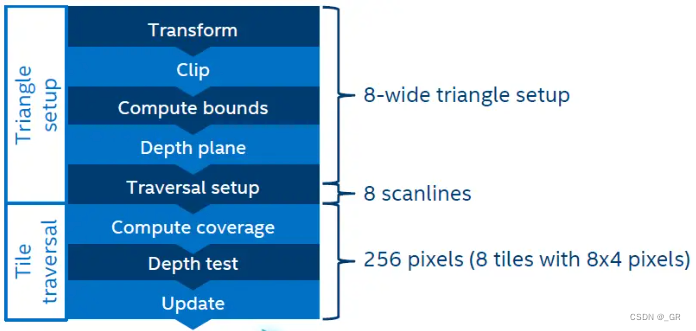
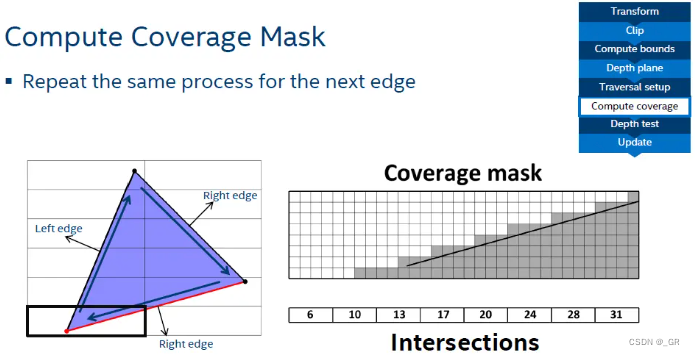
光栅化
光栅化会计算顶点的数值确定三角形覆盖的Tile,每个Tile只需要计算一次边缘方程,通过递增递减的形式快速求出后续的覆盖情况
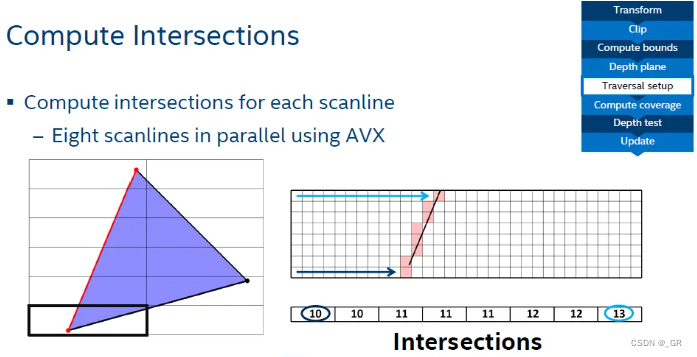
通过scanline对三角形进行扫描并光栅化

每个SIMD单元负责32×1或者8×4个像素的处理逻辑。
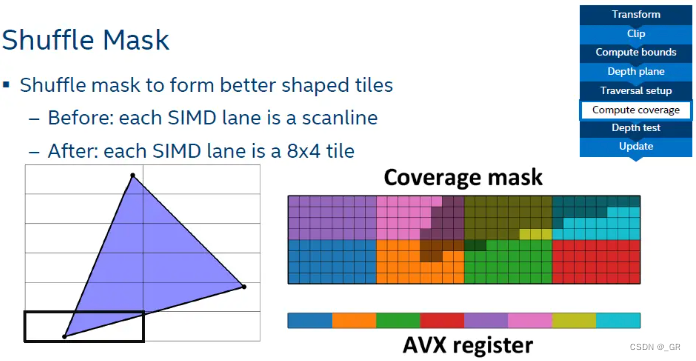
通过边顺序剔把三角形未覆盖的区域的mask设置为0,这里的0和1决定了后续过程中对应位置的深度是Z0max还是Z1max。

计算Hierarchical Depth Buffer和遮挡剔除
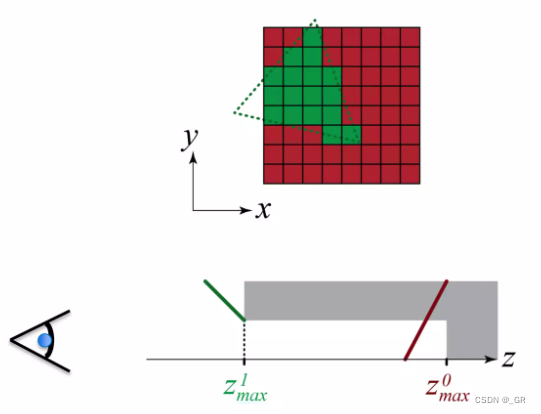
每个Tile只存3个数据,两个浮点数Z0max,Z1max和32位的mask(uint)
- Z1max叫做working layer,存储的是近处物体(工作区)的最大深度,如果三角形需要被光栅化且通过了深度测试则把最大深度写入到Z1max,Z1max则把主要作用是更新Z0max。
- Z0max叫做reference layer,存储的是Tile范围内的最大深度,如果未通过Z0max的测试则不会进行光栅化直接剔除掉。
- mask的主要作用是标记32个pixel中哪个需要使用Z0max的深度哪个用Z1max的深度。
Tile的Z0max和Z1max更新逻辑如下
- 深度大于Z0max的三角形会被直接剔除,处于Z0max和Z1max之间的三角形会进行光栅化且更新Z1max的深度,这是一种保守的方法,取Z1max和三角形的最大深度能保证不会出现错误剔除,原理跟Hi-Z类似

