机器学习之交叉验证和网格搜索
交叉验证
将拿到的训练数据,分为训练集和验证机。以下图为例:将训练数据分为4份,其中一份作为验证集,。然后经过5次的测试,每次都更换不同的验证机,
最后得到5组模型的结果。最后取平均值作为最后的结果。这也称为4折交叉验证。

网格搜索(超参数搜索):
通常情况下,有很多参数是需要手动指定的(如K-近邻算法中的K值),这种教超参数。但是手动过程繁杂,所提需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
作用:调参数。
API:sklearn.model_selection.GridSearchCV

以K-近邻那篇文章的例子进行修改,代码如下:
1 from sklearn.model_selection import GridSearchCV 2 from sklearn.datasets import load_iris 3 from sklearn.model_selection import train_test_split 4 from sklearn.preprocessing import StandardScaler 5 from sklearn.neighbors import KNeighborsClassifier 6 7 def knn(): 8 """ 9 鸢尾花分类 10 :return: None 11 """ 12 13 # 数据集获取和分割 14 lr = load_iris() 15 16 #标准化 17 std = StandardScaler() 18 x = std.fit_transform(lr.data) 19 20 x_train, x_test, y_train, y_test = train_test_split(x, lr.target, test_size=0.25) 21 22 # estimator流程 23 knn = KNeighborsClassifier() 24 25 #构造一些参数的值进行搜索 26 param = {'n_neighbors': [3,5,10]} 27 28 #j进行网格搜索 29 gc = GridSearchCV(knn,param_grid = param, cv = 10) 30 31 gc.fit(x_train,y_train) 32 33 #预测准确率 34 print('再测试集上的准确率:',gc.score(x_test,y_test)) 35 print('再交叉验证中最好的结果:',gc.best_score_) 36 print('选择的最好的模型是:',gc.best_estimator_) 37 print('每个超参数每次交叉验证的结果',gc.cv_results_) 38 39 return None 40 41 if __name__ == "__main__": 42 knn()
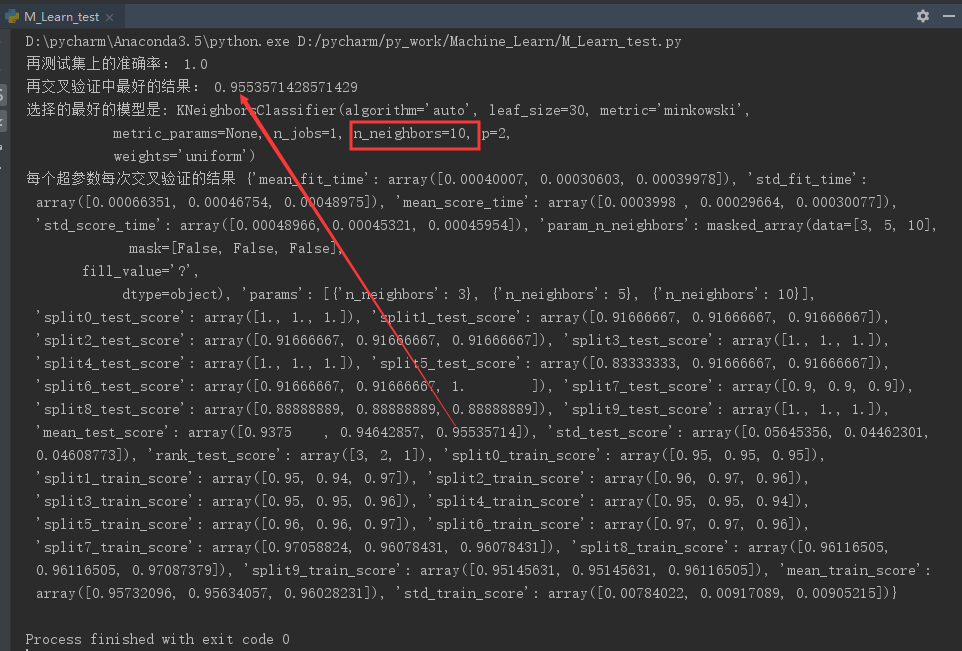
可以看到结果,在K=10的时候,10折交叉验证的结果最好,准确率达到了95.5%。比单用K-邻近法的94%稍微高一些。
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号