ChatGLM3-6B 对话预训练模型
该文章介绍如何在 GpuMall 平台使用已集成的 ChatGLM3-6B 模型。
立即免费体验:https://gpumall.com/login?type=register&source=cnblogs
- 选择 ChatGLM3-6B 镜像创建实例
提示
训练 ChatGLM3-6B 模型,显卡显存建议选择等于大于 16GB 以上的显卡,因为 ChatGLM3-6B 模型载入后会占用大约 13GB 左右显卡显存。
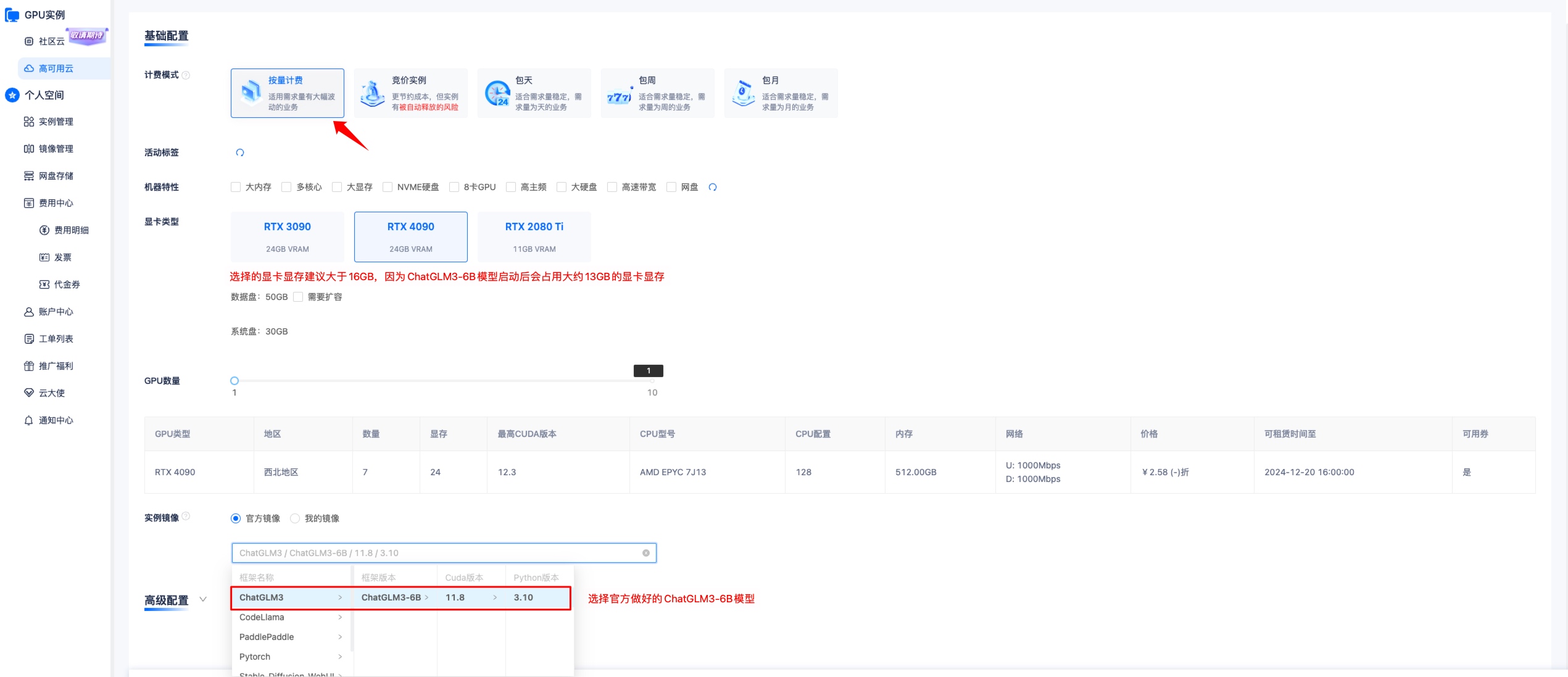
选择完成后创建实例,然后点击 JupyterLab,进入终端。#autodl#恒源云#矩池云#算力云#恒源云 实例迁移#autodl 官网#autodi#GpuMall#GPU云#AutoDL#AotuDL 算力云#GpuMall智算云#AI#大数据#算力租赁#大模型#深度学习#人工智能#算力变现

- 复制 ChatGLM3-6B 模型到实例数据盘
1.ChatGLM3-6B 模型大小为 24G,可以通过如下命令统计,复制到数据盘前,请先确认数据盘空间是否大于 24G
统计ChatGLM3-6B整个模型目录大小
du -sh /gm-models/ChatGLM3-6B/
查看实例数据盘可用空间
df -hT | grep -w gm-data | awk '{print $5}'
chatglm3_002_image
2.使用以下命令复制模型到实例数据盘
复制模型到实例数据盘,注意目标名称全小写
cp -rf /gm-models/ChatGLM3-6B /gm-data/chatglm3-6b
查看已复制到数据盘的ChatGLM3-6B模型
ls -lrht /gm-data/chatglm3-6b