- 如果三角形的深度要远小于Z1max和Z0max,这意味着该三角形可能属于近景的物体,大概率整个物体都不会被剔除掉,这时需要把mask的值设置为全部取Z0max,且Z1max移动到近裁剪面,这里的原理是因为后续的三角形深度大概率都是远小于原Tile深度的,所以可以直接放弃之前working layer(Z1max)的积累,因为working layer积累满之后会更新Z0max,如果不放弃之前的结果,可能导致由于之前远处物体的积累,working layer提前被填满更新,这就导致Z0max更多取决于之前远处的物体,而近处物体的depth无法覆盖上去,这样还是用一个很大的深度(Z0max)去剔除虽然仍然是保守的,但是效率会下降,我们希望每一时刻Z0max都能尽可能取最小这样能剔除更多的物体。
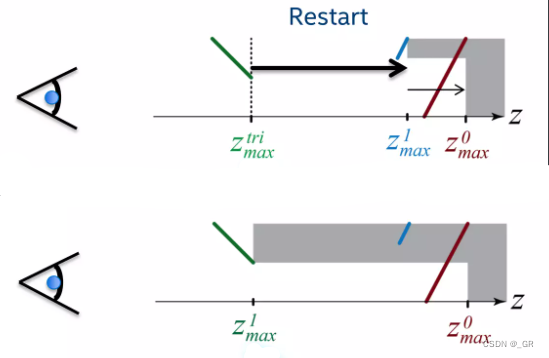
- 当Z1max1的值铺满整个屏幕(mask全部取同一值),这个时候就会用Z1max覆盖Z0max的值,Z0max会被慢慢往前推,这种思想有点像俄罗斯方块,如果一层都被填满了就消掉当作新的开始,Z0max也是如此更新,只不过这个新的Z0max一定是靠屏幕越来越近的,最终的效果就是是深度图一直往前推,得到最近表面的一层深度。
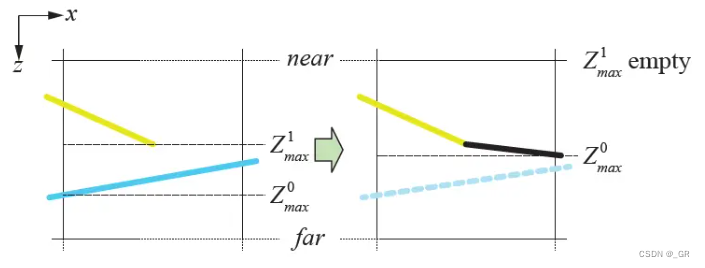
遮挡剔除可以直接在上面的步骤里做,先对物体的简单包围盒做上述方法的检测,如果包围盒的最小值大于Z0max,则该物体可以直接剔除掉,如果通过测试则会写入深度且对该物体的精细模型进行光栅化,同样根据上述逻辑写入深度,这样就可以做到边进行光栅化边剔除,直接解耦了光栅化与生成深度的过程,大幅度提高效率。
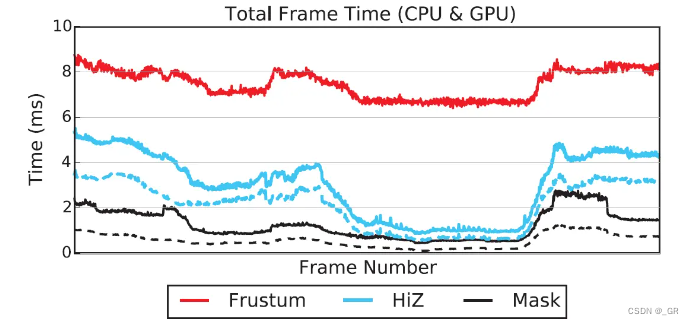
下图为视锥剔除,Hi-Z以及Mask剔除的总体时间对比,其中实线代表遮挡剔除+光栅化的时间,虚线代表遮挡剔除的时间。
GDC2023移动平台高性能软光栅[TODO]
入口(Portal)剔除
入口剔除是视锥剔除的一种拓展方案,因为室内环境下视锥剔除效率其实是非常低的,室内环境大部分物体都处于视锥体之内,但是当室内划分了多个空间的时候,大部分墙壁后的物体都是看不到需要被剔除的,标准的视锥剔除方案做不到这一点,往往需要搭配遮挡剔除使用。

从上面视角可以看出真正有效的视锥体范围其实跟门的大小以及位置有关,附近房间大部分物体其实都该被剔除掉。
入口剔除就是解决标准视锥剔除室内剔除效率低的问题,一般实现都是通过预处理标记每个房间相关联的空间数据,在对应空间内视锥体会根据“门”的大小而缩小再做一遍视锥剔除。
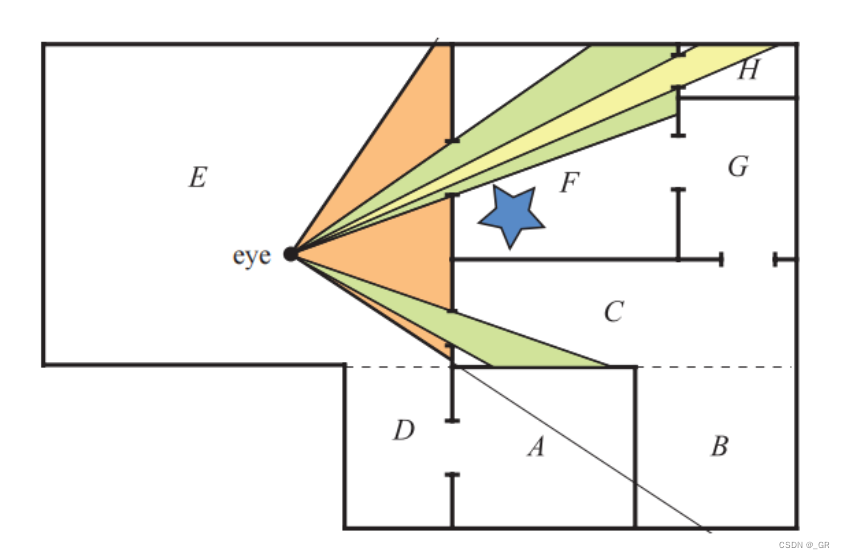
举个例子上图观察点\(eye\)在E空间,E空间在预处理的时候已经存储了联控的房间的门以及物体数据,上图E的关联数据为D、A、C、F房间的数据。根据屏幕屏幕视角需要对把视锥体依次变换成C、F门的大小做视锥剔除,F内需要再次变换成H门的大小做视锥剔除,此时F空间的无关数据如蓝色的星形物体会被剔除掉。

