机器学习之混淆矩阵
再分类任务下,预测结果和真实情况之间存在四种不同的组合,这四种组合构成了混淆矩阵。
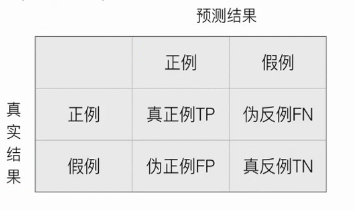
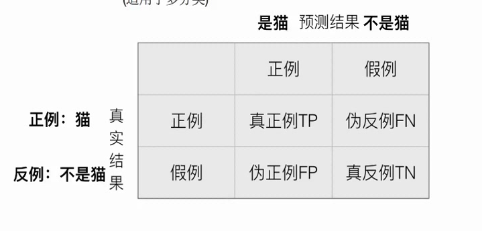
举个例子,看下图。当真实情况是猫,预测结果也是猫的时候,这个时候定义为真正例;当真实情况是猫,而预测结果不是猫的时候定义为伪反例子;
当真实情况不是猫,而预测结果是猫时定义为伪正例;当真实情况不是猫预测结果也不是猫时定义为真反例。这个矩阵就叫做混淆矩阵。
再来看与之相关的两个评估标准:精确率与召回率。

精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
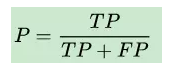
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。也就是:
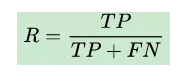
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号