通过上述操作模型会存储在 /gm-data/chatglm3-6b 目录下,不建议移动,ChatGLM3-6B 代码中已指定模型路径为 /gm-data/chatglm3-6b。
- 启动 ChatLM3-6B
ChatGLM3-6B 支持如下几种启动方式:
查看虚拟环境
conda info -e
conda environments:
base /usr/local/miniconda3
ChatGLM3 /usr/local/miniconda3/envs/ChatGLM3
切换到 ChatGLM3虚拟环境
conda activate ChatGLM3
执行启动脚本会打印支持的几种启动方式
/root/ChatGLM3/start.sh
支持如下几种启动方式,根据您需要选择一种启动方式即可:
方式一): Web 网页版对话,通过 Gradio 所生成的地址进行公网访问(国内网络访问可能稍慢),监听8501端口
/root/ChatGLM3/start.sh web_gradio
方式二): Web 网页版对话,通过 GpuMall 平台自定义服务方式进行公网访问,监听8501端口
/root/ChatGLM3/start.sh web_streamlit
方式三): 命令行对话,该选项可在命令行与 ChatGLM3-6B 进行交互对话
/root/ChatGLM3/start.sh terminal
方式四): API 接口方式启动,对该接口进行调用,调用地址通过 GpuMall 平台自定义服务方式所提供的公网地址进行调用
/root/ChatGLM3/start.sh openapi
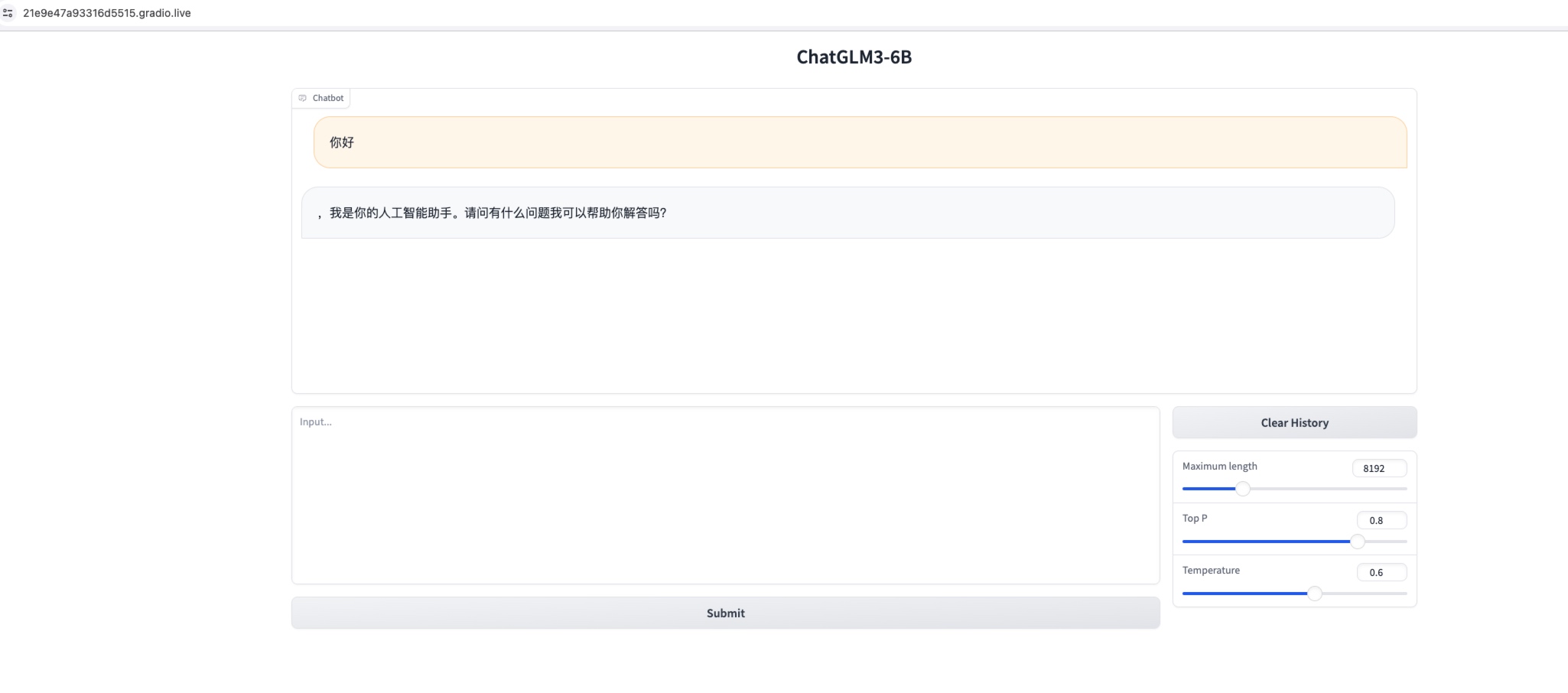
下面会依此演示以上四种启动和通过外网访问方式,根据自己需求选择任意一种即可(通过 API 调用访问方式用的较多)。