由于该方法对于每个门都得变换一遍视锥体去剔除,上图中两个门都通往同一个房间,那这个房间中的每个物体都会针对每个门对应的视锥体进行剔除,但上面同一个物体同时出现在两个门里面,如果不做处理两个门都会发送绿色物体的渲染Draw Call,这会导致效率低下且在存在透明物体的情况下容易导致渲染错误(透明物体两次blend导致颜色错误)。为了避免重复绘制,通常会对绘制过的物体进行标记,同时也要标记帧号来避免每帧都清空标记(不标记帧号每帧都得清空标记数据重新打标签,这个过程可以优化)。
为了避免上面的情况发生,除了用标记的方法还有更好的优化是通过模板测试,对每个门上传的Draw Call都进行模板测试可以避免门1和门2绘制的绿色物体重叠在一起,因为模版大小就只限制在门里面,门一不会绘制门2里的东西,哪怕是同一个Draw Call。这样也就不需要做上面的标记也可以正确的做透明渲染了。
GPU Driven剔除
GPU Driven剔除不是一种具体的算法,而是一种思路,其核心思路是减少CPU和GPU的通信,尽量将所有的渲染相关的事物都放在GPU做,同时利用GPU的并行高算力的特性去做更细粒度的剔除。
前面的大部分剔除方案都有一个问题,剔除结果需要回读到CPU。这是因为剔除的终极目的就是没有多余的DrawCall和OverDraw,但是要减少DrawCall还是得回到CPU,因为普遍的渲染管线里都是由CPU发送DrawCall,所以一般流程都是GPU回读深度图,在CPU做剔除计算,最后发送没有被剔除的物体DrawCall进行渲染。
正常渲染管线中提交DrawCall本质就是从内存找到这个object的相关数据和一些列指令打包到GPU做渲染,一旦CPU需要用到GPU运算的结果的时候就需要长时间的回读了,而且要得到最后渲染的结果就意味着CPU还得发送一次DrawCall,这里面模型的各种数据其实是重复传递的。
GPU Driven Pipelines号称一个Draw Call解决战斗,其实就是一个DrawCall把当前可视场景所有的渲染资源(包括几何信息,材质信息,变换信息,包围盒信息)打包成Buffer上传到GPU的显存里(这里不包括静态合批早已经送到显存的数据),这个时候显存里面已经有数据了,就可以直接利用之前算好的z-buffer(在显存里,不需要回读)在Compute Shader做剔除,做完后通过execute indirect指令向GPU发送绘制指令。
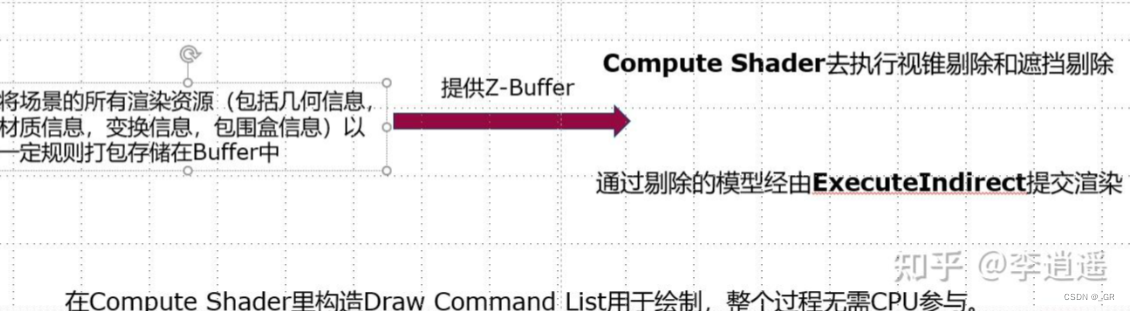
具体的GPU Driven Pipeline由以下几个步骤组成

