机器学习之朴素贝叶斯算法
学习这个算法前,得知道一些概率论上面得知识。
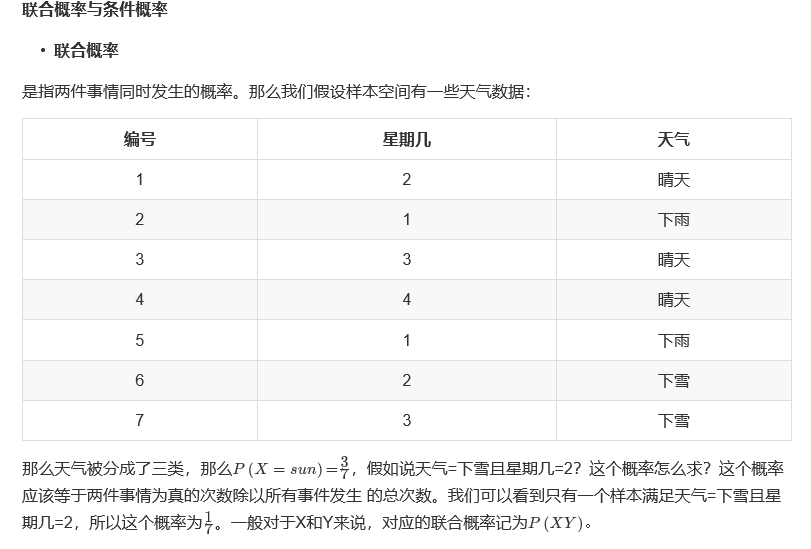


因此,使用朴素贝叶斯算法前,首先需要保证各个特征之间要保持相互独立。
API:sklearn.naive_bayes.MultinomialNB

alpha时拉普拉斯平滑系数,默认为1。其作用时防止分类得时候类别为0时导致统计结果为0。

上个例子:
读取20类新闻文本,并且将这些新闻文本划分为测试集和训练集,预测测试集的分类。
上代码:
1 from sklearn.datasets import fetch_20newsgroups 2 from sklearn.feature_extraction.text import TfidfVectorizer 3 from sklearn.naive_bayes import MultinomialNB 4 from sklearn.model_selection import train_test_split 5 6 def naviebayes(): 7 ''' 8 朴素贝叶斯进行文本分类 9 :return: 10 ''' 11 12 #加载数据集 13 news = fetch_20newsgroups(subset='all') 14 15 #将数据分割为训练集和测试集 16 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25) 17 18 #对数据集进行特征抽取 使用TF-IDF方法 19 tf = TfidfVectorizer() 20 21 #以训练集当中的词的列表进行每篇文章重要性统计 22 x_train = tf.fit_transform(x_train) 23 print(tf.get_feature_names()) 24 25 x_test = tf.transform(x_test) 26 27 #进行朴素贝叶斯算法的预测 28 mlt = MultinomialNB(alpha=1.0) 29 print(x_train.toarray()) 30 mlt.fit(x_train,y_train) 31 32 y_predict = mlt.predict(x_test) 33 print('预测的文章类别为:',y_predict) 34 35 #得出准确率 36 print('准确率为:',mlt.score(x_test,y_test)) 37 38 if __name__ == '__main__': 39 naviebayes()
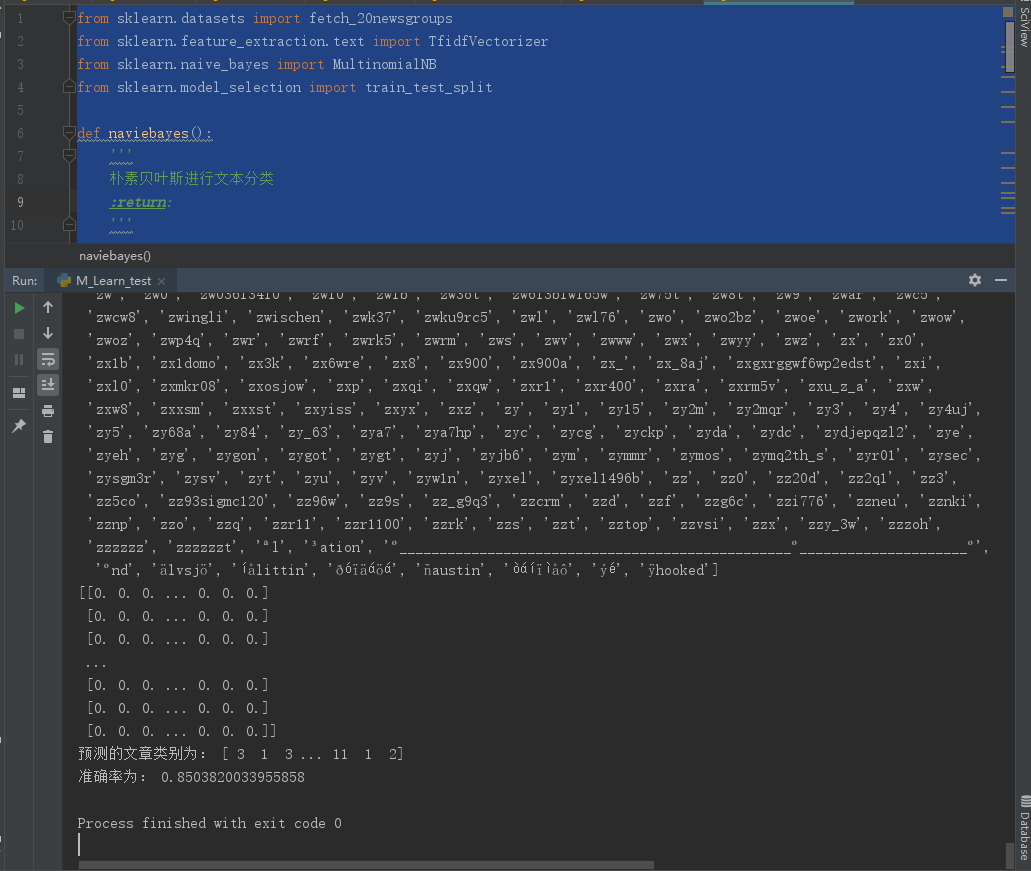
准确度为 85%。还是不错的
通过这个例子,可以得出朴素贝叶斯算法时不需要调参的。
其优点时,分类效率高、算法简单、速度快。
缺点是需要样本特征之间相互独立;因为此算法时不需要调参,所以分类精度一旦计算出来就很难再提高。
--------------------成功,肯定是需要一点一滴积累的--------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号