3.1 通过Gradio启动
通过 Gradio 方式启动,Gradio 会自动创建一个公网访问链接。
/root/ChatGLM3/start.sh web_gradio
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.66it/s]
Running on local URL: http://127.0.0.1:8501
Running on public URL: https://21e9e47a93316d5515.gradio.live #复制该链接,该链接为Gradio自动生成的公网访问地址,有效期是72个小时
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run gradio deploy from Terminal to deploy to Spaces (https://huggingface.co/spaces)
复制上述链接到浏览器进行访问使用
3.2 网页版启动
启动网页版,然后通过 GpuMall 平台的自定义服务进行访问
/root/ChatGLM3/start.sh web_streamlit
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
Network URL: http://172.17.0.2:8501
External URL: http://61.243.114.254:8501
启动后到 GpuMall 实例管理控制台,点击更多——》创建自定义端口。
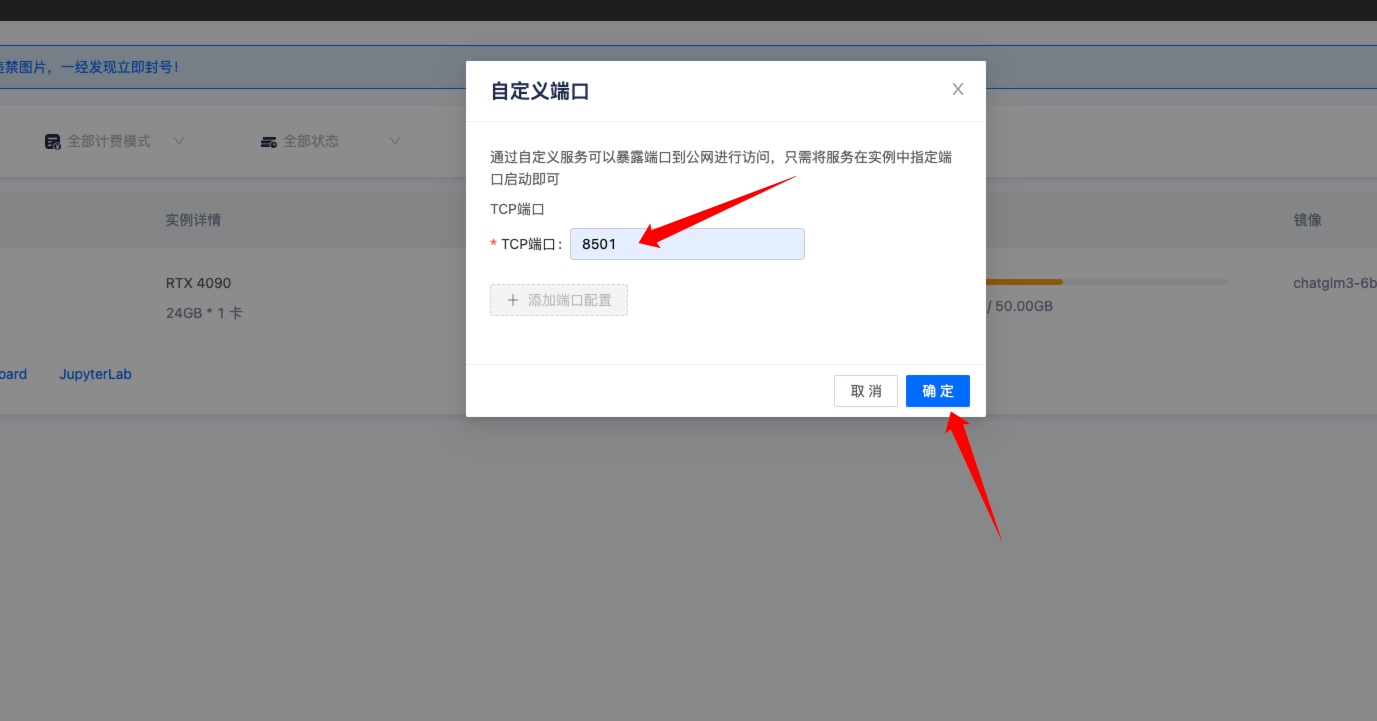
输入 8501,因为实例中的 ChatGLM3-6B 项目监听 8501 端口,然后点击确定。