- CPU
- 粗糙视锥剔除
这一步通常会做视锥体剔除和用软光栅在CPU做粗糙的遮挡剔除,先做一次粗糙且保守的剔除可以大幅度减少CPU传到GPU的数据量,减少带宽压力。
- 合并Instance
正常的合批技术通过把具有相同mesh的instance合并,用单独的instance_buffer存储所有instance的属性最后通过一个DrawCall进行绘制,不同的mesh是不能进行instance合并的。GPU Driven技术用了Merge-Instanceing技术把不同mesh的instance合成成一个大的Instance,这样就可以一个DrawCall提交所有场景数据了,但实际上最好还是根据pso排序物体,确保合并后一个材质逻辑(shader)一个DrawCall。
原始的Instance技术由于都是相同的mesh,因此材质数据很好拿到,但是把不同的mesh合并以后存在一个问题,VS里只能拿到顶点数据(vertex_index)却拿不到实例id(instance_index),这样就没办法拿到材质信息。
Merge Instance的核心技术即使让每个mesh强行拥有一样的拓扑结构,这样每个instance都拥有相同的索引数量,这样就可以通过一张大的buffer存储顶点数据,instance_id就可以通过vertex_index/mesh_nums得到。
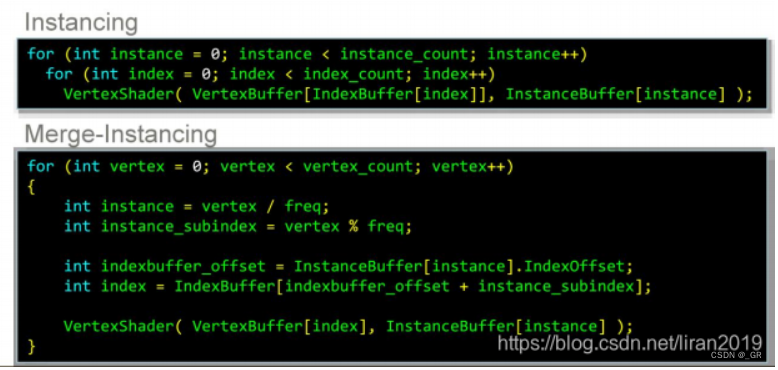
- 基于哈希合并Drawcalls
不同的实例的材质、PSO数据则通过哈希的形式压缩进同一个DrawCall里,可以通过instance_id拿到。
- GPU
- Instance剔除
用视锥剔除和遮挡剔除进行更细粒度的剔除,没剔除的Instance通过InterlockedAdd+前缀和的算法快速存放到一张连续的Buffer中。
- 拆分成Chunk
每个cluster只有64个三角形,而一个Instance可能有上千个cluster,每个Instance包含的cluster差的比较多,如果直接拆会导致并行度下降(每个warp运算量差异大,warp空等),因此先拆分成chunk(包含64个cluster)作为中间缓冲。这边的chunk拆解其实是可选步骤,因为拆解过程也会耗费性能,需要具体场景具体分析。
- Cluster剔除
把mesh切分成cluster目的是进行更加细粒度的剔除,虽然对cluster会耗费一定性能,但是可以大大减少shading次数,同时如果一个cluster不够64个三角形需要加入退化三角形进行补齐。

其做法和Instance剔除类似,不过这里会提前构建cluster的包围盒,且根据深度进行排序来减少overdraw。

- 三角形剔除
对于三角形可以采用多种剔除方法,下图中包含背面剔除,细节剔除,深度提出,小图元剔除,视锥体剔除等,这些更细粒度的剔除需要考虑场景来组合使用。

- 合并index

最后一步是把剔除后剩余的三角形compact到一个紧凑的buffer里面,再对这些三角形去做一些基于材质(instance)的排序与合并,最终通过不同的DrawCall来绘制不同材质的物体。

compact index

draw Indirect

- 交错式顶点buffer
这里还能采取一种优化,就是把instance的vPositon、normal、texCoord等属性分buffer存储,这样做的好处是可以多个Shader复用同一个buffer里的数据,比如有的instance材质属性一直但材质逻辑不同。这样可以提高空间的利用率和缓存的命中率。

