机器学习之决策树
理解决策树原理
决策树是一种基本的分类方法,从编程语言的角度理解决策树其实就是很多个if....else...组成的条件筛选,如果满足给出的第一个条件就进入下一个条件筛选,如果不满足就退出来.... 类似下面这样图:(图片来自于:https://zhuanlan.zhihu.com/p/30059442)
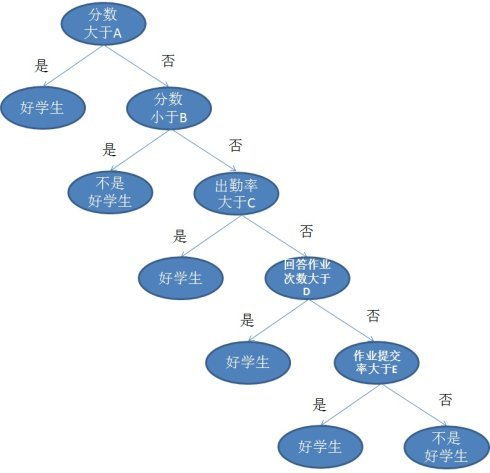
那么问题来了,如何决定各个条件的先后顺序呢。比如上图中为什么先判断分数再判断作业提交次数呢?
这里,涉及到一个名词叫做:信息增益
- 那么信息增益表示得知特征X的信息而是的类Y的信息的不确定性减少的程度,所以我们对于选择特征进行分类的时候,当然选择信息增益较大的特征,这样具有较强的分类能力。特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即公式为:g(D,A)=H(D)−H(D∣A)
- 根据信息增益的准则的特征选择方法是:对于训练数据集D,计算其每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征
信息增益的计算:

举个例子计算一下:
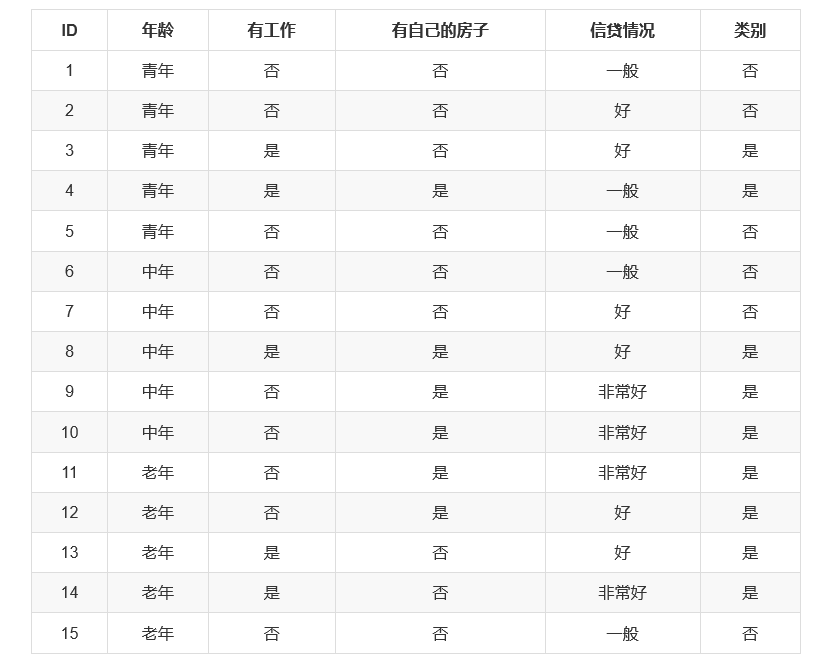

因此在决策树中,A3被放在第一个节点上,A4被放在第二个,A2被放在第三个。
API:sklearn.tree.DecisionTreeClassifier

举个例子,如何用决策树来预测当年著名的泰坦尼克号沉船事件中游客们的存活。
首先数据集: http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