然后点击 自定义服务 跳转到公网访问网页页面地址。

跳转后开始使用 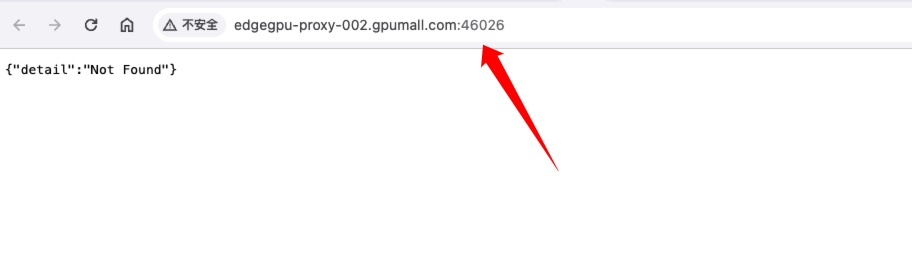
3.3 命令行对话
/root/ChatGLM3/start.sh terminal
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.65it/s]
欢迎使用 ChatGLM3-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序
用户:你好 #输入 文本内容
ChatGLM:你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
用户:stop
3.4 API接口方式启动
执行如下命令启动 API 方式 ChatGLM3-6B 模型,启动后默认监听 8000 端口
/root/ChatGLM3/start.sh openapi
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:03<00:00, 1.85it/s]
INFO: Started server process [361]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
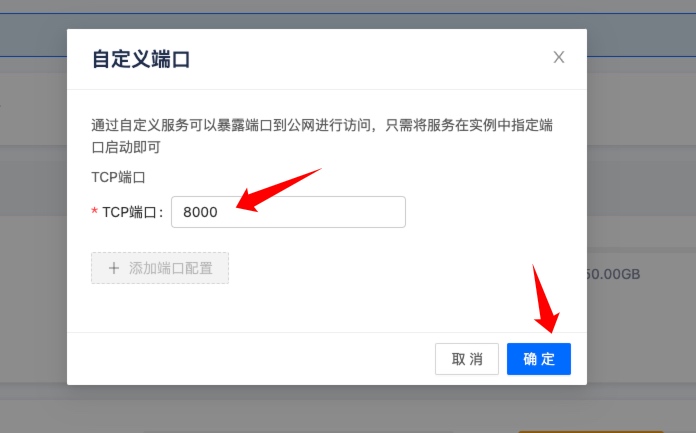
启动后到 GpuMall 实例管理控制台,点击更多——》创建自定义端口。
输入 8000,因为实例中的 ChatGLM3-6B 项目监听 8000 端口,然后点击确定。
然后点击 【自定义端口】 来获取公网调用 API 地址
跳转后浏览器中的 URL 地址就是 API 的公网地址。

通过公网 API 地址进行调用