Z-Cull
Z-Cull相当于硬件版本的Hi-Z,该方法和Early Z非常类似,但是他们的粒度不一样,Z-Cull通常是以Pixel Tile(8×8或者16×16个像素)为粒度进行深度测试的,具体思路和TBR类似,以一个非常粗的粒度去光栅化,用一个粗糙Pixel去对应最细粒度的十几个Pixel,如果这个粗粒度的Pixel都通不过深度或者模板测试,则不需要后续细化的光栅化了,这样可以大幅度提高深度和模板测试的效率。
Z-Cull和Early-Z还有一个区别就是Z-Cull是不需要向depth buffer写入深度的,因为Z-Culling通常用与TBR架构,所以对于带宽是敏感的,该方法会先从深度图里面读出对应Tile的Min和Max值,把该值存在片上内存(on-chip),用粗糙的深度去比较Min和Max值,并不会写入深度。
总结来说Z-Cull实际上是对Early-Z的一种二分层级加速优化。
具体的硬件架构如下
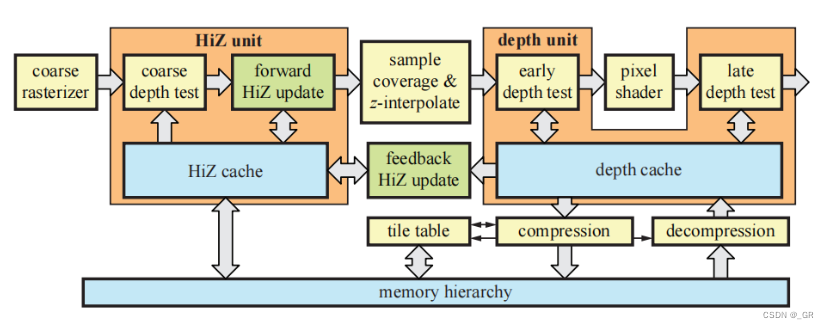
Z-Cull实际上与硬件光栅化息息相关,下面介绍一下具体流程。
硬件光栅化由Coarse Raster和Fine Raster两大部分组成,对应上图的coarse rasterizer和sample coverage,其中在Coarse Raster之前会分Tile进行遍历加速,在Coarse Raster之后还会有HiZ单元来做Z-Cull,在通过上面的操作以后才会被送往sample coverage单元做Fine Raster以2×2的Quad生成Pixel。
分层遍历加速
我们已知每个三角形都需要进行光栅化,正常的想法是遍历每个Pixel,由此判断覆盖情况,但是每个三角形都得遍历一次全屏的Pixel是非常费的,因此为了提高效率,通常采用分层的方式来进行三角形遍历,我们只需要知道三角形边的方程,把4×4的Tile的四个顶点带入方程就可以知道此Tile是否在边缘的同一侧来进行剔除,比如下图只需要对6个Tile进行遍历
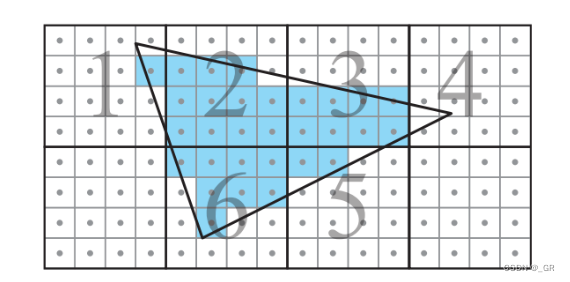
这里使用Tile遍历的原因是为了提高cache的命中率更高效的重复利用pixel信息,因为扫描便利三角形的时候会对使用过的pixel值进行缓存,但是由于cache容量有限,因此只有少量pixel会被存储,扫描线通常是不连贯的,其扫描到尾部的时候大概率是用不到开头缓存的pixel的,而通常Tile内三角形的覆盖率会非常高,这样Tile内的线程大概率可以复用到之前的信息。
Coarse Raster
Coarse Raster也叫粗光栅化,以8×8个pixel为单位进行光栅化,这里会对分层遍历加速后的结果进行分组遍历,每个Tile只写入其内部三角形的Zmax和Zmin,相当于在为原始尺寸的1/8的FrameBuffer上做了一次光栅化,目的是配合后HiZ单元的coarse depth test快速的剔除一遍像素。
HiZ uint
这个也即是Z-Cull单元,通常会对上一步Coarse Raster得到的光栅化结果进行两种不同的深度测试
- Zmax测试
Zmax存储8×8Tile内的最大深度,这个Zmax值可以从HiZ cache缓存快速获取到,通常由Tile内三角形深度直接写入或从后面步骤得到深度后回读回来。首先计算这个Tile内的三角形的最小值Ztrimin,如果Ztrimin>Zmax,则说明三角形一定被Tile内先前渲染的几何物体遮挡,因此停止对Tile内三角形的后续处理,不会进行后续的Fine Raster。
- Zmin测试
Zmin存储8×8Tile内的最小深度,这个Zmax值同样可以从HiZ cache缓存快速获取到,写入方式和Zmax类似,如果Tile内的三角形的Ztrimax<Zmin,则说明该三角形一定位于被Tile先前渲染的几何物体前面,所以后续就不需要逐pixel做深度测试了,直接渲染即可,这样可以省去读深zbuffer的开销。
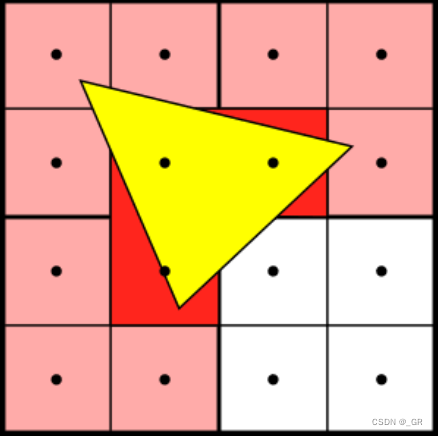
Fine Raster
Fine Raster即为更细粒度的光栅化,以2×2个像素为单位进行,这是因为通常Pixel Shader需要用pixel之间的梯度计算mip层级,所以硬件光栅化输出的Quad(2×2)会附带这些信息。如下图尽管只有中间三个像素在三角形内还是得输出4×3个pixel。
- 局限性
Z-Cull通常只在TBR架构上的硬件可以启用。