上代码:
1 import pandas as pd 2 from sklearn.feature_extraction import DictVectorizer 3 from sklearn.tree import DecisionTreeClassifier 4 from sklearn.model_selection import train_test_split 5 from sklearn.tree import export_graphviz 6 7 8 #pd.set_option('display.max_columns',15) 9 def decision(): 10 ''' 11 决策树对泰坦尼克号进行预测 12 :return: None 13 ''' 14 15 #获取数据 16 titian = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt') 17 18 #数据处理,找出特征值和目标值 19 x = titian[['pclass','age','sex']] 20 y = titian['survived'] 21 22 #缺失值处理 23 x['age'].fillna(x['age'].mean(), inplace=True) 24 25 #分割数据集到训练集和测试集 26 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25) 27 28 #进行处理(特征工程) 特征 -》类别 -》 one_hot编码 29 dict = DictVectorizer(sparse=False) 30 x_train= dict.fit_transform(x_train.to_dict(orient='records')) 31 print(dict.get_feature_names()) 32 33 x_test = dict.transform(x_test.to_dict(orient='records')) 34 print(x_train) 35 36 #用决策树进行预测 37 dec = DecisionTreeClassifier() #默认基尼系数算法 38 dec.fit(x_train, y_train) 39 40 #预测准确率 41 print('预测的准确率:',dec.score(x_test, y_test)) 42 43 #导出决策树的结构 44 export_graphviz(dec, out_file='./tree.dot', feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'female', 'male']) 45 46 return None 47 48 if __name__ == '__main__': 49 decision()
结果如下:

将决策树可视化如下图所示:
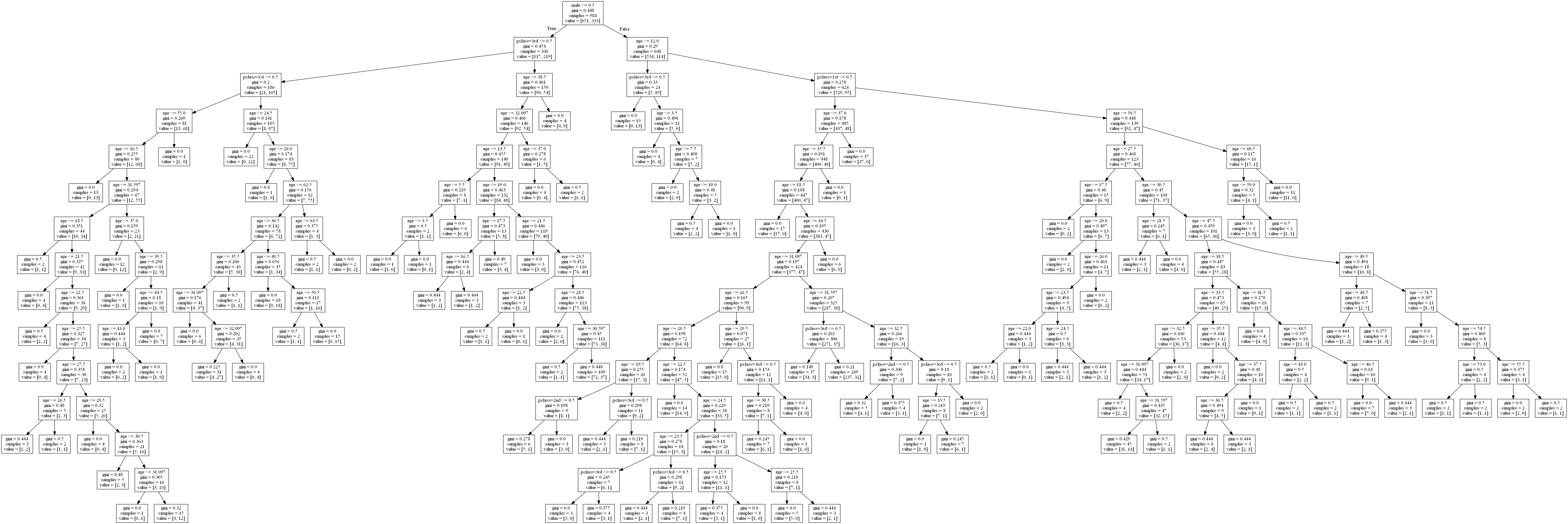
局部放大一下:

决策树的一些优点是:
- 简单的理解和解释。树木可视化。
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量,并删除空值。但请注意,此模块不支持缺少值。
- 使用树的成本(即,预测数据)在用于训练树的数据点的数量上是对数的。
决策树的缺点包括:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树。这被称为过拟合。修剪(目前不支持)的机制,设置叶节点所需的最小采样数或设置树的最大深度是避免此问题的必要条件。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。通过使用合奏中的决策树来减轻这个问题。
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号