如下演示三种方式进行调用 curl、postman、python代码。
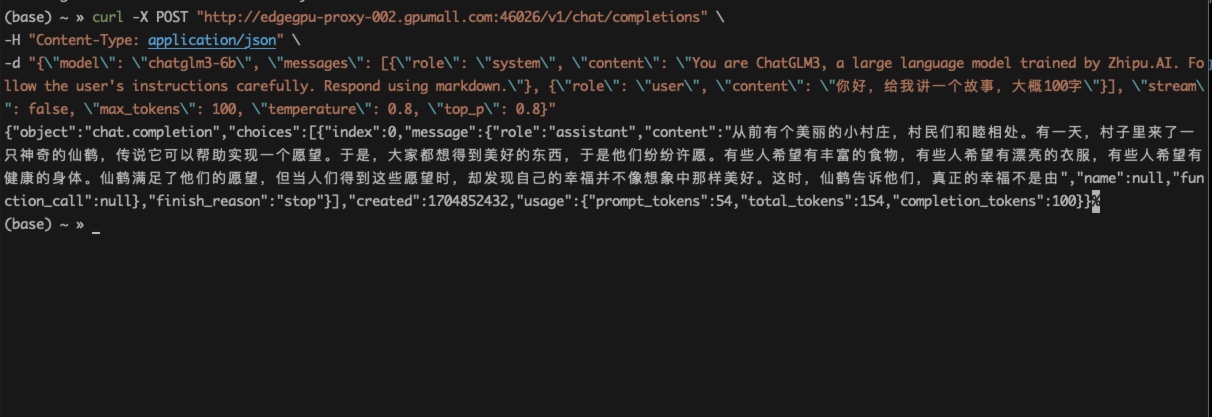
curl 方式调用 ChatGLM3-6B API
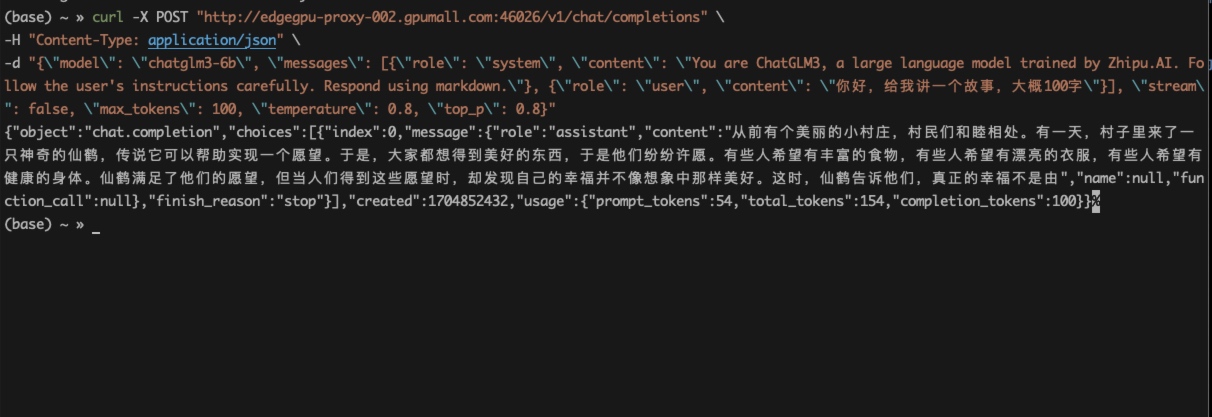
curl -X POST "http://edgegpu-proxy-002.gpumall.com:46026/v1/chat/completions"
-H "Content-Type: application/json"
-d "{"model": "chatglm3-6b", "messages": [{"role": "system", "content": "You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown."}, {"role": "user", "content": "你好,给我讲一个故事,大概100字"}], "stream": false, "max_tokens": 100, "temperature": 0.8, "top_p": 0.8}"
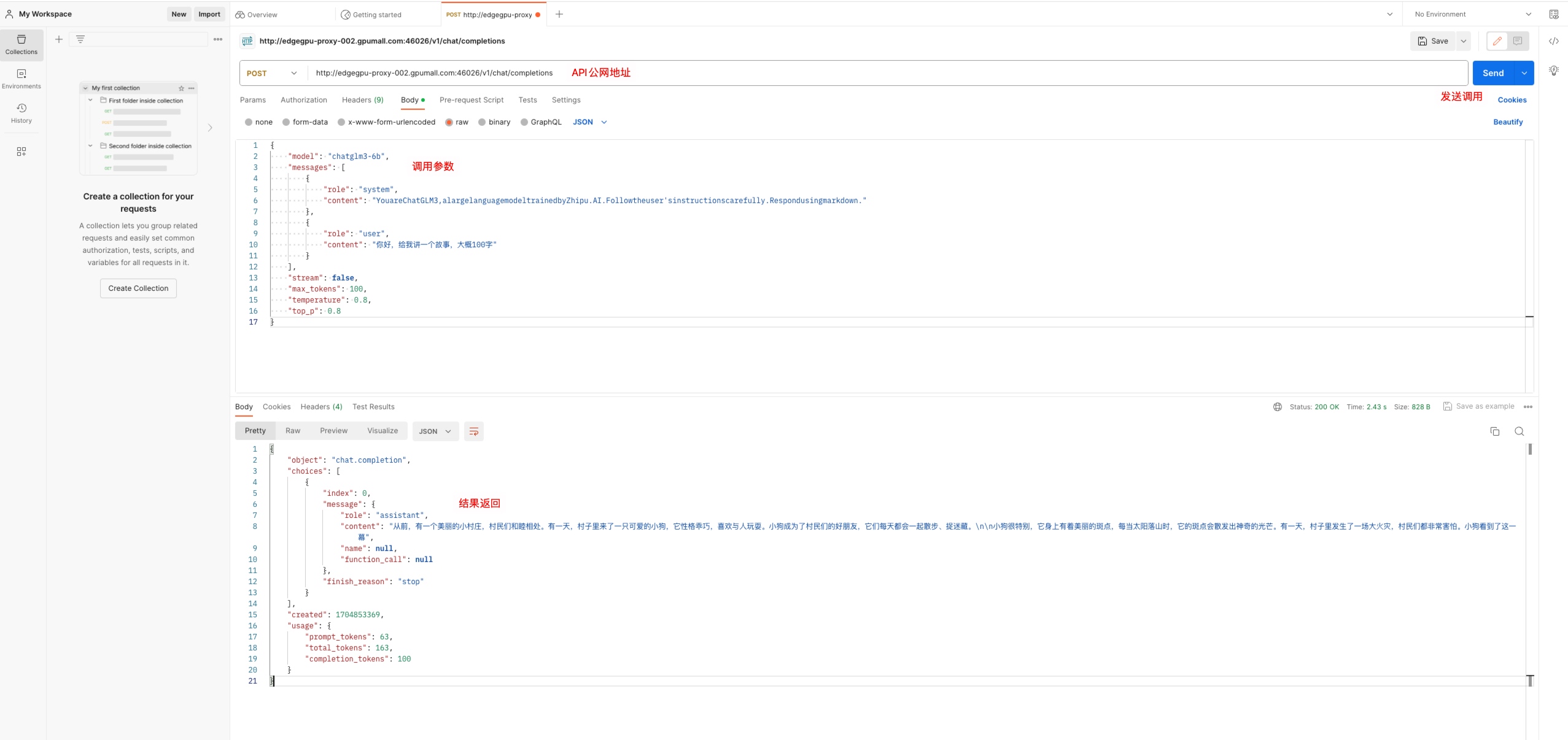
Postman 方式调用
调用参数
{
"model": "chatglm3-6b",
"messages": [
{
"role": "system",
"content": "YouareChatGLM3,alargelanguagemodeltrainedbyZhipu.AI.Followtheuser'sinstructionscarefully.Respondusingmarkdown."
},
{
"role": "user",