Z-Cull做模板测试的时候需要对齐Tile,一个Tile内同时出现两种模板(镂空现象)的时候Z-Cull就会失效,会多了一个查询stencil的过程而浪费性能。
Coarse Raster的目的就是为了减少大三角形逐像素读取深度作比较的次数和快速的剔除掉被遮挡的三角形,这就意味着Coarse Raster对小三角形或者是狭长三角形(覆盖不到任何像素的三角形)几乎是无用的,甚至这些多出的流程会成为负担。
Fine Raster在绘制小三角形的时候也会造成输出无用的pixel的浪费。
Early Z&Pre-Z
Early-Z和Pre-Z的本质区别就是Early-Z不需要额外的Draw Call,而Pre-Z则是要多一倍的Draw Call去拿到深度。
| DrawCall | Overdraw | |
|---|---|---|
| Early-Z | 1x | 1~nx |
| Pre-Z | 2x | 1x |
Early-Z
Early-Z为提前深度测试,把深度测试提前到Pixel Shading之前,没通过提前深度测试的Pixel就不执行后续的shading了,这样可以大幅度的减少Overdraw减轻SM上的压力。
由于硬件光栅化要计算梯度,所以Pixel是以Quad(2×2)的形式去做Early-Z的
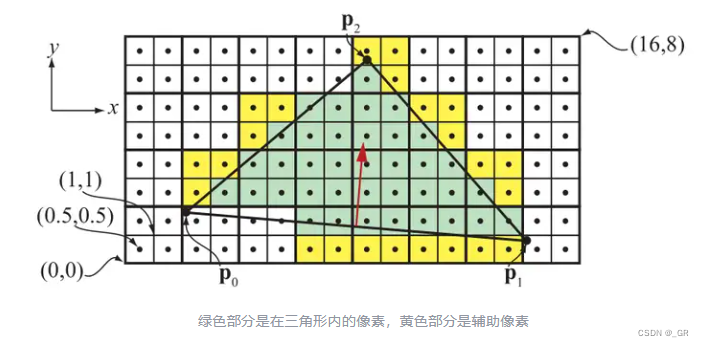
对于同一个Pixel来说,第一次提前深度测试时深度图没有值,所以先正常做一次shading拿到该Pixel的第一个深度,第二次提前深度测试则是把插值的最新Pixel深度和深度图里的深度对比,如果最新深度要比深度图的深度浅,写入深度且做一次shading,否则直接剔除掉。
- 局限性
开启alpha test、在Pixel Shader写入深度或者discard pixel等操作都会使Early-Z失效,因为Early-Z用来做深度测试判断的深度是光栅化插值处理的原始深度,alpha test等操作都有可能导致原始深度在片元阶段与late-z阶段之间被修改,这就会导致提前深度测试结果不正确。
如果是从后往前渲染的,每次深度测试都会成功,每个Pixel也都会进行shading,Overdraw次数会非常多,Erarly-Z就会起不到任何效果。最好的情况从前往后渲染,第一次渲染的深度即是最终深度,后面的Pixel就不需要shading了,这样只需要1x倍Pixel的shading次数就能得到最终结果,但这需要先在CPU端对物体进行排序,当场景复杂到了一定程度了,频繁的排序会占用大量CPU资源。
Pre-Z
Pre-Z即提前进行一次代价很小的渲染,这次渲染不做shading只写入深度,有了Pre-Z的深度图就可以用这个深度图去做提前深度测试了,这样虽然会导致DrawCall数量翻倍但是配合Early-Z使用能确保下一个Pass的shading数量和屏幕空间的Pixel数量是一致的,并不会带来多余的shading浪费。
Pre-Z主要功耗产生在DrawCall,但却能保证只有1x倍Pixel的shading,相当于用更多的Draw Call去节省Overdraw的时间
- 局限性
Pre-Z虽然只写入深度不做shading计算,可以缓解大量的SM压力,但在移动端,功耗的瓶颈在于Draw Call数量,这个时候需要综合考虑是否需要使用Pre-Z以及对Pre-Z做一些额外出来等操作来评估是否值得用double draw call去减少shading次数。
裁剪剔除
裁剪剔除在几何处理阶段屏幕映射前进行,粒度是三角形,也叫视锥体剔除。
只有完全位于可视空间额内部的图元才需要被发送给光栅化阶段,因此在几何阶段对粗粒度的物体做基于三角形图元的剔除可以有效的减少无效shading的次数。
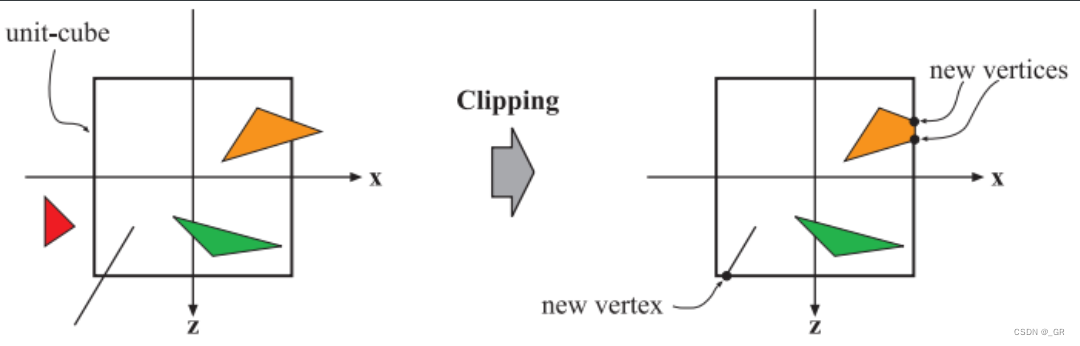
裁剪剔除发生在裁剪空间,裁剪完后通过透视除法转换到NDC空间。裁剪空间是顶点乘以MVP矩阵之后所在的空间,Vertex Shader的输出就是在裁剪空间上的。
由于投影后的三角形并不是线性的,所以需要用四维的齐次坐标以便进行正确的插值和裁剪。
背面剔除
背面剔除发生在屏幕映射之后光栅化阶段之前,其剔除粒度是三角形,目的是剔除掉背对摄像机的三角形,被剔除掉的三角形不再参与后续的三角形设置等流程。背面剔除算法主要分两种,screen spcae剔除和view space剔除。
- screen space剔除
该方法通过判断屏幕空间里三角形三个顶点环绕顺序是否同为顺时针或逆时针来确定是否背对屏幕,这个测试可以通过叉乘判断正负的方法来实现。