"content": "你好,给我讲一个故事,大概100字"
}
],
"stream": false,
"max_tokens": 100,
"temperature": 0.8,
"top_p": 0.8
}
Python代码调用 ChatGLM3-6B API
如下Python调用测试代码在 ChatGLM3-6B官方GitHub仓库
展示Python调用 ChatGLM3-6B API 代码
需要在 Python 代码所在的机器上安装 openai 包,然后执行。
安装openai包
pip install openai
将上述代码保存为 chatglm3-6b-api-request.py 文件,然后执行
python chatglm3-6b-api-request.py
当然可以!那么,让我给您讲一个关于友谊和勇气的小故事。
从前,在一个遥远的国度里,住着两个好朋友:小明和小红。他们俩从小一起长大,无论遇到什么困难,都会互相帮助、扶持。他们的友谊感动了很多人,也成为了村庄中一段美好的传说。
有一天,村子里来了一个恶龙。它经常袭击村子,抢走人们的财物,威胁村民的生命安全。面对这个强大的恶龙,小明和小红都非常害怕,但他们并没有退缩。他们决定勇敢地对抗恶龙,保护自己的家园。
为了准备与恶龙战斗,小明和小红去向村里的智者请教。智者告诉他们,要战胜恶龙,需要找到它的弱点。经过一番调查和思考,他们终于找到了恶龙的弱点:它的眼睛非常脆弱,只要用尖锐的物品刺中它的眼睛,就能让它失去力量。
于是,小明和小红拿起锐利的武器,勇敢地向恶龙发起了攻击。在激战中,他们不断地用尖锐的物品刺中恶龙的眼睛,最终成功地打败了它。村子恢复了宁静,人们为他们的勇敢和智慧感到自豪。
从此以后,小明和小红的名字传遍

 浙公网安备 33010602011771号
浙公网安备 33010602011771号