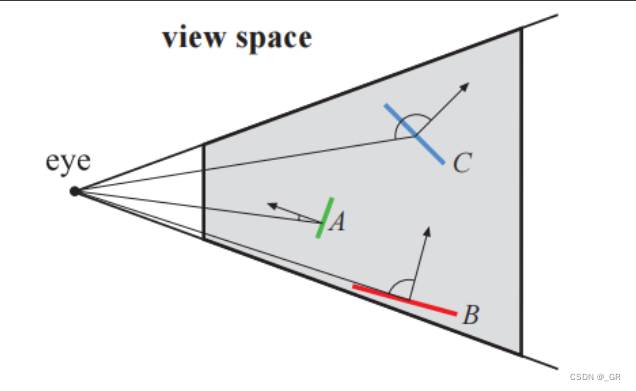
- view space剔除
该方法通过判断观察空间中视点和三角形的法线夹角是否为锐角来确定是否背对观察者,主要通过还原观察空间坐标点乘来实现。
- 局限性
标准的背面剔除并不是一定能带来优化的,因为背面剔除算法本身就需要一定的计算量,如果遇到一些比较特殊的模型如墙面、地板和天花板等模型,大部分的面片都是面向观察者的,这种情况背面剔除带来的提升很可能被算法本身的计算量磨平。一般背面剔除用在丘陵或者峡谷等地面起伏较大会出现较多背面三角形的场景收益会比较大。
集群背面剔除
标准的背面剔除算法是针对单个三角形的,也就是每个三角形都需要做一遍计算来判断是否背对屏幕,集群背面剔除可以先通过生成一个三角形几何,只做一次判断来决定是否要剔除掉整个三角形集合。
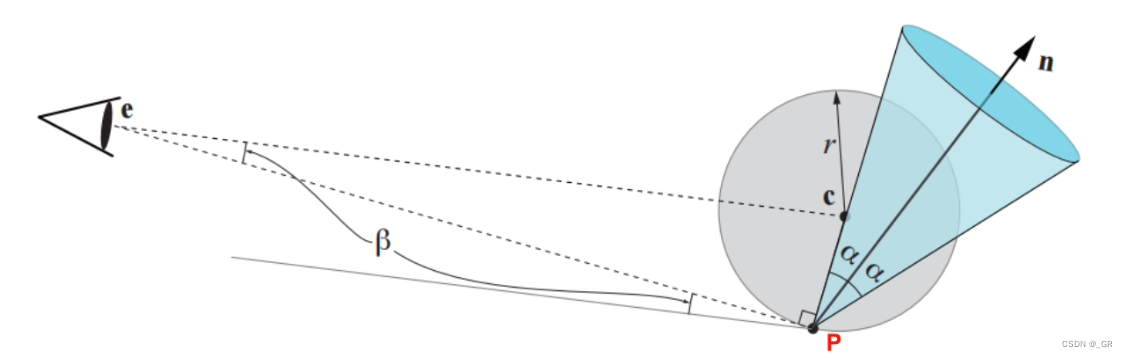
该方法通常用法线锥的形式去做剔除,法线锥包裹了整个三角形集合且包含了所有法线方向,法线锥由法线\(n\)、半角\(a\)、锚点\(c\)以及沿法线截断圆锥体的偏移距离所定义。如果观察者位于正面锥体中,那么锥体中的所有面都是正面的,对于背面锥体也是如此。
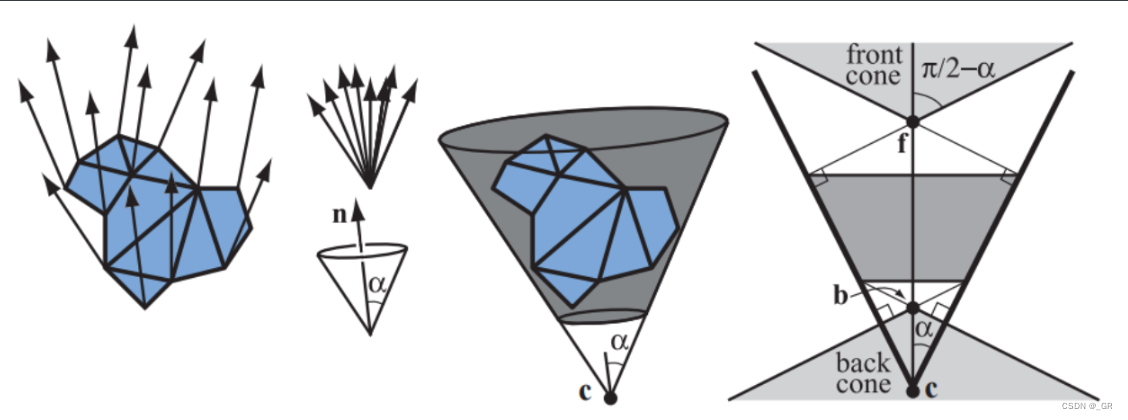
具体的法线锥算法其实不需要上面的截断距离,具体思路就是定义一个圆形包围盒,确定三角形集合都在这个圆包围盒内,把所有三角形移动去到圆心\(c\)点,在单位球面上计算一个包含所有法线的最小圆来算锥体的\(a\)值,如果下面的公式成立则证明法线锥背对视点\(e\)
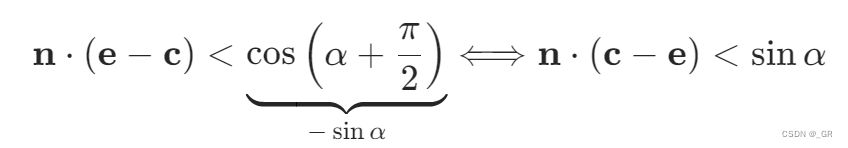
如果只考虑上面的情况是不合理的,因为三角形不可能全都在\(c\)点,如果三角形在靠近包围盒边缘的地方,这其实会导致整个锥体发生变形,也就是把所有三角形都移动到\(c\)点算出的锥体其实并不是保守的,会有可能剔除掉不该剔除的三角形集合,所以引入下面的公式,满足该公式才能说明法线锥背对视点\(e\)
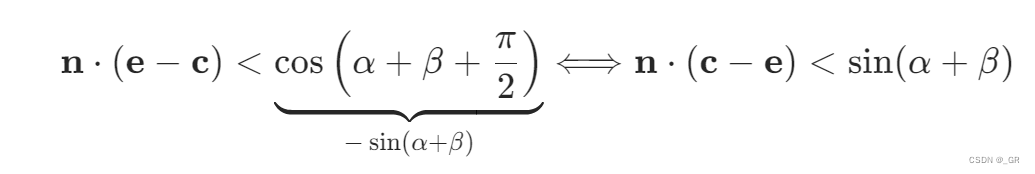
下面的图展示了上面的特殊情况,如果只考虑\(c\)点,全部三角形全部移动到c点算出的法线锥与视点\(e\)的夹角明显大于\(a+\pi/2\),也就是背对视点,但是如果出现三角形在下方P点,P点与视点\(e\)的连线正巧圆包围盒的切线(极限情况),这时候法线锥和视点的夹角等于\(a+\pi/2\),这种情况其实是不能剔除的,所以必须满足上面的公式才行。
预烘焙的聚类立方体剔除
对于每个静态的cluster(包含64个三角形),可以用预处理的方式先计算一个最小立方体,每个立方体面有n×n个像素,每个像素存储64位数据分别对应这64个三角形是否背对视角。

从立方体中心为出发点,以立方体上像素的大小为切面构造一个锥体,该像素上存储的64位数据则代表了当摄像机位于该视锥体内的时候对内部三角形的可视情况。判断三角形是否背对视锥内相机采用下图的判断方式,三角面片的切面是否和锥体有相交,若有则面向观察点,否则剔除。如果观察点位于该立方体内部则所有三角形都视为可见。
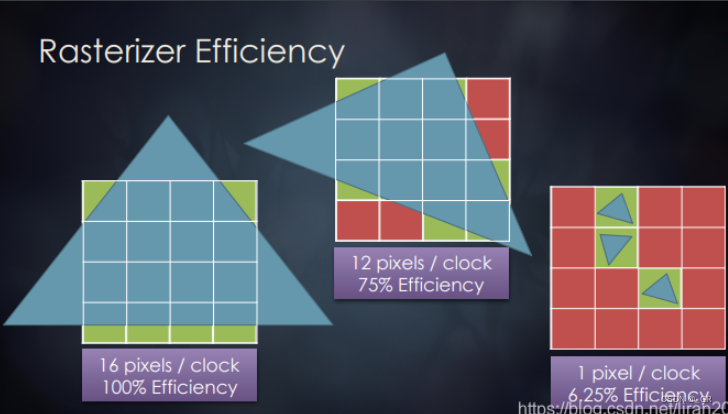
小三角形剔除
小三角形剔除通常用于剔除落在两个像素中心相邻样本之间的微小三角形的,该三角形小到无法命中任何一个光栅化的中心点,理论上来说就不会对pixel产生影响,但是如果该三角形存在还是得走光栅化流程,一般光栅化是按Tile进行,每个三角形每个时钟周期可光栅化16个pixel,三角形覆盖的像素越低,光栅化的性能越低,并行计算的时代,不用就是浪费。我们能提前知道这些三角形是需要剔除的就不需要进入后续的三角形遍历流程,因此小三角形剔除能使光栅化性能得到不少提升。
假如三角形命中了像素的中心,则此三角形一定满足其包围盒上下或者左右的点四舍五入后不同,假设像素中心是0.5,假如小三角形覆盖了这个中心,则其包围盒四舍五入后一定存在一个1一个0,不可能出现两个1或者两个0的情况。所以只需要提前执行下面的公式进行判断就可以剔除掉对Pixel没有影响的三角形。
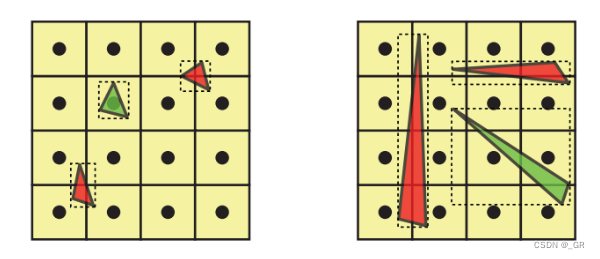
这边的min和max分别对应包围盒的左上和右下边(左上角为0点)。
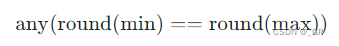
预计算遮挡剔除[TODO]
细节剔除
细节剔除是一种为了渲染速度而牺牲质量的技术,当观察者在运动的状态时,人眼是很难留意到场景中十分微小的细节的,所以在人物移动的时候会开启细节剔除把微小的物体直接剔除掉,在静止的时候再禁用细节剔除。
细节剔除的主要思路是把物体的包围盒投影到投影屏幕,以像素为单位去评估投影的面积,如果投影面积小于某个阈值说明这个物体是细节物体,在运动的时候无需显示。
参考文章
【2016】Masked Software Occlusion Culling - ACM SIGGRAPH Symposium on High Performance Graphics
Masked Software Occlusion Culling
剔除:从软件到硬件
现代渲染引擎开发-GPU Driven Render Pipeline
KillerAery博客
RTR4 Chapter 19 Acceleration Algorithms 加速算法
RTR4 Chapter 23 Graphics Hardware 图形硬件
为什么要剔除小三角形?
游戏优化性能杂谈(十一)
深入剖析GPU Early Z优化
渲染杂谈:early-z、z-culling、hi-z、z-perpass到底是什么?
图形学硬件拾遗(一)
【理论】遮挡剔除与层次Z缓冲(上)——原理篇
大世界技术浅析——超远视距与剔除(3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号